Das ist eine für den Ausdruck optimierte Ansicht des gesamten Kapitels inkl. Unterseiten. Druckvorgang starten.
Dokumentation
- 1: Kubernetes Dokumentation
- 2: Setup
- 2.1: Kubernetes herunterladen
- 2.1.1: Release erstellen
- 2.2: Kubernetes lokal über Minikube betreiben
- 3: Konzepte
- 3.1: Überblick
- 3.1.1: Was ist Kubernetes?
- 3.1.2: Kubernetes Komponenten
- 3.2: Kubernetes Architektur
- 3.2.1: Nodes
- 3.2.2: Master-Node Kommunikation
- 3.2.3: Zugrunde liegende Konzepte des Cloud Controller Manager
- 3.3: Container
- 3.3.1: Images
- 3.4: Workloads
- 3.4.1: Deployments
- 3.4.2: Pods
- 3.4.3: ReplicaSet
- 3.4.4: Jobs
- 3.5: Dienste, Lastverteilung und Netzwerkfunktionen
- 3.5.1: Services
- 3.5.2: IPv4/IPv6 dual-stack
- 3.6: Speicher
- 3.6.1: Persistente Volumes
- 3.7: Konfiguration
- 3.7.1: Secrets
- 3.7.2: Resourcen-Verwaltung für Pods und Container
- 3.8: Richtlinien
- 3.9: Cluster Administration
- 3.9.1: Proxies in Kubernetes
- 3.9.2: Controller Manager Metriken
- 3.9.3: Addons Installieren
- 3.10: Kubernetes erweitern
- 3.11: Konzept Dokumentations-Vorlage
- 4: Aufgaben
- 4.1: Werkzeuge installieren
- 4.1.1: Installieren und konfigurieren von kubectl
- 4.1.2: Kubectl installieren und konfigurieren auf Linux
- 4.1.3: Kubectl installieren und konfigurieren auf macOS
- 4.1.4: Installation von Minikube
- 4.2: Einen Cluster verwalten
- 4.2.1: Verwaltung mit kubeadm
- 4.3: Pods und Container konfigurieren
- 4.4: Daten in Anwendungen injizieren
- 4.5: Anwendungen ausführen
- 4.5.1: Horizontal Pod Autoscaler
- 4.6: Jobs ausführen
- 4.7: Auf Anwendungen in einem Cluster zugreifen
- 4.8: Überwachung, Protokollierung und Fehlerbehebung
- 4.9: Kubernetes erweitern
- 4.10: TLS
- 4.11: Föderation
- 4.12: Cluster-Daemons verwalten
- 5: Tutorials
- 5.1: Hallo Minikube
- 5.2: Kubernetes Grundlagen lernen
- 5.2.1: Einen Cluster erstellen
- 5.2.1.1: Minikube zum Erstellen eines Clusters verwenden
- 5.2.1.2: Interaktives Lernprogramm - Erstellen eines Clusters
- 5.2.2: Eine App bereitstellen
- 5.2.2.1: Verwenden von kubectl zum Erstellen eines Deployments
- 5.2.2.2: Interaktives Lernprogramm - Bereitstellen einer App
- 5.2.3: Entdecken Sie Ihre App
- 5.2.4: Machen Sie Ihre App öffentlich zugänglich
- 5.2.4.1: Verwendung eines Services zum Veröffentlichen Ihrer App
- 5.2.4.2: Interaktives Lernprogramm - Ihre App öffentlich zugänglich machen
- 5.2.5: Skalieren Sie Ihre App
- 5.2.5.1: Mehrere Instanzen Ihrer App ausführen
- 5.2.5.2: Interaktives Lernprogramm - Skalieren Ihrer App
- 5.2.6: Aktualisieren Sie Ihre App
- 6: Referenzen
- 6.1: Standardisiertes Glossar
- 6.2: Kubernetes Probleme und Sicherheit
- 6.3: Verwendung der Kubernetes-API
- 6.4: API Zugriff
- 6.5: API Referenzinformationen
- 6.6: Föderation API
- 6.7: Setup-Tools Referenzinformationen
- 6.8: Befehlszeilen-Werkzeug Referenzinformationen
- 6.9: kubectl CLI
- 6.9.1: kubectl Spickzettel
- 6.10: Tools
- 7: Zur Kubernetes-Dokumentation beitragen
- 7.1: Lokalisierung der Kubernetes Dokumentation
- 7.2: Bei SIG Docs mitmachen
- 7.2.1: Rollen und Verantwortlichkeiten
- 7.2.2: PR Wranglers
- 8:
- 9: Suchergebnisse
1 - Kubernetes Dokumentation
1.1 - Unterstützte Versionen der Kubernetes-Dokumentation
Diese Website enthält Dokumentation für die aktuelle Version von Kubernetes und die vier vorherigen Versionen von Kubernetes.
Aktuelle Version
Die aktuelle Version ist v1.28.
Vorherige Versionen
2 - Setup
Diese Sektion umfasst verschiedene Optionen zum Einrichten und Betrieb von Kubernetes.
Verschiedene Kubernetes Lösungen haben verschiedene Anforderungen: Einfache Wartung, Sicherheit, Kontrolle, verfügbare Resourcen und erforderliches Fachwissen zum Betrieb und zur Verwaltung. Das folgende Diagramm zeigt die möglichen Abstraktionen eines Kubernetes-Clusters und ob eine Abstraktion selbst verwaltet oder von einem Anbieter verwaltet wird.
Sie können einen Kubernetes-Cluster auf einer lokalen Maschine, Cloud, On-Prem Datacenter bereitstellen; oder wählen Sie einen verwalteten Kubernetes-Cluster. Sie können auch eine individuelle Lösung über eine grosse Auswahl an Cloud Anbietern oder Bare-Metal-Umgebungen nutzen.
Noch einfacher können Sie einen Kubernetes-Cluster in einer Lern- und Produktionsumgebung erstellen.
Lernumgebung
Benutzen Sie eine Docker-basierende Lösung, wenn Sie Kubernetes erlernen wollen: Von der Kubernetes-Community unterstützte Werkzeuge oder Werkzeuge in einem Ökosystem zum Einrichten eines Kubernetes-Clusters auf einer lokalen Maschine.
Produktionsumgebung
Überlegen Sie sich bei der Bewertung einer Lösung für eine Produktionsumgebung, welche Aspekte des Betriebs eines Kubernetes-Clusters (oder von abstractions) Sie selbst verwalten oder an einen Anbieter auslagern möchten.
Einige mögliche Abstraktionen von Kubernetes-Clustern sind applications, data plane, control plane, cluster infrastructure und cluster operations.
Das folgende Diagramm zeigt die möglichen Abstraktionen eines Kubernetes-Clusters und ob eine Abstraktion selbst verwaltet oder von einem Anbieter verwaltet wird.
Lösungen für Produktionsumgebungen
Die folgende Tabelle für Produktionsumgebungs-Lösungen listet Anbieter und deren Lösungen auf.
2.1 - Kubernetes herunterladen
2.1.1 - Release erstellen
Sie können entweder eine Version aus dem Quellcode erstellen oder eine bereits kompilierte Version herunterladen. Wenn Sie nicht vorhaben, Kubernetes selbst zu entwickeln, empfehlen wir die Verwendung eines vorkompilierten Builds der aktuellen Version, die Sie in den Versionshinweisen finden.
Der Kubernetes-Quellcode kann aus dem kubernetes/kubernetes repo der heruntergeladen werden.
Aus dem Quellcode kompilieren
Wenn Sie einfach ein Release aus dem Quellcode erstellen, müssen Sie keine vollständige Golang-Umgebung einrichten, da alle Aktionen in einem Docker-Container stattfinden.
Das Kompilieren einer Version ist einfach:
git clone https://github.com/kubernetes/kubernetes.git
cd kubernetes
make release
Mehr Informationen zum Release-Prozess finden Sie im kubernetes/kubernetes build Verzeichnis.
2.2 - Kubernetes lokal über Minikube betreiben
Minikube ist ein Tool, mit dem Kubernetes lokal einfach ausgeführt werden kann. Minikube führt einen Kubernetes-Cluster mit einem einzigen Node in einer VM auf Ihrem Laptop aus, damit Anwender Kubernetes ausprobieren oder täglich damit entwickeln können.
Minikube-Funktionen
- Minikube unterstützt Kubernetes-Funktionen wie:
- DNS
- NodePorts
- ConfigMaps and Secrets
- Dashboards
- Container Laufzeiumgebungen: Docker, rkt, CRI-O und containerd
- Unterstützung von CNI (Container Network Interface)
- Ingress
Installation
Lesen Sie Minikube installieren für Informationen zur Installation von Minikubes.
Schnellstart
Folgend finden Sie eine kurze Demo zur Verwendung von Minikube.
Wenn Sie den VM-Treiber ändern möchten, fügen Sie das entsprechende --vm-driver=xxx-Flag zu minikube start hinzu.
Minikube unterstützt die folgenden Treiber:
- virtualbox
- vmwarefusion
- kvm2 (Treiber installation)
- kvm (Treiber installation)
- hyperkit (Treiber installation)
- xhyve (Treiber installation) (deprecated)
- hyperv (Treiber installation)
Beachten Sie, dass die unten angegebene IP-Adresse dynamisch ist und sich ändern kann. Sie kann mit
minikube ipabgerufen werden. - none (Führt die Kubernetes-Komponenten auf dem Host und nicht in einer VM aus. Die Verwendung dieses Treibers erfordert Docker (Docker installieren) und eine Linux-Umgebung)
minikube start
Starting local Kubernetes cluster...
Running pre-create checks...
Creating machine...
Starting local Kubernetes cluster...
kubectl create deployment hello-minikube --image=registry.k8s.io/echoserver:1.10
deployment.apps/hello-minikube created
kubectl expose deployment hello-minikube --type=NodePort --port=8080
service/hello-minikube exposed
# Wir haben jetzt einen echoserver Pod gestartet, aber wir müssen warten,
# bis der Pod betriebsbereit ist, bevor wir über den exponierten Dienst auf ihn zugreifen können.
# Um zu überprüfen, ob der Pod läuft, können wir Folgendes verwenden:
kubectl get pod
NAME READY STATUS RESTARTS AGE
hello-minikube-3383150820-vctvh 0/1 ContainerCreating 0 3s
# Wir können anhand des ContainerCreating-Status sehen, dass der Pod immer noch erstellt wird.
kubectl get pod
NAME READY STATUS RESTARTS AGE
hello-minikube-3383150820-vctvh 1/1 Running 0 13s
# Wir können sehen, dass der Pod jetzt läuft und wir können ihn jetzt mit curl kontaktieren:
curl $(minikube service hello-minikube --url)
Hostname: hello-minikube-7c77b68cff-8wdzq
Pod Information:
-no pod information available-
Server values:
server_version=nginx: 1.13.3 - lua: 10008
Request Information:
client_address=172.17.0.1
method=GET
real path=/
query=
request_version=1.1
request_scheme=http
request_uri=http://192.168.99.100:8080/
Request Headers:
accept=*/*
host=192.168.99.100:30674
user-agent=curl/7.47.0
Request Body:
-no body in request-
kubectl delete services hello-minikube
service "hello-minikube" deleted
kubectl delete deployment hello-minikube
deployment.extensions "hello-minikube" deleted
minikube stop
Stopping local Kubernetes cluster...
Stopping "minikube"...
Alternative Containerlaufzeitumgebungen
containerd
Um containerd als Containerlaufzeitumgebung zu verwenden, führen Sie den folgenden Befehl aus:
minikube start \
--network-plugin=cni \
--enable-default-cni \
--container-runtime=containerd \
--bootstrapper=kubeadm
Oder verwenden Sie die erweiterte Version:
minikube start \
--network-plugin=cni \
--enable-default-cni \
--extra-config=kubelet.container-runtime=remote \
--extra-config=kubelet.container-runtime-endpoint=unix:///run/containerd/containerd.sock \
--extra-config=kubelet.image-service-endpoint=unix:///run/containerd/containerd.sock \
--bootstrapper=kubeadm
CRI-O
Um CRI-O als Containerlaufzeitumgebung zu verwenden, führen Sie den folgenden Befehl aus:
minikube start \
--network-plugin=cni \
--enable-default-cni \
--container-runtime=cri-o \
--bootstrapper=kubeadm
Oder verwenden Sie die erweiterte Version:
minikube start \
--network-plugin=cni \
--enable-default-cni \
--extra-config=kubelet.container-runtime=remote \
--extra-config=kubelet.container-runtime-endpoint=/var/run/crio.sock \
--extra-config=kubelet.image-service-endpoint=/var/run/crio.sock \
--bootstrapper=kubeadm
rkt container engine
Um rkt als Containerlaufzeitumgebung zu verwenden, führen Sie den folgenden Befehl aus:
minikube start \
--network-plugin=cni \
--enable-default-cni \
--container-runtime=rkt
Hierbei wird ein alternatives Minikube-ISO-Image verwendet, das sowohl rkt als auch Docker enthält, und CNI-Netzwerke ermöglichen.
Treiber Plugins
Weitere Informationen zu unterstützten Treibern und zur Installation von Plugins finden Sie bei Bedarf unter TREIBER.
Lokale Images durch erneute Verwendung des Docker-Daemon ausführen
Wenn Sie eine einzige Kubernetes VM verwenden, ist es sehr praktisch, den integrierten Docker-Daemon von Minikube wiederzuverwenden; Dies bedeutet, dass Sie auf Ihrem lokalen Computer keine Docker-Registy erstellen und das Image in die Registry importieren müssen - Sie können einfach innerhalb desselben Docker-Daemons wie Minikube arbeiten, was lokale Experimente beschleunigt. Stellen Sie einfach sicher, dass Sie Ihr Docker-Image mit einem anderen Element als 'latest' versehen, und verwenden Sie dieses Tag, wenn Sie das Image laden. Andernfalls, wenn Sie keine Version Ihres Images angeben, wird es als :latest angenommen, mit der Pull-Image-Richtlinie von Always entsprechend, was schließlich zu ErrImagePull führen kann, da Sie möglicherweise noch keine Versionen Ihres Docker-Images in der Standard-Docker-Registry (normalerweise DockerHub) haben.
Um mit dem Docker-Daemon auf Ihrem Mac/Linux-Computer arbeiten zu können, verwenden Sie den docker-env-Befehl in Ihrer Shell:
eval $(minikube docker-env)
Sie sollten nun Docker in der Befehlszeile Ihres Mac/Linux-Computers verwenden können, um mit dem Docker-Daemon in der Minikube-VM zu sprechen:
docker ps
In Centos 7 meldets Docker möglicherweise den folgenden Fehler:
Could not read CA certificate "/etc/docker/ca.pem": open /etc/docker/ca.pem: no such file or directory
Das Update besteht darin, /etc/sysconfig/docker zu aktualisieren, um sicherzustellen, dass die Umgebungsänderungen von Minikube beachtet werden:
< DOCKER_CERT_PATH=/etc/docker
---
> if [ -z "${DOCKER_CERT_PATH}" ]; then
> DOCKER_CERT_PATH=/etc/docker
> fi
Denken Sie daran, imagePullPolicy: Always auszuschalten. Andernfalls verwendet Kubernetes keine lokal erstellten Images.
Cluster verwalten
Cluster starten
Mit dem Befehl minikube start können Sie Ihr Cluster starten.
Dieser Befehl erstellt und konfiguriert eine virtuelle Maschine, auf der ein Kubernetes-Cluster mit einem Knoten ausgeführt wird.
Ebenfalls konfiguriert dieser Befehl auch Ihre kubectl Installation zur Kommunikation mit diesem Cluster.
Wenn Sie sich hinter einem Web-Proxy befinden, müssen Sie diese Informationen mit dem Befehl minikube start übergeben:
https_proxy=<mein_proxy> minikube start --docker-env http_proxy=<mein_proxy> --docker-env https_proxy=<mein_proxy> --docker-env no_proxy=192.168.99.0/24
Leider wird nur das Setzen der Umgebungsvariablen nicht funktionieren.
Minikube erstellt auch einen "Minikube"-Kontext und setzt ihn in kubectl auf den Standardwert.
Um später wieder zu diesem Kontext zurückzukehren, führen Sie den folgenden Befehl aus: kubectl config use-context minikube.
Angabe der Kubernetes-Version
Sie können die bestimmte Version von Kubernetes für Minikube angeben, indem Sie die Zeichenfolge --kubernetes-version an den Befehl minikube start anhängen.
Zum Verwenden der Version v1.7.3 führen Sie beispielsweise Folgendes aus:
minikube start --kubernetes-version v1.7.3
Kubernetes konfigurieren
Minikube verfügt über eine "Konfigurator"-Funktion, mit der Anwender die Kubernetes-Komponenten mit beliebigen Werten konfigurieren können.
Um diese Funktion zu verwenden, setzen Sie das --extra-config-Flag an den minikube start Befehl.
Dieses Flag wird wiederholt, sodass Sie es mehrere Male mit verschiedenen Werten übergeben können, um mehrere Optionen festzulegen.
Dieses Flag nimmt eine Zeichenkette der Form component.key=value an, wobei component eine der Zeichenketten aus der unteren Liste ist, key ein Wert in der Konfigurationsstruktur ist und value der einzustellende Wert ist.
Gültige Schlüssel finden Sie in der Dokumentation der Kubernetes componentconfigs für jede Komponente.
Nachstehend die Dokumentation für jede unterstützte Konfiguration:
Beispiele
Um die MaxPods-Einstellung im Kubelet auf 5 zu ändern, übergeben Sie dieses Flag: --extra-config=kubelet.MaxPods=5.
Diese Funktion unterstützt auch verschachtelte Strukturen. Um die LeaderElection.LeaderElect Einstellung zu true zu ändern, übergeben Sie im Scheduler dieses Flag: --extra-config=scheduler.LeaderElection.LeaderElect=true.
Um den AuthorizationMode auf dem apiserver zu RBAC zu ändern, verwenden Sie: --extra-config=apiserver.authorization-mode=RBAC.
Einen Cluster stoppen
Mit dem Befehl minikube stop können Sie Ihr Cluster anhalten.
Mit diesem Befehl wird die Minikube Virtual Machine heruntergefahren, der Clusterstatus und die Clusterdaten bleiben jedoch erhalten.
Durch erneutes Starten des Clusters wird der vorherige Status wiederhergestellt.
Cluster löschen
Der Befehl minikube delete kann zum Löschen Ihres Clusters verwendet werden.
Mit diesem Befehl wird die Minikube Virtual Machine heruntergefahren und gelöscht. Keine Daten oder Zustände bleiben erhalten.
Mit einem Cluster interagieren
Kubectl
Der minikube start Befehl erstellt einen kubectl Kontext genannt "minikube".
Dieser Kontext enthält die Konfiguration für die Kommunikation mit Ihrem Minikube-Cluster.
Minikube setzt diesen Kontext automatisch auf den Standardwert, aber wenn Sie in Zukunft wieder darauf zurückgreifen müssen, führen Sie den folgenden Befehl aus:
kubectl config use-context minikube,
Oder übergeben Sie den Kontext bei jedem Befehl wie folgt: kubectl get pods --context=minikube.
Dashboard
Um Zugriff auf das Kubernetes Dashboard zu erhalten, führen Sie diesen Befehl in einer Shell aus, nachdem Sie Minikube gestartet haben, um die Adresse abzurufen:
minikube dashboard
Services
Um auf einen Service zuzugreifen, der über einen NodePort verfügbar gemacht wird, führen Sie diesen Befehl in einer Shell aus, nachdem Sie Minikube gestartet haben, um die Adresse abzurufen:
minikube service [-n NAMESPACE] [--url] NAME
Netzwerk
Die Minikube-VM wird über eine Host-Only-IP-Adresse, die mit dem Befehl minikube ip abgerufen werden kann, für das Hostsystem verfügbar gemacht.
Auf alle Dienste des Typs NodePort kann über diese IP-Adresse und den NodePort zugegriffen werden.
Um den NodePort für Ihren Dienst zu ermitteln, können Sie einen kubectl-Befehl wie folgt verwenden:
kubectl get service $SERVICE --output='jsonpath="{.spec.ports[0].nodePort}"'
Dauerhafte Volumen
Minikube unterstützt PersistentVolumes des Typs hostPath.
Diese dauerhaften Volumen werden einem Verzeichnis in der Minikube-VM zugeordnet.
Die Minikube-VM wird in ein temporäres Dateisystem hochgefahren, sodass die meisten Verzeichnisse nicht nach Neustarts beibehalten werden (minikube stop).
Minikube ist jedoch so konfiguriert, dass Dateien beibehalten werden, die in den folgenden Host-Verzeichnissen gespeichert sind:
/data/var/lib/minikube/var/lib/docker
Hier ist ein Beispiel einer PersistentVolume-Konfiguration, um Daten im Verzeichnis / data beizubehalten:
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv0001
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 5Gi
hostPath:
path: /data/pv0001/
Hostordnerfreigabe
Einige Treiber werden einen Hostordner in der VM bereitstellen, sodass Sie Dateien problemlos zwischen VM und Host freigeben können. Diese sind momentan nicht konfigurierbar und unterscheiden sich für den Treiber und das Betriebssystem, das Sie verwenden.
| Treiber | Betriebssystem | Hostordner | VM |
|---|---|---|---|
| VirtualBox | Linux | /home | /hosthome |
| VirtualBox | macOS | /Users | /Users |
| VirtualBox | Windows | C://Users | /c/Users |
| VMware Fusion | macOS | /Users | /Users |
| Xhyve | macOS | /Users | /Users |
Private Containerregistries
Um auf eine private Container Registry zuzugreifen, führen Sie die Schritte auf dieser Seite aus.
Wir empfehlen die Verwendung von ImagePullSecrets, wenn Sie jedoch den Zugriff auf die Minikube-VM konfigurieren möchten, können Sie die Datei .dockercfg im Verzeichnis/home/docker oder die Datei config.json im Verzeichnis/home/docker/.docker ablegen.
Add-ons
Damit Minikube benutzerdefinierte Addons ordnungsgemäß starten oder neu starten kann, platzieren Sie die Addons, die mit Minikube gestartet werden sollen, im Verzeichnis ~ /.minikube/addons.
Addons in diesem Ordner werden in die Minikube-VM verschoben und jedes Mal gestartet, wenn Minikube gestartet oder neu gestartet wird.
Minikube mit einem HTTP-Proxy verwenden
Minikube erstellt eine virtuelle Maschine, die Kubernetes und einen Docker-Dämon enthält. Wenn Kubernetes versucht, Container mithilfe von Docker zu planen, erfordert der Docker-Daemon möglicherweise einen externen Netzwerkzugriff, um Container abzurufen.
Wenn Sie sich hinter einem HTTP-Proxy befinden, müssen Sie möglicherweise die Proxy-Einstellungen für Docker angeben.
Übergeben Sie dazu die erforderlichen Umgebungsvariablen während des minikube start als Flags.
Zum Beispiel:
minikube start --docker-env http_proxy=http://$IHRPROXY:PORT \
--docker-env https_proxy=https://$IHRPROXY:PORT
Wenn die Adresse Ihrer virtuellen Maschine 192.168.99.100 lautet, besteht die Möglichkeit, dass Ihre Proxy-Einstellungen verhindern, dass kubectl sie direkt erreicht.
Um die Proxy-Konfiguration für diese IP-Adresse zu umgehen, sollten Sie Ihre no_proxy-Einstellungen ändern. Sie können dies mit dem folgenden Befehl tun:
export no_proxy=$no_proxy,$(minikube ip)
Bekannte Probleme
- Funktionen, die einen Cloud-Provider erfordern, funktionieren in Minikube nicht. Diese schließen ein:
- LoadBalancer
- Features, die mehrere Knoten erfordern. Diese schließen ein:
- Erweiterte Planungsrichtlinien
Design
Minikube verwendet libmachine zur Bereitstellung von VMs, und kubeadm um einen Kubernetes-Cluster in Betrieb zu nehmen.
Weitere Informationen zu Minikube finden Sie im Vorschlag.
Zusätzliche Links
- Ziele und Nichtziele: Die Ziele und Nichtziele des Minikube-Projekts finden Sie in unserer Roadmap.
- Entwicklungshandbuch: Lesen Sie CONTRIBUTING.md für einen Überblick über das Senden von Pull-Requests.
- Minikube bauen: Anweisungen zum Erstellen/Testen von Minikube aus dem Quellcode finden Sie im build Handbuch.
- Neue Abhängigkeit hinzufügen: Anweisungen zum Hinzufügen einer neuen Abhängigkeit zu Minikube finden Sie in der Anleitung zum Hinzufügen von Abhängigkeiten.
- Neues Addon hinzufügen: Anweisungen zum Hinzufügen eines neuen Addons für Minikube finden Sie im Anleitung zum Hinzufügen eines Addons.
- MicroK8s: Linux-Benutzer, die die Ausführung einer virtuellen Maschine vermeiden möchten, sollten MicroK8s als Alternative in Betracht ziehen.
Community
Beiträge, Fragen und Kommentare werden begrüßt und ermutigt! Minikube-Entwickler finden Sie in Slack im #minikube Kanal (Erhalten Sie hier eine Einladung). Wir haben ausserdem die kubernetes-dev Google Groups-Mailingliste. Wenn Sie in der Liste posten, fügen Sie Ihrem Betreff bitte "minikube:" voran.
3 - Konzepte
Im Abschnitt Konzepte erfahren Sie mehr über die Bestandteile des Kubernetes-Systems und die Abstraktionen, die Kubernetes zur Verwaltung Ihres Clusters zur Verfügung stellt. Sie erhalten zudem ein tieferes Verständnis der Funktionsweise von Kubernetes.
3.1 - Überblick
3.1.1 - Was ist Kubernetes?
Diese Seite ist eine Übersicht über Kubernetes.
Kubernetes ist eine portable, erweiterbare Open-Source-Plattform zur Verwaltung von containerisierten Arbeitslasten und Services, die sowohl die deklarative Konfiguration als auch die Automatisierung erleichtert. Es hat ein großes, schnell wachsendes Ökosystem. Kubernetes Dienstleistungen, Support und Tools sind weit verbreitet.
Google hat das Kubernetes-Projekt 2014 als Open-Source-Projekt zur Verfügung gestellt. Kubernetes baut auf anderthalb Jahrzehnten Erfahrung auf, die Google mit der Ausführung von Produktions-Workloads in großem Maßstab hat, kombiniert mit den besten Ideen und Praktiken der Community.
Warum brauche ich Kubernetes und was kann ich damit tun?
Kubernetes hat eine Reihe von Funktionen. Es kann gesehen werden als:
- eine Containerplattform
- eine Microservices-Plattform
- eine portable Cloud-Plattform und vieles mehr.
Kubernetes bietet eine containerzentrierte Managementumgebung. Es koordiniert die Computer-, Netzwerk- und Speicherinfrastruktur im Namen der Benutzer-Workloads. Dies bietet einen Großteil der Einfachheit von Platform as a Service (PaaS) mit der Flexibilität von Infrastructure as a Service (IaaS) und ermöglicht die Portabilität zwischen Infrastrukturanbietern.
Wie ist Kubernetes eine Plattform?
Auch wenn Kubernetes eine Menge Funktionalität bietet, gibt es immer wieder neue Szenarien, die von neuen Funktionen profitieren würden. Anwendungsspezifische Workflows können optimiert werden, um die Entwicklungsgeschwindigkeit zu beschleunigen. Eine zunächst akzeptable Ad-hoc-Orchestrierung erfordert oft eine robuste Automatisierung in großem Maßstab. Aus diesem Grund wurde Kubernetes auch als Plattform für den Aufbau eines Ökosystems von Komponenten und Tools konzipiert, um die Bereitstellung, Skalierung und Verwaltung von Anwendungen zu erleichtern.
Labels ermöglichen es den Benutzern, ihre Ressourcen nach Belieben zu organisieren. Anmerkungen ermöglichen es Benutzern, Ressourcen mit benutzerdefinierten Informationen zu versehen, um ihre Arbeitsabläufe zu vereinfachen und eine einfache Möglichkeit für Managementtools zu bieten, den Status von Kontrollpunkten zu ermitteln.
Darüber hinaus basiert die Kubernetes-Steuerungsebene auf den gleichen APIs, die Entwicklern und Anwendern zur Verfügung stehen. Benutzer können ihre eigenen Controller, wie z.B. Scheduler, mit ihren eigenen APIs schreiben, die von einem universellen Kommandozeilen-Tool angesprochen werden können.
Dieses Design hat es einer Reihe anderer Systeme ermöglicht, auf Kubernetes aufzubauen.
Was Kubernetes nicht ist
Kubernetes ist kein traditionelles, allumfassendes PaaS (Plattform als ein Service) System. Da Kubernetes nicht auf Hardware-, sondern auf Containerebene arbeitet, bietet es einige allgemein anwendbare Funktionen, die PaaS-Angeboten gemeinsam sind, wie Bereitstellung, Skalierung, Lastausgleich, Protokollierung und Überwachung. Kubernetes ist jedoch nicht monolithisch, und diese Standardlösungen sind optional und modular erweiterbar. Kubernetes liefert die Bausteine für den Aufbau von Entwicklerplattformen, bewahrt aber die Wahlmöglichkeiten und Flexibilität der Benutzer, wo es wichtig ist.
Kubernetes:
- Schränkt nicht die Art der unterstützten Anwendungen ein. Kubernetes zielt darauf ab, eine extrem große Vielfalt von Workloads zu unterstützen, einschließlich stateless, stateful und datenverarbeitender Workloads. Wenn eine Anwendung in einem Container ausgeführt werden kann, sollte sie auf Kubernetes hervorragend laufen.
- Verteilt keinen Quellcode und entwickelt Ihre Anwendung nicht. Kontinuierliche Integrations-, Liefer- und Bereitstellungs-Workflows (CI/CD) werden durch Unternehmenskulturen und -präferenzen sowie technische Anforderungen bestimmt.
- Bietet keine Dienste auf Anwendungsebene, wie Middleware (z.B. Nachrichtenbusse), Datenverarbeitungs-Frameworks (z.B. Spark), Datenbanken (z.B. mysql), Caches oder Cluster-Speichersysteme (z.B. Ceph) als eingebaute Dienste. Solche Komponenten können auf Kubernetes laufen und/oder von Anwendungen, die auf Kubernetes laufen, über portable Mechanismen wie den Open Service Broker angesprochen werden.
- Bietet keine Konfigurationssprache bzw. kein Konfigurationssystem (z.B. jsonnet). Es bietet eine deklarative API, die von beliebigen Formen deklarativer Spezifikationen angesprochen werden kann.
- Bietet keine umfassenden Systeme zur Maschinenkonfiguration, Wartung, Verwaltung oder Selbstheilung.
Außerdem ist Kubernetes nicht nur ein Orchestrierungssystem. Fakt ist, dass es die Notwendigkeit einer Orchestrierung überflüssig macht. Die technische Definition von Orchestrierung ist die Ausführung eines definierten Workflows: zuerst A, dann B, dann C. Im Gegensatz dazu besteht Kubernetes aus einer Reihe von unabhängigen, komponierbaren Steuerungsprozessen, die den aktuellen Zustand kontinuierlich in Richtung des bereitgestellten Soll-Zustandes vorantreiben. Es sollte keine Rolle spielen, wie Sie von A nach C kommen. Eine zentrale Steuerung ist ebenfalls nicht erforderlich. Das Ergebnis ist ein System, das einfacher zu bedienen und leistungsfähiger, robuster, widerstandsfähiger und erweiterbar ist.
Warum Container?
Sie suchen nach Gründen, warum Sie Container verwenden sollten?

Der Altbekannte Weg zur Bereitstellung von Anwendungen war die Installation der Anwendungen auf einem Host mit dem Betriebssystempaketmanager. Dies hatte den Nachteil, dass die ausführbaren Dateien, Konfigurationen, Bibliotheken und Lebenszyklen der Anwendungen untereinander und mit dem Host-Betriebssystem verwoben waren. Man könnte unveränderliche Virtual-Machine-Images erzeugen, um vorhersehbare Rollouts und Rollbacks zu erreichen, aber VMs sind schwergewichtig und nicht portierbar.
Der Neue Weg besteht darin, Container auf Betriebssystemebene und nicht auf Hardware-Virtualisierung bereitzustellen. Diese Container sind voneinander und vom Host isoliert: Sie haben ihre eigenen Dateisysteme, sie können die Prozesse des anderen nicht sehen, und ihr Ressourcenverbrauch kann begrenzt werden. Sie sind einfacher zu erstellen als VMs, und da sie von der zugrunde liegenden Infrastruktur und dem Host-Dateisystem entkoppelt sind, sind sie über Clouds und Betriebssystem-Distributionen hinweg portabel.
Da Container klein und schnell sind, kann in jedes Containerimage eine Anwendung gepackt werden. Diese 1:1-Beziehung zwischen Anwendung und Image ermöglicht es, die Vorteile von Containern voll auszuschöpfen. Mit Containern können unveränderliche Container-Images eher zur Build-/Release-Zeit als zur Deployment-Zeit erstellt werden, da jede Anwendung nicht mit dem Rest des Anwendungsstacks komponiert werden muss und auch nicht mit der Produktionsinfrastrukturumgebung verbunden ist. Die Generierung von Container-Images zum Zeitpunkt der Erstellung bzw. Freigabe ermöglicht es, eine konsistente Umgebung von der Entwicklung bis zur Produktion zu gewährleisten. Ebenso sind Container wesentlich transparenter als VMs, was die Überwachung und Verwaltung erleichtert. Dies gilt insbesondere dann, wenn die Prozesslebenszyklen der Container von der Infrastruktur verwaltet werden und nicht von einem Prozess-Supervisor im Container versteckt werden. Schließlich, mit einer einzigen Anwendung pro Container, wird die Verwaltung der Container gleichbedeutend mit dem Management des Deployments der Anwendung.
Zusammenfassung der Container-Vorteile:
- Agile Anwendungserstellung und -bereitstellung: Einfachere und effizientere Erstellung von Container-Images im Vergleich zur Verwendung von VM-Images.
- Kontinuierliche Entwicklung, Integration und Bereitstellung: Bietet eine zuverlässige und häufige Erstellung und Bereitstellung von Container-Images mit schnellen und einfachen Rollbacks (aufgrund der Unveränderlichkeit des Images).
- Dev und Ops Trennung der Bedenken: Erstellen Sie Anwendungscontainer-Images nicht zum Deployment-, sondern zum Build-Releasezeitpunkt und entkoppeln Sie so Anwendungen von der Infrastruktur.
- Überwachbarkeit: Nicht nur Informationen und Metriken auf Betriebssystemebene werden angezeigt, sondern auch der Zustand der Anwendung und andere Signale.
- Umgebungskontinuität in Entwicklung, Test und Produktion: Läuft auf einem Laptop genauso wie in der Cloud.
- Cloud- und OS-Distribution-Portabilität: Läuft auf Ubuntu, RHEL, CoreOS, On-Prem, Google Kubernetes Engine und überall sonst.
- Anwendungsorientiertes Management: Erhöht den Abstraktionsgrad vom Ausführen eines Betriebssystems auf virtueller Hardware bis zum Ausführen einer Anwendung auf einem Betriebssystem unter Verwendung logischer Ressourcen.
- Locker gekoppelte, verteilte, elastische, freie Microservices: Anwendungen werden in kleinere, unabhängige Teile zerlegt und können dynamisch bereitgestellt und verwaltet werden -- nicht ein monolithischer Stack, der auf einer großen Single-Purpose-Maschine läuft.
- Ressourcenisolierung: Vorhersehbare Anwendungsleistung.
- Ressourcennutzung: Hohe Effizienz und Dichte.
Was bedeutet Kubernetes? K8s?
Der Name Kubernetes stammt aus dem Griechischen, bedeutet Steuermann oder Pilot, und ist der Ursprung von Gouverneur und cybernetic. K8s ist eine Abkürzung, die durch Ersetzen der 8 Buchstaben "ubernete" mit "8" abgeleitet wird.
Nächste Schritte
- Bereit loszulegen?
- Weitere Einzelheiten finden Sie in der Kubernetes Dokumentation.
3.1.2 - Kubernetes Komponenten
In diesem Dokument werden die verschiedenen binären Komponenten beschrieben, die zur Bereitstellung eines funktionsfähigen Kubernetes-Clusters erforderlich sind.
Master-Komponenten
Master-Komponenten stellen die Steuerungsebene des Clusters bereit. Master-Komponenten treffen globale Entscheidungen über den Cluster (z. B. Zeitplanung) und das Erkennen und Reagieren auf Clusterereignisse (Starten eines neuen Pods, wenn das replicas-Feld eines Replikationscontrollers nicht zufriedenstellend ist).
Master-Komponenten können auf jedem Computer im Cluster ausgeführt werden. Der Einfachheit halber starten Setup-Skripts normalerweise alle Master-Komponenten auf demselben Computer, und es werden keine Benutzercontainer auf diesem Computer ausgeführt. Lesen Sie Cluster mit hoher Verfügbarkeit erstellen für ein Beispiel für ein Multi-Master-VM-Setup.
kube-apiserver
Komponente auf dem Master, der die Kubernetes-API verfügbar macht. Es ist das Frontend für die Kubernetes-Steuerebene.
Es ist für die horizontale Skalierung konzipiert, d. H. Es skaliert durch die Bereitstellung von mehr Instanzen. Mehr informationen finden Sie unter Cluster mit hoher Verfügbarkeit erstellen.
etcd
Konsistenter und hochverfügbarer Key-Value Speicher, der als Backupspeicher von Kubernetes für alle Clusterdaten verwendet wird.
Halten Sie immer einen Sicherungsplan für etcds Daten für Ihren Kubernetes-Cluster bereit. Ausführliche Informationen zu etcd finden Sie in der etcd Dokumentation.
kube-scheduler
Komponente auf dem Master, die neu erstellte Pods überwacht, denen kein Node zugewiesen ist. Sie wählt den Node aus, auf dem sie ausgeführt werden sollen.
Zu den Faktoren, die bei Planungsentscheidungen berücksichtigt werden, zählen individuelle und kollektive Ressourcenanforderungen, Hardware- / Software- / Richtlinieneinschränkungen, Affinitäts- und Anti-Affinitätsspezifikationen, Datenlokalität, Interworkload-Interferenz und Deadlines.
kube-controller-manager
Komponente auf dem Master, auf dem controllers ausgeführt werden.
Logisch gesehen ist jeder controller ein separater Prozess, aber zur Vereinfachung der Komplexität werden sie alle zu einer einzigen Binärdatei zusammengefasst und in einem einzigen Prozess ausgeführt.
Diese Controller umfassen:
- Node Controller: Verantwortlich für das Erkennen und Reagieren, wenn Nodes ausfallen.
- Replication Controller: Verantwortlich für die Aufrechterhaltung der korrekten Anzahl von Pods für jedes Replikationscontrollerobjekt im System.
- Endpoints Controller: Füllt das Endpoints-Objekt aus (d.h. verbindet Services & Pods).
- Service Account & Token Controllers: Erstellt Standardkonten und API-Zugriffstoken für neue Namespaces.
cloud-controller-manager
cloud-controller-manager führt Controller aus, die mit den entsprechenden Cloud-Anbietern interagieren. Der cloud-controller-manager ist eine Alpha-Funktion, die in Kubernetes Version 1.6 eingeführt wurde.
cloud-controller-manager führt nur Cloud-Provider-spezifische Controller-Schleifen aus. Sie müssen diese Controller-Schleifen im Cube-Controller-Manager deaktivieren. Sie können die Controller-Schleifen deaktivieren, indem Sie beim Starten des kube-controller-manager das Flag --cloud-provider auf external setzen.
cloud-controller-manager erlaubt es dem Cloud-Anbieter Code und dem Kubernetes-Code, sich unabhängig voneinander zu entwickeln. In früheren Versionen war der Kerncode von Kubernetes für die Funktionalität von Cloud-Provider-spezifischem Code abhängig. In zukünftigen Versionen sollte der für Cloud-Anbieter spezifische Code vom Cloud-Anbieter selbst verwaltet und mit dem Cloud-Controller-Manager verknüpft werden, während Kubernetes ausgeführt wird.
Die folgenden Controller haben Abhängigkeiten von Cloud-Anbietern:
- Node Controller: Zum Überprüfen, ob ein Node in der Cloud beim Cloud-Anbieter gelöscht wurde, nachdem er nicht mehr reagiert
- Route Controller: Zum Einrichten von Routen in der zugrunde liegenden Cloud-Infrastruktur
- Service Controller: Zum Erstellen, Aktualisieren und Löschen von Lastverteilern von Cloud-Anbietern
- Volume Controller: Zum Erstellen, Verbinden und Bereitstellen von Volumes und zur Interaktion mit dem Cloud-Provider zum Orchestrieren von Volumes
Node-Komponenten
Node Komponenten werden auf jedem Knoten ausgeführt, halten laufende Pods aufrecht und stellen die Kubernetes-Laufzeitumgebung bereit.
kubelet
Ein Agent, der auf jedem Node im Cluster ausgeführt wird. Er stellt sicher, dass Container in einem Pod ausgeführt werden.
Das Kubelet verwendet eine Reihe von PodSpecs, die über verschiedene Mechanismen bereitgestellt werden, und stellt sicher, dass die in diesen PodSpecs beschriebenen Container ordnungsgemäß ausgeführt werden. Das kubelet verwaltet keine Container, die nicht von Kubernetes erstellt wurden.
kube-proxy
kube-proxy ermöglicht die Kubernetes Service-Abstraktion, indem die Netzwerkregeln auf dem Host beibehalten und die Verbindungsweiterleitung durchgeführt wird.
Container Runtime
Die Containerlaufzeit ist die Software, die für das Ausführen von Containern verantwortlich ist. Kubernetes unterstützt mehrere Laufzeiten: Docker, containerd, cri-o, rktlet und jede Implementierung des Kubernetes CRI (Container Runtime Interface).
Addons
Addons sind Pods und Dienste, die Clusterfunktionen implementieren. Die Pods können verwaltet werden
durch Deployments, ReplicationControllers, und so wieter.
Namespace-Addon-Objekte werden im Namespace kube-system erstellt.
Ausgewählte Addons werden unten beschrieben. Eine erweiterte Liste verfügbarer Addons finden Sie unter Addons.
DNS
Während die anderen Addons nicht unbedingt erforderlich sind, sollte cluster DNS in allen Kubernetes-Cluster vorhanden sein, da viele Beispiele davon abhängen.
Cluster-DNS ist neben anderen DNS-Servern in Ihrer Umgebung ein DNS-Server, der DNS-Einträge für Kubernetes-Dienste bereitstellt.
Von Kubernetes gestartete Container schließen diesen DNS-Server automatisch in ihre DNS-Suchen ein.
Web UI (Dashboard)
Dashboard ist eine allgemeine, webbasierte Benutzeroberfläche für Kubernetes-Cluster. Benutzer können damit Anwendungen, die im Cluster ausgeführt werden, sowie den Cluster selbst verwalten und Fehler beheben.
Container Resource Monitoring
Container Resource Monitoring zeichnet generische Zeitreihenmessdaten zu Containern in einer zentralen Datenbank auf und stellt eine Benutzeroberfläche zum Durchsuchen dieser Daten bereit.
Cluster-level Logging
Ein Cluster-level logging Mechanismus ist für das Speichern von Containerprotokollen in einem zentralen Protokollspeicher mit Such- / Browsing-Schnittstelle verantwortlich.
3.2 - Kubernetes Architektur
3.2.1 - Nodes
Ein Knoten (Node in Englisch) ist eine Arbeitsmaschine in Kubernetes. Ein Node kann je nach Cluster eine VM oder eine physische Maschine sein. Jeder Node enthält die für den Betrieb von Pods notwendigen Dienste und wird von den Master-Komponenten verwaltet. Die Dienste auf einem Node umfassen die Container Runtime, das Kubelet und den Kube-Proxy. Weitere Informationen finden Sie im Abschnitt Kubernetes Node in der Architekturdesign-Dokumentation.
Node Status
Der Status eines Nodes enthält folgende Informationen:
Jeder Abschnitt wird folgend detailliert beschrieben.
Adressen
Die Verwendung dieser Felder hängt von Ihrem Cloud-Anbieter oder der Bare-Metal-Konfiguration ab.
- HostName: Der vom Kernel des Nodes gemeldete Hostname. Kann mit dem kubelet-Parameter
--hostname-overrideüberschrieben werden. - ExternalIP: In der Regel die IP-Adresse des Nodes, die extern geroutet werden kann (von außerhalb des Clusters verfügbar).
- InternalIP: In der Regel die IP-Adresse des Nodes, die nur innerhalb des Clusters routbar ist.
Zustand
Das conditions Feld beschreibt den Zustand, aller Running Nodes.
| Node Condition | Beschreibung |
|---|---|
OutOfDisk |
True wenn auf dem Node nicht genügend freier Speicherplatz zum Hinzufügen neuer Pods vorhanden ist, andernfalls False |
Ready |
True wenn der Node in einem guten Zustand und bereit ist Pods aufzunehmen, False wenn der Node nicht in einem guten Zustand ist und nicht bereit ist Pods aufzunehmeb, und Unknown wenn der Node-Controller seit der letzten node-monitor-grace-period nichts von dem Node gehört hat (Die Standardeinstellung beträgt 40 Sekunden) |
MemoryPressure |
True wenn der verfügbare Speicher des Nodes niedrig ist; AndernfallsFalse |
PIDPressure |
True wenn zu viele Prozesse auf dem Node vorhanden sind; AndernfallsFalse |
DiskPressure |
True wenn die Festplattenkapazität niedrig ist. Andernfalls False |
NetworkUnavailable |
True wenn das Netzwerk für den Node nicht korrekt konfiguriert ist, andernfalls False |
Der Zustand eines Nodes wird als JSON-Objekt dargestellt. Die folgende Antwort beschreibt beispielsweise einen fehlerfreien Node.
"conditions": [
{
"type": "Ready",
"status": "True"
}
]
Wenn der Status der Ready-Bedingung Unknown oder False länger als der pod-eviction-timeout bleibt, wird ein Parameter an den kube-controller-manager übergeben und alle Pods auf dem Node werden vom Node Controller gelöscht.
Die voreingestellte Zeit vor der Entfernung beträgt fünf Minuten. In einigen Fällen, in denen der Node nicht erreichbar ist, kann der Apiserver nicht mit dem Kubelet auf dem Node kommunizieren. Die Entscheidung, die Pods zu löschen, kann dem Kublet erst mitgeteilt werden, wenn die Kommunikation mit dem Apiserver wiederhergestellt ist. In der Zwischenzeit können Pods, deren Löschen geplant ist, weiterhin auf dem unzugänglichen Node laufen.
In Versionen von Kubernetes vor 1.5 würde der Node Controller das Löschen dieser unerreichbaren Pods vom Apiserver erzwingen. In Version 1.5 und höher erzwingt der Node Controller jedoch keine Pod Löschung, bis bestätigt wird, dass sie nicht mehr im Cluster ausgeführt werden. Pods die auf einem unzugänglichen Node laufen sind eventuell in einem einem Terminating oder Unkown Status. In Fällen, in denen Kubernetes nicht aus der zugrunde liegenden Infrastruktur schließen kann, ob ein Node einen Cluster dauerhaft verlassen hat, muss der Clusteradministrator den Node möglicherweise manuell löschen.
Das Löschen des Kubernetes-Nodeobjekts bewirkt, dass alle auf dem Node ausgeführten Pod-Objekte gelöscht und deren Namen freigegeben werden.
In Version 1.12 wurde die Funktion TaintNodesByCondition als Beta-Version eingeführt, die es dem Node-Lebenszyklus-Controller ermöglicht, automatisch Markierungen (taints in Englisch) zu erstellen, die Bedingungen darstellen.
Ebenso ignoriert der Scheduler die Bedingungen, wenn er einen Node berücksichtigt; stattdessen betrachtet er die Markierungen (taints) des Nodes und die Toleranzen eines Pod.
Anwender können jetzt zwischen dem alten Scheduling-Modell und einem neuen, flexibleren Scheduling-Modell wählen.
Ein Pod, der keine Toleranzen aufweist, wird gemäß dem alten Modell geplant. Aber ein Pod, die die Taints eines bestimmten Node toleriert, kann auf diesem Node geplant werden.
Kapazität
Beschreibt die auf dem Node verfügbaren Ressourcen: CPU, Speicher und die maximale Anzahl der Pods, die auf dem Node ausgeführt werden können.
Info
Allgemeine Informationen zum Node, z. B. Kernelversion, Kubernetes-Version (kubelet- und kube-Proxy-Version), Docker-Version (falls verwendet), Betriebssystemname. Die Informationen werden von Kubelet vom Node gesammelt.
Management
Im Gegensatz zu Pods und Services, ein Node wird nicht von Kubernetes erstellt: Er wird extern von Cloud-Anbietern wie Google Compute Engine erstellt oder ist in Ihrem Pool physischer oder virtueller Maschinen vorhanden. Wenn Kubernetes also einen Node erstellt, wird ein Objekt erstellt, das den Node darstellt. Nach der Erstellung überprüft Kubernetes, ob der Node gültig ist oder nicht.
Wenn Sie beispielsweise versuchen, einen Node aus folgendem Inhalt zu erstellen:
{
"kind": "Node",
"apiVersion": "v1",
"metadata": {
"name": "10.240.79.157",
"labels": {
"name": "my-first-k8s-node"
}
}
}
Kubernetes erstellt intern ein Node-Objekt (die Darstellung) und validiert den Node durch Zustandsprüfung basierend auf dem Feld metadata.name.
Wenn der Node gültig ist, d.h. wenn alle notwendigen Dienste ausgeführt werden, ist er berechtigt, einen Pod auszuführen.
Andernfalls wird er für alle Clusteraktivitäten ignoriert, bis er gültig wird.
Aktuell gibt es drei Komponenten, die mit dem Kubernetes Node-Interface interagieren: Node Controller, Kubelet und Kubectl.
Node Controller
Der Node Controller ist eine Kubernetes-Master-Komponente, die verschiedene Aspekte von Nodes verwaltet.
Der Node Controller hat mehrere Rollen im Leben eines Nodes. Der erste ist die Zuordnung eines CIDR-Blocks zu dem Node, wenn er registriert ist (sofern die CIDR-Zuweisung aktiviert ist).
Die zweite ist, die interne Node-Liste des Node Controllers mit der Liste der verfügbaren Computer des Cloud-Anbieters auf dem neuesten Stand zu halten. Wenn ein Node in einer Cloud-Umgebung ausgeführt wird und sich in einem schlechten Zustand befindet, fragt der Node Controller den Cloud-Anbieter, ob die virtuelle Maschine für diesen Node noch verfügbar ist. Wenn nicht, löscht der Node Controller den Node aus seiner Node-Liste.
Der dritte ist die Überwachung des Zustands der Nodes. Der Node Controller ist dafür verantwortlich, die NodeReady-Bedingung von NodeStatus auf ConditionUnknown zu aktualisieren, wenn ein Node unerreichbar wird (der Node Controller empfängt aus irgendeinem Grund keine Herzschläge mehr, z.B. weil der Node heruntergefahren ist) und später alle Pods aus dem Node zu entfernen (und diese ordnungsgemäss zu beenden), wenn der Node weiterhin unzugänglich ist. (Die Standard-Timeouts sind 40s, um ConditionUnknown zu melden und 5 Minuten, um mit der Evakuierung der Pods zu beginnen).
Der Node Controller überprüft den Zustand jedes Nodes alle --node-monitor-period Sekunden.
In Versionen von Kubernetes vor 1.13 ist NodeStatus der Herzschlag des Nodes.
Ab Kubernetes 1.13 wird das Node-Lease-Feature als Alpha-Feature eingeführt (Feature-Gate NodeLease, KEP-0009).
Wenn die Node Lease Funktion aktiviert ist, hat jeder Node ein zugeordnetes Lease-Objekt im kube-node-lease-Namespace, das vom Node regelmäßig erneuert wird.
Sowohl NodeStatus als auch Node Lease werden als Herzschläge vom Node aus behandelt.
Node Leases werden häufig erneuert, während NodeStatus nur dann vom Node zu Master gemeldet wird, wenn sich etwas ändert oder genügend Zeit vergangen ist (Standard ist 1 Minute, was länger ist als der Standard-Timeout von 40 Sekunden für unerreichbare Nodes).
Da Node Leases viel lastärmer sind als NodeStatus, macht diese Funktion den Node Herzschlag sowohl in Bezug auf Skalierbarkeit als auch auf die Leistung deutlich effizienter.
In Kubernetes 1.4 haben wir die Logik der Node-Steuerung aktualisiert, um Fälle besser zu handhaben, in denen eine große Anzahl von Nodes Probleme hat, den Master zu erreichen (z.B. weil der Master Netzwerkprobleme hat). Ab 1.4 betrachtet der Node-Controller den Zustand aller Nodes im Cluster, wenn er eine Entscheidung über die Enterfung eines Pods trifft.
In den meisten Fällen begrenzt der Node-Controller die Entfernungsrate auf --node-eviction-rate (Standard 0,1) pro Sekunde, was bedeutet, dass er die Pods nicht von mehr als einem Node pro 10 Sekunden entfernt.
Das Entfernungsverhalten von Nodes ändert sich, wenn ein Node in einer bestimmten Verfügbarkeitszone ungesund wird.
Der Node-Controller überprüft gleichzeitig, wie viel Prozent der Nodes in der Zone ungesund sind (NodeReady-Bedingung ist ConditionUnknown oder ConditionFalse).
Wenn der Anteil der ungesunden Nodes mindestens --unhealthy-zone-threshold (Standard 0,55) beträgt, wird die Entfernungsrate reduziert:
Wenn der Cluster klein ist (d.h. weniger als oder gleich --large-cluster-size-threshold Node - Standard 50), werden die Entfernungen gestoppt. Andernfalls wird die Entfernungsrate auf --secondary-node-eviction-rate (Standard 0,01) pro Sekunde reduziert.
Der Grund, warum diese Richtlinien pro Verfügbarkeitszone implementiert werden, liegt darin, dass eine Verfügbarkeitszone vom Master unerreichbar werden könnte, während die anderen verbunden bleiben. Wenn Ihr Cluster nicht mehrere Verfügbarkeitszonen von Cloud-Anbietern umfasst, gibt es nur eine Verfügbarkeitszone (den gesamten Cluster).
Ein wichtiger Grund für die Verteilung Ihrer Nodes auf Verfügbarkeitszonen ist, dass die Arbeitsbelastung auf gesunde Zonen verlagert werden kann, wenn eine ganze Zone ausfällt.
Wenn also alle Nodes in einer Zone ungesund sind, entfernt Node Controller mit der normalen --node-eviction-rate Geschwindigkeit.
Der Ausnahmefall ist, wenn alle Zonen völlig ungesund sind (d.h. es gibt keine gesunden Node im Cluster).
In diesem Fall geht der Node-Controller davon aus, dass es ein Problem mit der Master-Konnektivität gibt und stoppt alle Entfernungen, bis die Verbindung wiederhergestellt ist.
Ab Kubernetes 1.6 ist der Node-Controller auch für die Entfernung von Pods zuständig, die auf Nodes mit NoExecute-Taints laufen, wenn die Pods die Markierungen nicht tolerieren.
Zusätzlich ist der NodeController als Alpha-Funktion, die standardmäßig deaktiviert ist, dafür verantwortlich, Taints hinzuzufügen, die Node Probleme, wie Node unreachable oder not ready entsprechen.
Siehe diese Dokumentation für Details über NoExecute Taints und die Alpha-Funktion.
Ab Version 1.8 kann der Node-Controller für die Erzeugung von Taints, die Node Bedingungen darstellen, verantwortlich gemacht werden. Dies ist eine Alpha-Funktion der Version 1.8.
Selbstregistrierung von Nodes
Wenn das Kubelet-Flag --register-node aktiv ist (Standard), versucht das Kubelet, sich beim API-Server zu registrieren. Dies ist das bevorzugte Muster, das von den meisten Distributionen verwendet wird.
Zur Selbstregistrierung wird das kubelet mit den folgenden Optionen gestartet:
--kubeconfig- Pfad zu Anmeldeinformationen, um sich beim Apiserver zu authentifizieren.--cloud-provider- Wie man sich mit einem Cloud-Anbieter unterhält, um Metadaten über sich selbst zu lesen.--register-node- Automatisch beim API-Server registrieren.--register-with-taints- Registrieren Sie den Node mit der angegebenen Taints-Liste (Kommagetrennt<key>=<value>:<effect>). No-op wennregister-nodefalse ist.--node-ip- IP-Adresse des Nodes.--node-labels- Labels, die bei der Registrierung des Nodes im Cluster hinzugefügt werden sollen (Beachten Sie die Richlinien des NodeRestriction admission plugin in 1.13+).--node-status-update-frequency- Gibt an, wie oft kubelet den Nodestatus an den Master übermittelt.
Wenn der Node authorization mode und NodeRestriction admission plugin aktiviert sind, dürfen kubelets nur ihre eigene Node-Ressource erstellen / ändern.
Manuelle Nodeverwaltung
Ein Cluster-Administrator kann Nodeobjekte erstellen und ändern.
Wenn der Administrator Nodeobjekte manuell erstellen möchte, setzen Sie das kubelet Flag --register-node=false.
Der Administrator kann Node-Ressourcen ändern (unabhängig von der Einstellung von --register-node).
Zu den Änderungen gehören das Setzen von Labels und das Markieren des Nodes.
Labels auf Nodes können in Verbindung mit node selectors auf Pods verwendet werden, um die Planung zu steuern, z.B. um einen Pod so zu beschränken, dass er nur auf einer Teilmenge der Nodes ausgeführt werden darf.
Das Markieren eines Nodes als nicht geplant, verhindert, dass neue Pods für diesen Node geplant werden. Dies hat jedoch keine Auswirkungen auf vorhandene Pods auf dem Node. Dies ist nützlich als vorbereitender Schritt vor einem Neustart eines Nodes usw. Um beispielsweise einen Node als nicht geplant zu markieren, führen Sie den folgenden Befehl aus:
kubectl cordon $NODENAME
Node Kapazität
Die Kapazität des Nodes (Anzahl der CPU und Speichermenge) ist Teil des Nodeobjekts. Normalerweise registrieren sich Nodes selbst und melden ihre Kapazität beim Erstellen des Nodeobjekts. Sofern Sie Manuelle Nodeverwaltung betreiben, müssen Sie die Node Kapazität setzen, wenn Sie einen Node hinzufügen.
Der Kubernetes-Scheduler stellt sicher, dass für alle Pods auf einem Nodes genügend Ressourcen vorhanden sind. Er prüft, dass die Summe der Requests von Containern auf dem Node nicht größer ist als die Kapazität des Nodes. Er beinhaltet alle Container die vom kubelet gestarted worden, aber keine Container die direkt von der container runtime gestartet wurden, noch jegleiche Prozesse die ausserhalb von Containern laufen.
Wenn Sie Ressourcen explizit für Nicht-Pod-Prozesse reservieren möchten, folgen Sie diesem Lernprogramm um Ressourcen für Systemdaemons zu reservieren.
API-Objekt
Node ist eine Top-Level-Ressource in der Kubernetes-REST-API. Weitere Details zum API-Objekt finden Sie unter: Node API object.
3.2.2 - Master-Node Kommunikation
Dieses Dokument katalogisiert die Kommunikationspfade zwischen dem Master (eigentlich dem Apiserver) und des Kubernetes-Clusters. Die Absicht besteht darin, Benutzern die Möglichkeit zu geben, ihre Installation so anzupassen, dass die Netzwerkkonfiguration so abgesichert wird, dass der Cluster in einem nicht vertrauenswürdigen Netzwerk (oder mit vollständig öffentlichen IP-Adressen eines Cloud-Providers) ausgeführt werden kann.
Cluster zum Master
Alle Kommunikationspfade vom Cluster zum Master enden beim Apiserver (keine der anderen Master-Komponenten ist dafür ausgelegt, Remote-Services verfügbar zu machen). In einem typischen Setup ist der Apiserver so konfiguriert, dass er Remote-Verbindungen an einem sicheren HTTPS-Port (443) mit einer oder mehreren Formen der Clientauthentifizierung überwacht. Eine oder mehrere Formene von Autorisierung sollte aktiviert sein, insbesondere wenn anonyme Anfragen oder Service Account Tokens aktiviert sind.
Nodes sollten mit dem öffentlichen Stammzertifikat für den Cluster konfiguriert werden, sodass sie eine sichere Verbindung zum Apiserver mit gültigen Client-Anmeldeinformationen herstellen können. Beispielsweise bei einer gewöhnlichen GKE-Konfiguration enstprechen die dem kubelet zur Verfügung gestellten Client-Anmeldeinformationen eines Client-Zertifikats. Lesen Sie über kubelet TLS bootstrapping zur automatisierten Bereitstellung von kubelet-Client-Zertifikaten.
Pods, die eine Verbindung zum Apiserver herstellen möchten, können dies auf sichere Weise tun, indem sie ein Dienstkonto verwenden, sodass Kubernetes das öffentliche Stammzertifikat und ein gültiges Trägertoken automatisch in den Pod einfügt, wenn er instanziiert wird.
Der kubernetes-Dienst (in allen Namespaces) ist mit einer virtuellen IP-Adresse konfiguriert, die (über den Kube-Proxy) an den HTTPS-Endpunkt auf dem Apiserver umgeleitet wird.
Die Master-Komponenten kommunizieren auch über den sicheren Port mit dem Cluster-Apiserver.
Der Standardbetriebsmodus für Verbindungen vom Cluster (Knoten und Pods, die auf den Knoten ausgeführt werden) zum Master ist daher standardmäßig gesichert und kann über nicht vertrauenswürdige und/oder öffentliche Netzwerke laufen.
Master zum Cluster
Es gibt zwei primäre Kommunikationspfade vom Master (Apiserver) zum Cluster. Der Erste ist vom Apiserver hin zum Kubelet-Prozess, der auf jedem Node im Cluster ausgeführt wird. Der Zweite ist vom Apiserver zu einem beliebigen Node, Pod oder Dienst über die Proxy-Funktionalität des Apiservers.
Apiserver zum kubelet
Die Verbindungen vom Apiserver zum Kubelet werden verwendet für:
- Das Abrufen von Protokollen für Pods.
- Das Verbinden (durch kubectl) mit laufenden Pods.
- Die Bereitstellung der Portweiterleitungsfunktion des kubelet.
Diese Verbindungen enden am HTTPS-Endpunkt des kubelet. Standardmäßig überprüft der Apiserver das Serverzertifikat des Kubelets nicht, was die Verbindung angreifbar für Man-in-the-Middle-Angriffe macht. Die Kommunikation ist daher unsicher, wenn die Verbindungen über nicht vertrauenswürdige und/oder öffentliche Netzwerke laufen.
Um diese Verbindung zu überprüfen, verwenden Sie das Flag --kubelet-certificate-authority, um dem Apiserver ein Stammzertifikatbündel bereitzustellen, das zur Überprüfung des Server-Zertifikats des kubelets verwendet wird.
Wenn dies nicht möglich ist, verwenden Sie SSH tunneling zwischen dem Apiserver und dem kubelet, falls es erforderlich ist eine Verbindung über ein nicht vertrauenswürdiges oder öffentliches Netz zu vermeiden.
Außerdem sollte Kubelet Authentifizierung und/oder Autorisierung aktiviert sein, um die kubelet-API abzusichern.
Apiserver zu Nodes, Pods und Services
Die Verbindungen vom Apiserver zu einem Node, Pod oder Dienst verwenden standardmäßig einfache HTTP-Verbindungen und werden daher weder authentifiziert noch verschlüsselt. Sie können über eine sichere HTTPS-Verbindung ausgeführt werden, indem dem Node, dem Pod oder dem Servicenamen in der API-URL "https:" vorangestellt wird. Das vom HTTPS-Endpunkt bereitgestellte Zertifikat wird jedoch nicht überprüft, und es werden keine Clientanmeldeinformationen bereitgestellt. Die Verbindung wird zwar verschlüsselt, garantiert jedoch keine Integrität. Diese Verbindungen sind derzeit nicht sicher innerhalb von nicht vertrauenswürdigen und/oder öffentlichen Netzen.
SSH Tunnels
Kubernetes unterstützt SSH-Tunnel zum Schutz der Master -> Cluster Kommunikationspfade. In dieser Konfiguration initiiert der Apiserver einen SSH-Tunnel zu jedem Node im Cluster (Verbindung mit dem SSH-Server, der mit Port 22 läuft), und leitet den gesamten Datenverkehr für ein kubelet, einen Node, einen Pod oder einen Dienst durch den Tunnel. Dieser Tunnel stellt sicher, dass der Datenverkehr nicht außerhalb des Netzwerks sichtbar ist, in dem die Knoten ausgeführt werden.
SSH-Tunnel werden zur Zeit nicht unterstützt. Sie sollten also nicht verwendet werden, sei denn, man weiß, was man tut. Ein Ersatz für diesen Kommunikationskanal wird entwickelt.
3.2.3 - Zugrunde liegende Konzepte des Cloud Controller Manager
Das Konzept des Cloud Controller Managers (CCM) (nicht zu verwechseln mit der Binärdatei) wurde ursprünglich entwickelt, um Cloud-spezifischen Anbieter Code und den Kubernetes Kern unabhängig voneinander entwickeln zu können. Der Cloud Controller Manager läuft zusammen mit anderen Master Komponenten wie dem Kubernetes Controller Manager, dem API-Server und dem Scheduler auf dem Host. Es kann auch als Kubernetes Addon gestartet werden, in diesem Fall läuft er auf Kubernetes.
Das Design des Cloud Controller Managers basiert auf einem Plugin Mechanismus, der es neuen Cloud Anbietern ermöglicht, sich mit Kubernetes einfach über Plugins zu integrieren. Es gibt Pläne für die Einbindung neuer Cloud Anbieter auf Kubernetes und für die Migration von Cloud Anbietern vom alten Modell auf das neue CCM-Modell.
Dieses Dokument beschreibt die Konzepte hinter dem Cloud Controller Manager und gibt Details zu den damit verbundenen Funktionen.
Die Architektur eines Kubernetes Clusters ohne den Cloud Controller Manager sieht wie folgt aus:
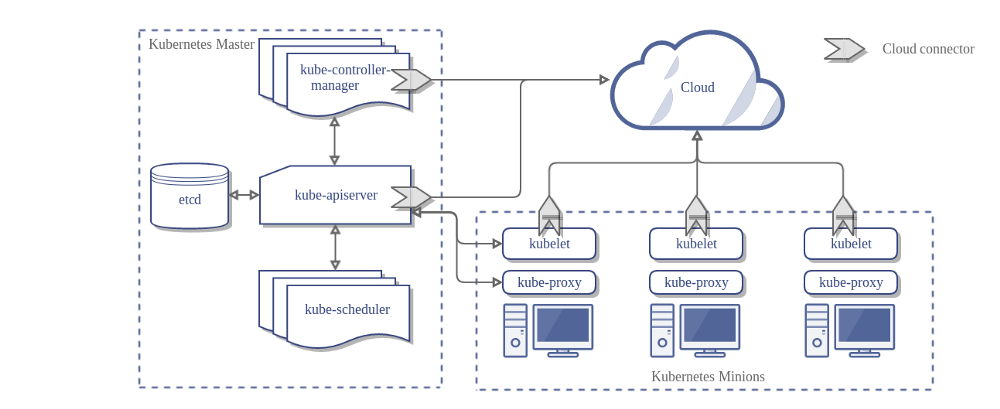
Design
Im vorhergehenden Diagramm sind Kubernetes und der Cloud-Provider über mehrere verschiedene Komponenten integriert:
- Kubelet
- Kubernetes Controller Manager
- Kubernetes API Server
CCM konsolidiert die gesamte Abhängigkeit der Cloud Logik von den drei vorhergehenden Komponenten zu einem einzigen Integrationspunkt mit der Cloud. So sieht die neue Architektur mit dem CCM aus:
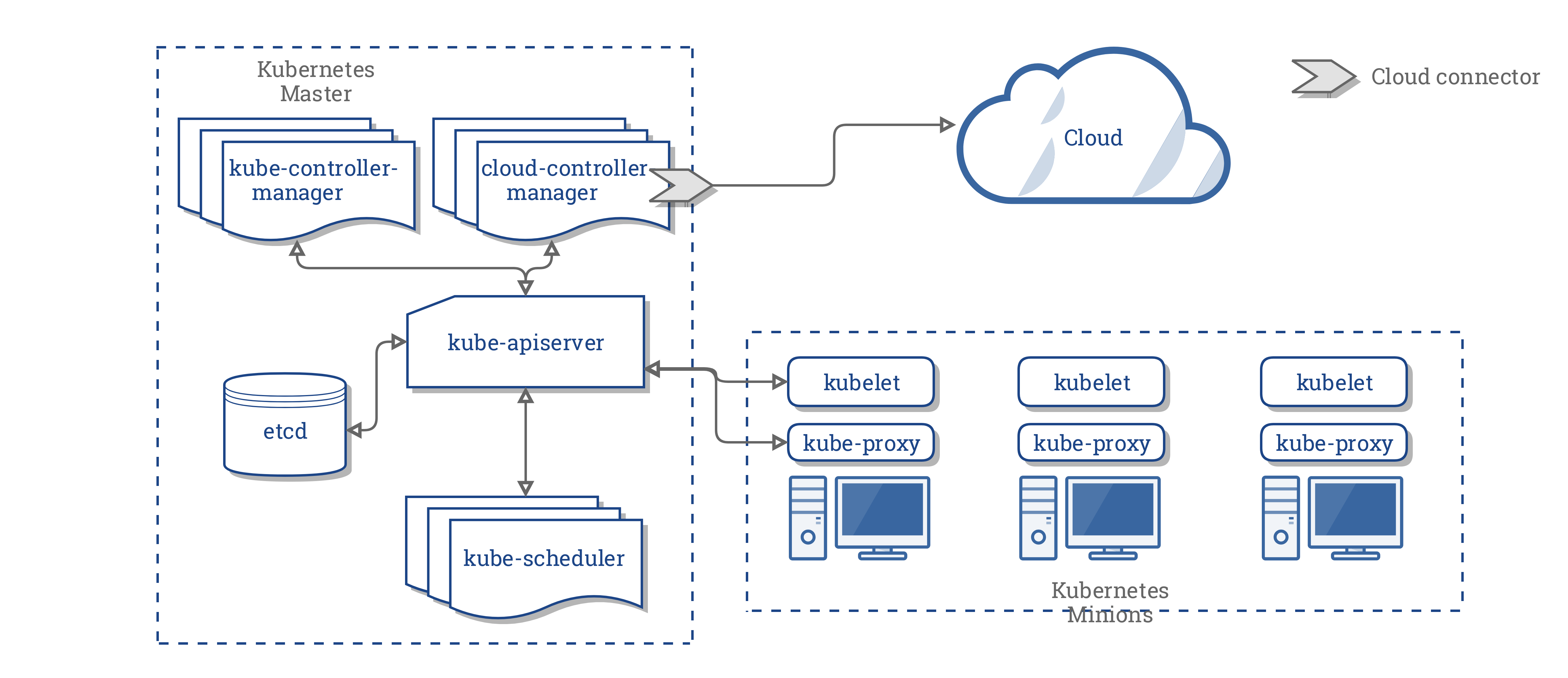
Komponenten des CCM
Der CCM löst einen Teil der Funktionalität des Kubernetes Controller Managers (KCM) ab und führt ihn als separaten Prozess aus. Konkret trennt es die Cloud abhängigen Controller im KCM. Der KCM verfügt über die folgenden Cloud abhängigen Steuerungsschleifen:
- Node Controller
- Volume Controller
- Route Controller
- Service Controller
In der Version 1.9 führt der CCM die folgenden Controller aus der vorhergehenden Liste aus:
- Node Controller
- Route Controller
- Service Controller
Der ursprüngliche Plan, Volumes mit CCM zu integrieren, sah die Verwendung von Flex-Volumes vor welche austauschbare Volumes unterstützt. Allerdings ist eine konkurrierende Initiative namens CSI geplant, um Flex zu ersetzen.
In Anbetracht dieser Dynamik haben wir uns entschieden, eine Zwischenstopp durchzuführen um die Unterschiede zu beobachten , bis das CSI bereit ist.
Funktionen des CCM
Der CCM erbt seine Funktionen von Komponenten des Kubernetes, die von einem Cloud Provider abhängig sind. Dieser Abschnitt ist auf der Grundlage dieser Komponenten strukturiert.
1. Kubernetes Controller Manager
Die meisten Funktionen des CCM stammen aus dem KCM. Wie im vorherigen Abschnitt erwähnt, führt das CCM die folgenden Steuerschleifen durch:
- Node Controller
- Route Controller
- Service Controller
Node Controller
Der Node Controller ist für die Initialisierung eines Knotens verantwortlich, indem er Informationen über die im Cluster laufenden Knoten vom Cloud Provider erhält. Der Node Controller führt die folgenden Funktionen aus:
- Initialisierung eines Knoten mit Cloud-spezifischen Zonen-/Regionen Labels.
- Initialisieren von Knoten mit Cloud-spezifischen Instanzdetails, z.B. Typ und Größe.
- Ermitteln der Netzwerkadressen und des Hostnamen des Knotens.
- Falls ein Knoten nicht mehr reagiert, überprüft der Controller die Cloud, um festzustellen, ob der Knoten aus der Cloud gelöscht wurde. Wenn der Knoten aus der Cloud gelöscht wurde, löscht der Controller das Kubernetes Node Objekt.
Route Controller
Der Route Controller ist dafür verantwortlich, Routen in der Cloud so zu konfigurieren, dass Container auf verschiedenen Knoten im Kubernetes Cluster miteinander kommunizieren können. Der Route Controller ist nur auf einem Google Compute Engine Cluster anwendbar.
Service Controller
Der Service Controller ist verantwortlich für das Abhören von Ereignissen zum Erstellen, Aktualisieren und Löschen von Diensten. Basierend auf dem aktuellen Stand der Services in Kubernetes konfiguriert es Cloud Load Balancer (wie ELB, Google LB oder Oracle Cloud Infrastructure LB), um den Zustand der Services in Kubernetes abzubilden. Darüber hinaus wird sichergestellt, dass die Service Backends für Cloud Loadbalancer auf dem neuesten Stand sind.
2. Kubelet
Der Node Controller enthält die Cloud-abhängige Funktionalität des Kubelets. Vor der Einführung des CCM war das Kubelet für die Initialisierung eines Knotens mit cloudspezifischen Details wie IP-Adressen, Regions-/Zonenbezeichnungen und Instanztypinformationen verantwortlich. Mit der Einführung des CCM wurde diese Initialisierungsoperation aus dem Kubelet in das CCM verschoben.
In diesem neuen Modell initialisiert das Kubelet einen Knoten ohne cloudspezifische Informationen. Es fügt jedoch dem neu angelegten Knoten einen Taint hinzu, der den Knoten nicht verplanbar macht, bis der CCM den Knoten mit cloudspezifischen Informationen initialisiert. Dann wird der Taint entfernt.
Plugin Mechanismus
Der Cloud Controller Manager verwendet die Go Schnittstellen, um Implementierungen aus jeder Cloud einzubinden. Konkret verwendet dieser das CloudProvider Interface, das hier definiert ist.
Die Implementierung der vier oben genannten geteiltent Controllern und einigen Scaffolding sowie die gemeinsame CloudProvider Schnittstelle bleiben im Kubernetes Kern. Cloud Provider spezifische Implementierungen werden außerhalb des Kerns aufgebaut und implementieren im Kern definierte Schnittstellen.
Weitere Informationen zur Entwicklung von Plugins findest du im Bereich Entwickeln von Cloud Controller Manager.
Autorisierung
Dieser Abschnitt beschreibt den Zugriff, den der CCM für die Ausführung seiner Operationen auf verschiedene API Objekte benötigt.
Node Controller
Der Node Controller funktioniert nur mit Node Objekten. Es benötigt vollen Zugang zu get, list, create, update, patch, watch, und delete Node Objekten.
v1/Node:
- Get
- List
- Create
- Update
- Patch
- Watch
- Delete
Route Controller
Der Route Controller horcht auf die Erstellung von Node Objekten und konfiguriert die Routen entsprechend. Es erfordert get Zugriff auf die Node Objekte.
v1/Node:
- Get
Service Controller
Der Service Controller hört auf die Service Objekt Events create, update und delete und konfiguriert dann die Endpunkte für diese Services entsprechend.
Um auf Services zuzugreifen, benötigt man list und watch Berechtigung. Um die Services zu aktualisieren, sind patch und update Zugriffsrechte erforderlich.
Um die Endpunkte für die Dienste einzurichten, benötigt der Controller Zugriff auf create, list, get, watch und update.
v1/Service:
- List
- Get
- Watch
- Patch
- Update
Sonstiges
Die Implementierung des Kerns des CCM erfordert den Zugriff auf die Erstellung von Ereignissen und zur Gewährleistung eines sicheren Betriebs den Zugriff auf die Erstellung von ServiceAccounts.
v1/Event:
- Create
- Patch
- Update
v1/ServiceAccount:
- Create
Die RBAC ClusterRole für CCM sieht wie folgt aus:
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: cloud-controller-manager
rules:
- apiGroups:
- ""
resources:
- events
verbs:
- create
- patch
- update
- apiGroups:
- ""
resources:
- nodes
verbs:
- '*'
- apiGroups:
- ""
resources:
- nodes/status
verbs:
- patch
- apiGroups:
- ""
resources:
- services
verbs:
- list
- patch
- update
- watch
- apiGroups:
- ""
resources:
- serviceaccounts
verbs:
- create
- apiGroups:
- ""
resources:
- persistentvolumes
verbs:
- get
- list
- update
- watch
- apiGroups:
- ""
resources:
- endpoints
verbs:
- create
- get
- list
- watch
- update
Anbieter Implementierung
Die folgenden Cloud Anbieter haben CCMs implementiert:
Cluster Administration
Eine vollständige Anleitung zur Konfiguration und zum Betrieb des CCM findest du hier.
3.3 - Container
3.3.1 - Images
Sie erstellen Ihr Docker Image und laden es in eine Registry hoch, bevor es in einem Kubernetes Pod referenziert werden kann.
Die image Eigenschaft eines Containers unterstüzt die gleiche Syntax wie die des docker Kommandos, inklusive privater Registries und Tags.
Aktualisieren von Images
Die Standardregel für das Herunterladen von Images ist IfNotPresent, dies führt dazu, dass das Image wird nur heruntergeladen wenn es noch nicht lokal verfügbar ist.
Wenn sie stattdessen möchten, dass ein Image immer forciert heruntergeladen wird, können sie folgendes tun:
- Die
imagePullPolicydes Containers aufAlwayssetzen. - Die
imagePullPolicyauslassen und:latestals Image Tag nutzen. - Die
imagePullPolicyund den Tag des Images auslassen. - Den AlwaysPullImages Admission Controller aktivieren.
Beachten Sie, dass Sie die Nutzung des :latest Tags vermeiden sollten. Für weitere Informationen siehe: Best Practices for Configuration.
Multi-Architektur Images mit Manifesten bauen
Das Docker Kommandozeilenwerkzeug unterstützt jetzt das Kommando docker manifest mit den Subkommandos create, annotate and push.
Diese Kommandos können dazu genutzt werden Manifeste zu bauen und diese hochzuladen.
Weitere Informationen finden sie in der Docker Dokumentation: https://docs.docker.com/edge/engine/reference/commandline/manifest/
Hier einige Beispiele wie wir dies in unserem Build - Prozess nutzen: https://cs.k8s.io/?q=docker%20manifest%20(create%7Cpush%7Cannotate)&i=nope&files=&repos=
Diese Kommandos basieren rein auf dem Docker Kommandozeileninterface und werden auch damit ausgeführt. Sie sollten entweder die Datei $HOME/.docker/config.json bearbeiten und den experimental Schlüssel auf enabled setzen, oder einfach die Umgebungsvariable DOCKER_CLI_EXPERIMENTAL auf enabled setzen, wenn Sie das Docker Kommandozeileninterface aufrufen.
Wenn mit alten Manifesten Probleme auftreten, können sie die alten Manifeste in $HOME/.docker/manifests entfernen, um von vorne zu beginnen.
Für Kubernetes selbst nutzen wir typischerweise Images mit dem Suffix -$(ARCH). Um die Abwärtskompatibilität zu erhalten, bitten wir Sie, die älteren Images mit diesen Suffixen zu generieren. Die Idee dahinter ist z.B., das pause image zu generieren, welches das Manifest für alle Architekturen hat, pause-amd64 wäre dann abwärtskompatibel zu älteren Konfigurationen, oder YAML - Dateien, die ein Image mit Suffixen hart kodiert enthalten.
Nutzung einer privaten Registry
Private Registries könnten Schlüssel erfordern um Images von ihnen herunterzuladen. Authentifizierungsdaten können auf verschiedene Weisen hinterlegt werden:
- Bei der Google Container Registry
- Je Cluster
- Automatisch in der Google Compute Engine oder Google Kubernetes Engine
- Allen Pods erlauben von der privaten Registry des Projektes lesen zu können
- Bei der Amazon Elastic Container Registry (ECR)
- IAM Rollen und Richtlinien nutzen um den Zugriff auf ECR Repositories zu kontrollieren
- Automatisch ECR Authentifizierungsdaten aktualisieren
- Bei der Oracle Cloud Infrastructure Registry (OCIR)
- IAM Rollen und Richtlinien nutzen um den Zugriff auf OCIR Repositories zu kontrollieren
- Bei der Azure Container Registry (ACR)
- Bei der IBM Cloud Container Registry
- Nodes konfigurieren sich bei einer privaten Registry authentifizieren zu können - Allen Pods erlauben von jeder konfigurierten privaten Registry lesen zu können - Setzt die Konfiguration der Nodes durch einen Cluster - Aministrator voraus
- Im Voraus heruntergeladene Images
- Alle Pods können jedes gecachte Image auf einem Node nutzen
- Setzt root - Zugriff auf allen Nodes zum Einrichten voraus
- Spezifizieren eines ImagePullSecrets auf einem Pod
- Nur Pods, die eigene Secrets tragen, haben Zugriff auf eine private Registry
Jede Option wird im Folgenden im Detail beschrieben
Bei Nutzung der Google Container Registry
Kubernetes hat eine native Unterstützung für die Google Container Registry (GCR) wenn es auf der Google Compute Engine (GCE) läuft. Wenn Sie ihren Cluster auf GCE oder der Google Kubernetes Engine betreiben, genügt es, einfach den vollen Image Namen zu nutzen (z.B. gcr.io/my_project/image:tag ).
Alle Pods in einem Cluster haben dann Lesezugriff auf Images in dieser Registry.
Das Kubelet authentifiziert sich bei GCR mit Nutzung des Google service Kontos der jeweiligen Instanz.
Das Google Servicekonto der Instanz hat einen https://www.googleapis.com/auth/devstorage.read_only, so kann es vom GCR des Projektes herunter, aber nicht hochladen.
Bei Nutzung der Amazon Elastic Container Registry
Kubernetes bietet native Unterstützung für die Amazon Elastic Container Registry, wenn Knoten AWS EC2 Instanzen sind.
Es muss einfach nur der komplette Image Name (z.B. ACCOUNT.dkr.ecr.REGION.amazonaws.com/imagename:tag) in der Pod - Definition genutzt werden.
Alle Benutzer eines Clusters, die Pods erstellen dürfen, können dann jedes der Images in der ECR Registry zum Ausführen von Pods nutzen.
Das Kubelet wird periodisch ECR Zugriffsdaten herunterladen und auffrischen, es benötigt hierfür die folgenden Berechtigungen:
ecr:GetAuthorizationTokenecr:BatchCheckLayerAvailabilityecr:GetDownloadUrlForLayerecr:GetRepositoryPolicyecr:DescribeRepositoriesecr:ListImagesecr:BatchGetImage
Voraussetzungen:
- Sie müssen Kubelet in der Version
v1.2.0nutzen. (Führen sie z.B. (e.g. run/usr/bin/kubelet --version=trueaus um die Version zu prüfen) - Sie benötigen Version
v1.3.0oder neuer wenn ihre Knoten in einer A - Region sind und sich ihre Registry in einer anderen B - Region befindet. - ECR muss in ihrer Region angeboten werden
Fehlerbehebung:
- Die oben genannten Voraussetzungen müssen erfüllt sein
- Laden sie die $REGION (z.B.
us-west-2) Zugriffsdaten auf ihren Arbeitsrechner. Verbinden sie sich per SSH auf den Host und nutzen die Docker mit diesen Daten. Funktioniert es? - Prüfen sie ob das Kubelet it dem Parameter
--cloud-provider=awsläuft. - Prüfen sie die Logs des Kubelets (z.B. mit
journalctl -u kubelet) auf Zeilen wie:plugins.go:56] Registering credential provider: aws-ecr-keyprovider.go:91] Refreshing cache for provider: *aws_credentials.ecrProvider
Bei Nutzung der Azure Container Registry (ACR)
Bei Nutzung der Azure Container Registry können sie sich entweder als ein administrativer Nutzer, oder als ein Service Principal authentifizieren. In jedem Fall wird die Authentifizierung über die Standard - Docker Authentifizierung ausgeführt. Diese Anleitung bezieht sich auf das azure-cli Kommandozeilenwerkzeug.
Sie müssen zunächst eine Registry und Authentifizierungsdaten erstellen, eine komplette Dokumentation dazu finden sie hier: Azure container registry documentation.
Sobald sie ihre Container Registry erstellt haben, nutzen sie die folgenden Authentifizierungsdaten:
DOCKER_USER: Service Principal oder AdministratorbenutzernameDOCKER_PASSWORD: Service Principal Password oder AdministratorpasswortDOCKER_REGISTRY_SERVER:${some-registry-name}.azurecr.ioDOCKER_EMAIL:${some-email-address}
Wenn sie diese Variablen befüllt haben, können sie: Kubernetes konfigurieren und damit einen Pod deployen.
Bei Nutzung der IBM Cloud Container Registry
Die IBM Cloud Container Registry bietet eine mandantenfähige Private Image Registry, die Sie nutzen können, um ihre Docker Images sicher zu speichern und zu teilen. Standardmäßig werden Images in ihrer Private Registry vom integrierten Schwachstellenscaner durchsucht, um Sicherheitsprobleme und potentielle Schwachstellen zu finden. Benutzer können ihren IBM Cloud Account nutzen, um Zugang zu ihren Images zu erhalten, oder um einen Token zu generieren, der Zugriff auf die Registry Namespaces erlaubt.
Um das IBM Cloud Container Registry Kommandozeilenwerkzeug zu installieren und einen Namespace für ihre Images zu erstellen, folgen sie dieser Dokumentation Getting started with IBM Cloud Container Registry.
Sie können die IBM Cloud Container Registry nutzen, um Container aus IBM Cloud public images und ihren eigenen Images in den default Namespace ihres IBM Cloud Kubernetes Service Clusters zu deployen.
Um einen Container in einen anderen Namespace, oder um ein Image aus einer anderen IBM Cloud Container Registry Region oder einem IBM Cloud account zu deployen, erstellen sie ein Kubernetes imagePullSecret.
Weitere Informationen finden sie unter: Building containers from images.
Knoten für die Nutzung einer Private Registry konfigurieren
.dockercfg auf jedem Knoten, die Zugriffsdaten für ihre Google Container Registry beinhaltet. Dann kann die folgende Vorgehensweise nicht angewendet werden.
auths und HttpHeaders Abschnitte der Dockerkonfiguration. Das bedeutet, dass die Hilfswerkzeuge (credHelpers ooderr credsStore) nicht unterstützt werden.
Docker speichert Schlüssel für eigene Registries entweder unter $HOME/.dockercfg oder $HOME/.docker/config.json. Wenn sie die gleiche Datei in einen der unten aufgeführten Suchpfade speichern, wird Kubelet sie als Hilfswerkzeug für Zugriffsdaten beim Beziehen von Images nutzen.
{--root-dir:-/var/lib/kubelet}/config.json{cwd of kubelet}/config.json${HOME}/.docker/config.json/.docker/config.json{--root-dir:-/var/lib/kubelet}/.dockercfg{cwd of kubelet}/.dockercfg${HOME}/.dockercfg/.dockercfg
HOME=/root in ihrer Umgebungsvariablendatei setzen.
Dies sind die empfohlenen Schritte, um ihre Knoten für eine Nutzung einer eigenen Registry zu konfigurieren. In diesem Beispiel führen sie folgende Schritte auf ihrem Desktop/Laptop aus:
- Führen sie
docker login [server]für jeden Satz ihrer Zugriffsdaten aus. Dies aktualisiert$HOME/.docker/config.json. - Prüfen Sie
$HOME/.docker/config.jsonin einem Editor darauf, ob dort nur Zugriffsdaten enthalten sind, die Sie nutzen möchten. - Erhalten sie eine Liste ihrer Knoten:
- Wenn sie die Namen benötigen:
nodes=$(kubectl get nodes -o jsonpath='{range.items[*].metadata}{.name} {end}') - Wenn sie die IP - Adressen benötigen:
nodes=$(kubectl get nodes -o jsonpath='{range .items[*].status.addresses[?(@.type=="ExternalIP")]}{.address} {end}')
- Wenn sie die Namen benötigen:
- Kopieren sie ihre lokale
.docker/config.jsonin einen der oben genannten Suchpfade.- Zum Beispiel:
for n in $nodes; do scp ~/.docker/config.json root@$n:/var/lib/kubelet/config.json; done
- Zum Beispiel:
Prüfen durch das Erstellen eines Pods, der ein eigenes Image nutzt, z.B.:
kubectl apply -f - <<EOF
apiVersion: v1
kind: Pod
metadata:
name: private-image-test-1
spec:
containers:
- name: uses-private-image
image: $PRIVATE_IMAGE_NAME
imagePullPolicy: Always
command: [ "echo", "SUCCESS" ]
EOF
pod/private-image-test-1 created
Wenn alles funktioniert, sollten sie nach einigen Momenten folgendes sehen:
kubectl logs private-image-test-1
SUCCESS
Wenn es nicht funktioniert, sehen Sie:
kubectl describe pods/private-image-test-1 | grep "Failed"
Fri, 26 Jun 2015 15:36:13 -0700 Fri, 26 Jun 2015 15:39:13 -0700 19 {kubelet node-i2hq} spec.containers{uses-private-image} failed Failed to pull image "user/privaterepo:v1": Error: image user/privaterepo:v1 not found
Sie müssen sich darum kümmern, dass alle Knoten im Cluster die gleiche .docker/config.json haben, andernfalls werden Pods auf einigen Knoten starten, auf anderen jedoch nicht.
Wenn sie zum Beispiel Knoten automatisch skalieren lassen, sollte dann jedes Instanztemplate die .docker/config.json beinhalten, oder ein Laufwerk einhängen, das diese beinhaltet.
Alle Pods haben Lesezugriff auf jedes Image in ihrer eigenen Registry, sobald die Registry - Schlüssel zur .docker/config.json hinzugefügt wurden.
Im Voraus heruntergeladene Images
.dockercfg auf jedem Knoten die Zugriffsdaten für ihre Google Container Registry beinhaltet. Dann kann die folgende Vorgehensweise nicht angewendet werden.
Standardmäßig wird das Kubelet versuchen, jedes Image von der spezifizierten Registry herunterzuladen.
Falls jedoch die imagePullPolicy Eigenschaft der Containers auf IfNotPresent oder Never gesetzt wurde, wird ein lokales Image genutzt (präferiert oder exklusiv, jenachdem).
Wenn Sie sich auf im Voraus heruntergeladene Images als Ersatz für eine Registry - Authentifizierung verlassen möchten, müssen sie sicherstellen, dass alle Knoten die gleichen, im Voraus heruntergeladenen Images aufweisen.
Diese Methode kann dazu genutzt werden, bestimmte Images aus Geschwindigkeitsgründen im Voraus zu laden, oder als Alternative zur Authentifizierung an einer eigenen Registry zu nutzen.
Alle Pods haben Leserechte auf alle im Voraus geladenen Images.
Spezifizieren eines ImagePullSecrets für einen Pod
Kubernetes unterstützt die Spezifikation von Registrierungsschlüsseln für einen Pod.
Erstellung eines Secrets mit einer Docker Konfiguration
Führen sie folgenden Befehl mit Ersetzung der groß geschriebenen Werte aus:
kubectl create secret docker-registry <name> --docker-server=DOCKER_REGISTRY_SERVER --docker-username=DOCKER_USER --docker-password=DOCKER_PASSWORD --docker-email=DOCKER_EMAIL
Wenn Sie bereits eine Datei mit Docker-Zugriffsdaten haben, können Sie die Zugriffsdaten als ein Kubernetes Secret importieren:
Create a Secret based on existing Docker credentials beschreibt die Erstellung.
Dies ist insbesondere dann sinnvoll, wenn sie mehrere eigene Container Registries nutzen, da kubectl create secret docker-registry ein Secret erstellt, das nur mit einer einzelnen eigenen Registry funktioniert.
Referenzierung eines imagePullSecrets bei einem Pod
Nun können Sie Pods erstellen, die dieses Secret referenzieren, indem Sie einen Abschnitt imagePullSecrets zu ihrer Pod - Definition hinzufügen.
cat <<EOF > pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: foo
namespace: awesomeapps
spec:
containers:
- name: foo
image: janedoe/awesomeapp:v1
imagePullSecrets:
- name: myregistrykey
EOF
cat <<EOF >> ./kustomization.yaml
resources:
- pod.yaml
EOF
Dies muss für jeden Pod getan werden, der eine eigene Registry nutzt.
Die Erstellung dieser Sektion kann jedoch automatisiert werden, indem man imagePullSecrets einer serviceAccount Ressource hinzufügt. Add ImagePullSecrets to a Service Account bietet detaillierte Anweisungen hierzu.
Sie können dies in Verbindung mit einer auf jedem Knoten genutzten .docker/config.json benutzen, die Zugriffsdaten werden dann zusammengeführt. Dieser Vorgehensweise wird in der Google Kubernetes Engine funktionieren.
Anwendungsfälle
Es gibt eine Anzahl an Lösungen um eigene Registries zu konfigurieren, hier sind einige Anwendungsfälle und empfohlene Lösungen.
- Cluster die nur nicht-proprietäre Images (z.B. open-source) ausführen. Images müssen nicht versteckt werden.
- Nutzung von öffentlichen Images auf Docker Hub.
- Keine Konfiguration notwendig.
- Auf GCE/Google Kubernetes Engine, wird automatisch ein lokaler Spiegel für eine verbesserte Geschwindigkeit und Verfügbarkeit genutzt.
- Nutzung von öffentlichen Images auf Docker Hub.
- Cluster die einige proprietäre Images ausführen die für Außenstehende nicht sichtbar sein dürfen, aber für alle Cluster - Benutzer sichtbar sein sollen.
- Nutzung einer gehosteten privaten Registry Docker registry.
- Kann auf Docker Hub, oder woanders gehostet werden.
- Manuelle Konfiguration der .docker/config.json auf jedem Knoten, wie oben beschrieben.
- Der Betrieb einer internen privaten Registry hinter ihrer Firewall mit offenen Leseberechtigungen.
- Keine Kubernetes - Konfiguration notwendig
- Wenn GCE/Google Kubernetes Engine genutzt wird, nutzen sie die Google Container Registry des Projektes.
- Funktioniert besser mit Cluster - Autoskalierung als mit manueller Knotenkonfiguration.
- Auf einem Cluster bei dem die Knotenkonfiguration ungünstig ist können
imagePullSecretsgenutzt werden.
- Nutzung einer gehosteten privaten Registry Docker registry.
- Cluster mit proprieritären Images, mit einigen Images die eine erweiterte Zugriffskontrolle erfordern.
- Stellen sie sicher das AlwaysPullImages admission controller aktiv ist, anderenfalls können alle Pods potenziell Zugriff auf alle Images haben.
- Verschieben sie sensitive Daten in eine "Secret" Ressource statt sie im Image abzulegen.
- Ein mandantenfähiger Cluster in dem jeder Mandant eine eigene private Registry benötigt.
- Stellen sie dicher das AlwaysPullImages admission controller aktiv ist, anderenfalls können alle Pods potenziell Zugriff auf alle Images haben.
- Nutzen sie eine private Registry die eine Authorisierung erfordert.
- Generieren die Registry - Zugriffsdaten für jeden Mandanten, abgelegt in einem Secret das in jedem Mandanten - Namespace vorhanden ist.
- Der Mandant fügt dieses Sercret zu den imagePullSecrets in jedem seiner Namespace hinzu.
Falls die Zugriff auf mehrere Registries benötigen, können sie ein Secret für jede Registry erstellen, Kubelet wird jedwede imagePullSecrets in einer einzelnen .docker/config.json zusammenfassen.
3.4 - Workloads
3.4.1 - Deployments
3.4.2 - Pods
Pods sind die kleinsten einsetzbaren Einheiten, die in Kubernetes erstellt und verwaltet werden können.
Ein Pod (übersetzt Gruppe/Schote, wie z. B. eine Gruppe von Walen oder eine Erbsenschote) ist eine Gruppe von einem oder mehreren Containern mit gemeinsam genutzten Speicher- und Netzwerkressourcen und einer Spezifikation für die Ausführung der Container. Die Ressourcen eines Pods befinden sich immer auf dem gleichen (virtuellen) Server, werden gemeinsam geplant und in einem gemeinsamen Kontext ausgeführt. Ein Pod modelliert einen anwendungsspezifischen "logischen Server": Er enthält eine oder mehrere containerisierte Anwendungen, die relativ stark voneinander abhängen. In Nicht-Cloud-Kontexten sind Anwendungen, die auf demselben physischen oder virtuellen Server ausgeführt werden, vergleichbar zu Cloud-Anwendungen, die auf demselben logischen Server ausgeführt werden.
Ein Pod kann neben Anwendungs-Containern auch sogenannte Initialisierungs-Container enthalten, die beim Starten des Pods ausgeführt werden. Es können auch kurzlebige/ephemere Container zum Debuggen gestartet werden, wenn dies der Cluster anbietet.
Was ist ein Pod?
Der gemeinsame Kontext eines Pods besteht aus einer Reihe von Linux-Namespaces, Cgroups und möglicherweise anderen Aspekten der Isolation, also die gleichen Dinge, die einen Dockercontainer isolieren. Innerhalb des Kontexts eines Pods können die einzelnen Anwendungen weitere Unterisolierungen haben.
Im Sinne von Docker-Konzepten ähnelt ein Pod einer Gruppe von Docker-Containern, die gemeinsame Namespaces und Dateisystem-Volumes nutzen.
Pods verwenden
Normalerweise müssen keine Pods erzeugt werden, auch keine Singleton-Pods. Stattdessen werden sie mit Workload-Ressourcen wie Deployment oder Job erzeugt. Für Pods, die von einem Systemzustand abhängen, ist die Nutzung von StatefulSet-Ressourcen zu erwägen.
Pods in einem Kubernetes-Cluster werden hauptsächlich auf zwei Arten verwendet:
- Pods, die einen einzelnen Container ausführen. Das "Ein-Container-per-Pod"-Modell ist der häufigste Kubernetes-Anwendungsfall. In diesem Fall kannst du dir einen einen Pod als einen Behälter vorstellen, der einen einzelnen Container enthält; Kubernetes verwaltet die Pods anstatt die Container direkt zu verwalten.
- Pods, in denen mehrere Container ausgeführt werden, die zusammenarbeiten müssen. Wenn eine Softwareanwendung aus co-lokaliserten Containern besteht, die sich gemeinsame Ressourcen teilen und stark voneinander abhängen, kann ein Pod die Container verkapseln. Diese Container bilden eine einzelne zusammenhängende Serviceeinheit, z. B. ein Container, der Daten in einem gemeinsam genutzten Volume öffentlich verfügbar macht, während ein separater Sidecar-Container die Daten aktualisiert. Der Pod fasst die Container, die Speicherressourcen und eine kurzlebige Netzwerk-Identität als eine Einheit zusammen.
Jeder Pod sollte eine einzelne Instanz einer gegebenen Anwendung ausführen. Wenn du deine Anwendung horizontal skalieren willst (um mehr Instanzen auszuführen und dadurch mehr Gesamtressourcen bereitstellen), solltest du mehrere Pods verwenden, einen für jede Instanz. In Kubernetes wird dies typischerweise als Replikation bezeichnet. Replizierte Pods werden normalerweise als eine Gruppe durch eine Workload-Ressource und deren Controller erstellt und verwaltet.
Der Abschnitt Pods und Controller beschreibt, wie Kubernetes Workload-Ressourcen und deren Controller verwendet, um Anwendungen zu skalieren und zu heilen.
Wie Pods mehrere Container verwalten
Pods unterstützen mehrere kooperierende Prozesse (als Container), die eine zusammenhängende Serviceeinheit bilden. Kubernetes plant und stellt automatisch sicher, dass sich die Container in einem Pod auf demselben physischen oder virtuellen Server im Cluster befinden. Die Container können Ressourcen und Abhängigkeiten gemeinsam nutzen, miteinander kommunizieren und ferner koordinieren wann und wie sie beendet werden.
Zum Beispiel könntest du einen Container haben, der als Webserver für Dateien in einem gemeinsamen Volume arbeitet. Und ein separater "Sidecar" -Container aktualisiert die Daten von einer externen Datenquelle, siehe folgenden Abbildung:

Einige Pods haben sowohl Initialisierungs-Container als auch Anwendungs-Container. Initialisierungs-Container werden gestartet und beendet bevor die Anwendungs-Container gestartet werden.
Pods stellen standardmäßig zwei Arten von gemeinsam Ressourcen für die enthaltenen Container bereit: Netzwerk und Speicher.
Mit Pods arbeiten
Du wirst selten einzelne Pods direkt in Kubernetes erstellen, selbst Singleton-Pods. Das liegt daran, dass Pods als relativ kurzlebige Einweg-Einheiten konzipiert sind. Wenn ein Pod erstellt wird (entweder direkt von Ihnen oder indirekt von einem Controller), wird die Ausführung auf einem Node in Ihrem Cluster geplant. Der Pod bleibt auf diesem (virtuellen) Server, bis entweder der Pod die Ausführung beendet hat, das Pod-Objekt gelöscht wird, der Pod aufgrund mangelnder Ressourcen evakuiert wird oder der Node ausfällt.
Stelle beim Erstellen des Manifests für ein Pod-Objekt sicher, dass der angegebene Name ein gültiger DNS-Subdomain-Name ist.
Pods und Controller
Mit Workload-Ressourcen kannst du mehrere Pods erstellen und verwalten. Ein Controller für die Ressource kümmert sich um Replikation, Roll-Out sowie automatische Wiederherstellung im Fall von versagenden Pods. Wenn beispielsweise ein Node ausfällt, bemerkt ein Controller, dass die Pods auf dem Node nicht mehr laufen und plant die Ausführung eines Ersatzpods auf einem funktionierenden Node. Hier sind einige Beispiele für Workload-Ressourcen, die einen oder mehrere Pods verwalten:
Pod-Vorlagen
Controller für Workload-Ressourcen erstellen Pods von einer Pod-Vorlage und verwalten diese Pods für dich.
Pod-Vorlagen sind Spezifikationen zum Erstellen von Pods und sind in Workload-Ressourcen enthalten wie z. B. Deployments, Jobs, and DaemonSets.
Jeder Controller für eine Workload-Ressource verwendet die Pod-Vorlage innerhalb des Workload-Objektes, um Pods zu erzeugen. Die Pod-Vorlage ist Teil des gewünschten Zustands der Workload-Ressource, mit der du deine Anwendung ausgeführt hast.
Das folgende Beispiel ist ein Manifest für einen einfachen Job mit einer
Vorlage, die einen Container startet. Der Container in diesem Pod druckt
eine Nachricht und pausiert dann.
apiVersion: batch/v1
kind: Job
metadata:
name: hello
spec:
template:
# Dies is the Pod-Vorlage
spec:
containers:
- name: hello
image: busybox
command: ['sh', '-c', 'echo "Hello, Kubernetes!" && sleep 3600']
restartPolicy: OnFailure
# Die Pod-Vorlage endet hier
Das Ändern der Pod-Vorlage oder der Wechsel zu einer neuen Pod-Vorlage hat keine direkten Auswirkungen auf bereits existierende Pods. Wenn du die Pod-Vorlage für eine Workload-Ressource änderst, dann muss diese Ressource die Ersatz-Pods erstellen, welche die aktualisierte Vorlage verwenden.
Beispielsweise stellt der StatefulSet-Controller sicher, dass für jedes StatefulSet-Objekt die ausgeführten Pods mit der aktueller Pod-Vorlage übereinstimmen. Wenn du das StatefulSet bearbeitest und die Vorlage änderst, beginnt das StatefulSet mit der Erstellung neuer Pods basierend auf der aktualisierten Vorlage. Schließlich werden alle alten Pods durch neue Pods ersetzt, und das Update ist abgeschlossen.
Jede Workload-Ressource implementiert eigenen Regeln für die Umsetzung von Änderungen der Pod-Vorlage. Wenn du mehr über StatefulSet erfahren möchtest, dann lese die Seite Update-Strategien im Tutorial StatefulSet Basics.
Auf Nodes beobachtet oder verwaltet das Kubelet nicht direkt die Details zu Pod-Vorlagen und Updates. Diese Details sind abstrahiert. Die Abstraktion und Trennung von Aufgaben vereinfacht die Systemsemantik und ermöglicht so das Verhalten des Clusters zu ändern ohne vorhandenen Code zu ändern.
Pod Update und Austausch
Wie im vorherigen Abschnitt erwähnt, erstellt der Controller neue Pods basierend auf der aktualisierten Vorlage, wenn die Pod-Vorlage für eine Workload-Ressource geändert wird anstatt die vorhandenen Pods zu aktualisieren oder zu patchen.
Kubernetes hindert dich nicht daran, Pods direkt zu verwalten. Es ist möglich,
einige Felder eines laufenden Pods zu aktualisieren. Allerdings haben
Pod-Aktualisierungsvorgänge wie zum Beispiel
patch,
und
replace
einige Einschränkungen:
-
Die meisten Metadaten zu einem Pod können nicht verändert werden. Zum Beispiel kannst du nicht die Felder
namespace,name,uid, odercreationTimestampändern. Dasgeneration-Feld muss eindeutig sein. Es werden nur Aktualisierungen akzeptiert, die den Wert des Feldes inkrementieren. -
Wenn das Feld
metadata.deletionTimestampgesetzt ist, kann kein neuer Eintrag zur Listemetadata.finalizershinzugefügt werden. -
Pod-Updates dürfen keine Felder ändern, die Ausnahmen sind
spec.containers[*].image,spec.initContainers[*].image,spec.activeDeadlineSecondsoderspec.tolerations. Fürspec.tolerationskannnst du nur neue Einträge hinzufügen. -
Für
spec.activeDeadlineSecondssind nur zwei Änderungen erlaubt:- ungesetztes Feld in eine positive Zahl
- positive Zahl in eine kleinere positive Zahl, die nicht negativ ist
Gemeinsame Nutzung von Ressourcen und Kommunikation
Pods ermöglichen den Datenaustausch und die Kommunikation zwischen den Containern, die im Pod enthalten sind.
Datenspeicherung in Pods
Ein Pod kann eine Reihe von gemeinsam genutzten Speicher- Volumes spezifizieren. Alle Container im Pod können auf die gemeinsamen Volumes zugreifen und dadurch Daten austauschen. Volumes ermöglichen auch, dass Daten ohne Verlust gespeichert werden, falls einer der Container neu gestartet werden muss. Im Kapitel Datenspeicherung findest du weitere Informationen, wie Kubernetes gemeinsam genutzten Speicher implementiert und Pods zur Verfügung stellt.
Pod-Netzwerk
Jedem Pod wird für jede Adressenfamilie eine eindeutige IP-Adresse zugewiesen.
Jeder Container in einem Pod nutzt den gemeinsamen Netzwerk-Namespace,
einschließlich der IP-Adresse und der Ports. In einem Pod (und nur dann)
können die Container, die zum Pod gehören, über localhost miteinander
kommunizieren. Wenn Container in einem Pod mit Entitäten außerhalb des Pods
kommunizieren, müssen sie koordinieren, wie die gemeinsam genutzten
Netzwerkressourcen (z. B. Ports) verwenden werden. Innerhalb eines Pods teilen
sich Container eine IP-Adresse und eine Reihe von Ports und können sich
gegenseitig über localhost finden. Die Container in einem Pod können auch die
üblichen Kommunikationsverfahren zwischen Prozessen nutzen, wie z. B.
SystemV-Semaphoren oder "POSIX Shared Memory". Container in verschiedenen Pods
haben unterschiedliche IP-Adressen und können nicht per IPC ohne
spezielle Konfiguration
kommunizieren. Container, die mit einem Container in einem anderen Pod
interagieren möchten, müssen IP Netzwerke verwenden.
Für die Container innerhalb eines Pods stimmt der "hostname" mit dem
konfigurierten Namen des Pods überein. Mehr dazu im Kapitel
Netzwerke.
Privilegierter Modus für Container
Jeder Container in einem Pod kann den privilegierten Modus aktivieren, indem
das Flag privileged im
Sicherheitskontext
der Container-Spezifikation verwendet wird.
Dies ist nützlich für Container, die Verwaltungsfunktionen des Betriebssystems
verwenden möchten, z. B. das Manipulieren des Netzwerk-Stacks oder den Zugriff
auf Hardware. Prozesse innerhalb eines privilegierten Containers erhalten fast
die gleichen Rechte wie sie Prozessen außerhalb eines Containers zur Verfügung
stehen.
Statische Pods
Statische Pods werden direkt vom Kubelet-Daemon auf einem bestimmten Node verwaltet ohne dass sie vom API Server überwacht werden.
Die meisten Pods werden von der Kontrollebene verwaltet (z. B. Deployment). Aber für statische Pods überwacht das Kubelet jeden statischen Pod direkt (und startet ihn neu, wenn er ausfällt).
Statische Pods sind immer an ein Kubelet auf einem bestimmten Node gebunden. Der Hauptanwendungsfall für statische Pods besteht darin, eine selbst gehostete Steuerebene auszuführen. Mit anderen Worten: Das Kubelet dient zur Überwachung der einzelnen Komponenten der Kontrollebene.
Das Kubelet versucht automatisch auf dem Kubernetes API-Server für jeden statischen Pod einen spiegelbildlichen Pod (im Englischen: mirror pod) zu erstellen. Das bedeutet, dass die auf einem Node ausgeführten Pods auf dem API-Server sichtbar sind jedoch von dort nicht gesteuert werden können.
Nächste Schritte
- Verstehe den Lebenszyklus eines Pods.
- Erfahre mehr über RuntimeClass und wie du damit verschiedene Pods mit unterschiedlichen Container-Laufzeitumgebungen konfigurieren kannst.
- Mehr zum Thema Restriktionen für die Verteilung von Pods.
- Lese Pod-Disruption-Budget und wie du es verwenden kannst, um die Verfügbarkeit von Anwendungen bei Störungen zu verwalten. Die Pod -Objektdefinition beschreibt das Objekt im Detail.
- The Distributed System Toolkit: Patterns for Composite Containers erläutert allgemeine Layouts für Pods mit mehr als einem Container.
Um den Hintergrund zu verstehen, warum Kubernetes eine gemeinsame Pod-API in andere Ressourcen, wie z. B. StatefulSets oder Deployments einbindet, kannst du Artikel zu früheren Technologien lesen, unter anderem:
3.4.3 - ReplicaSet
3.4.4 - Jobs
3.5 - Dienste, Lastverteilung und Netzwerkfunktionen
3.5.1 - Services
3.5.2 - IPv4/IPv6 dual-stack
3.6 - Speicher
3.6.1 - Persistente Volumes
3.7 - Konfiguration
3.7.1 - Secrets
3.7.2 - Resourcen-Verwaltung für Pods und Container
3.8 - Richtlinien
3.9 - Cluster Administration
3.9.1 - Proxies in Kubernetes
Auf dieser Seite werden die im Kubernetes verwendeten Proxies erläutert.
Proxies
Es gibt mehrere verschiedene Proxies, die die bei der Verwendung von Kubernetes begegnen können:
-
Der kubectl Proxy:
- läuft auf dem Desktop eines Benutzers oder in einem Pod
- Proxy von einer lokalen Host-Adresse zum Kubernetes API Server
- Client zu Proxy verwendet HTTP
- Proxy zu API Server verwendet HTTPS
- lokalisiert den API Server
- fügt Authentifizierungs-Header hinzu
-
Der API Server Proxy:
- ist eine Bastion, die in den API Server eingebaut ist
- verbindet einen Benutzer außerhalb des Clusters mit Cluster IPs, die sonst möglicherweise nicht erreichbar wären
- läuft im API Server Prozess
- Client zu Proxy verwendet HTTPS (oder http, wenn API Server so konfiguriert ist)
- Proxy zum Ziel kann HTTP oder HTTPS verwenden, der Proxy wählt dies unter Verwendung der verfügbaren Informationen aus
- kann verwendet werden, um einen Knoten, Pod oder Service zu erreichen
- führt einen Lastausgleich durch um einen Service zu erreichen, wenn dieser verwendet wird
-
Der kube Proxy:
- läuft auf jedem Knoten
- Proxy unterstüzt UDP, TCP und SCTP
- versteht kein HTTP
- stellt Lastausgleich zur Verfügung
- wird nur zum erreichen von Services verwendet
-
Ein Proxy/Load-balancer vor dem API Server:
- Existenz und Implementierung variieren von Cluster zu Cluster (z.B. nginx)
- sitzt zwischen allen Clients und einem oder mehreren API Servern
- fungiert als Load Balancer, wenn es mehrere API Server gibt
-
Cloud Load Balancer für externe Services:
- wird von einigen Cloud Anbietern angeboten (z.B. AWS ELB, Google Cloud Load Balancer)
- werden automatisch erstellt, wenn der Kubernetes Service den Typ
LoadBalancerhat - unterstützt normalerweiße nur UDP/TCP
- Die SCTP-Unterstützung hängt von der Load Balancer Implementierung des Cloud Providers ab
- die Implementierung variiert je nach Cloud Anbieter
Kubernetes Benutzer müssen sich in der Regel um nichts anderes als die ersten beiden Typen kümmern. Der Cluster Administrator stellt in der Regel sicher, dass die letztgenannten Typen korrekt eingerichtet sind.
Anforderung an Umleitungen
Proxies haben die Möglichkeit der Umleitung (redirect) ersetzt. Umleitungen sind veraltet.
3.9.2 - Controller Manager Metriken
Controller Manager Metriken liefern wichtige Erkenntnisse über die Leistung und den Zustand von den Controller Managern.
Was sind Controller Manager Metriken
Die Kennzahlen des Controller Managers liefert wichtige Erkenntnisse über die Leistung und den Zustand des Controller Managers. Diese Metriken beinhalten gängige Go Language Laufzeitmetriken wie go_routine count und controller-spezifische Metriken wie z.B. etcd Request Latenzen oder Cloud Provider (AWS, GCE, OpenStack) API Latenzen, die verwendet werden können um den Zustand eines Clusters zu messen.
Ab Kubernetes 1.7 stehen detaillierte Cloud Provider Metriken für den Speicherbetrieb für GCE, AWS, Vsphere und OpenStack zur Verfügung. Diese Metriken können verwendet werden, um den Zustand persistenter Datenträgeroperationen zu überwachen.
Für GCE werden diese Metriken beispielsweise wie folgt aufgerufen:
cloudprovider_gce_api_request_duration_seconds { request = "instance_list"}
cloudprovider_gce_api_request_duration_seconds { request = "disk_insert"}
cloudprovider_gce_api_request_duration_seconds { request = "disk_delete"}
cloudprovider_gce_api_request_duration_seconds { request = "attach_disk"}
cloudprovider_gce_api_request_duration_seconds { request = "detach_disk"}
cloudprovider_gce_api_request_duration_seconds { request = "list_disk"}
Konfiguration
In einem Cluster sind die Controller Manager Metriken unter http://localhost:10252/metrics auf dem Host verfügbar, auf dem der Controller Manager läuft.
Die Metriken werden im Prometheus Format ausgegeben.
In einer Produktionsumgebung können Sie Prometheus oder einen anderen Metrik Scraper konfigurieren, um diese Metriken regelmäßig zu sammeln und in einer Art Zeitreihen Datenbank verfügbar zu machen.
3.9.3 - Addons Installieren
Add-Ons erweitern die Funktionalität von Kubernetes.
Diese Seite gibt eine Übersicht über einige verfügbare Add-Ons und verweist auf die entsprechenden Installationsanleitungen.
Die Add-Ons in den einzelnen Kategorien sind alphabetisch sortiert - Die Reihenfolge impliziert keine bevorzugung einzelner Projekte.
Networking und Network Policy
- ACI bietet Container-Networking und Network-Security mit Cisco ACI.
- Calico ist ein Networking- und Network-Policy-Provider. Calico unterstützt eine Reihe von Networking-Optionen, damit Du die richtige für deinen Use-Case wählen kannst. Dies beinhaltet Non-Overlaying and Overlaying-Networks mit oder ohne BGP. Calico nutzt die gleiche Engine um Network-Policies für Hosts, Pods und (falls Du Istio & Envoy benutzt) Anwendungen auf Service-Mesh-Ebene durchzusetzen.
- Canal vereint Flannel und Calico um Networking- und Network-Policies bereitzustellen.
- Cilium ist ein L3 Network- and Network-Policy-Plugin welches das transparent HTTP/API/L7-Policies durchsetzen kann. Sowohl Routing- als auch Overlay/Encapsulation-Modes werden uterstützt. Außerdem kann Cilium auf andere CNI-Plugins aufsetzen.
- CNI-Genie ermöglicht das nahtlose Verbinden von Kubernetes mit einer Reihe an CNI-Plugins wie z.B. Calico, Canal, Flannel, Romana, oder Weave.
- Contiv bietet konfigurierbares Networking (Native L3 auf BGP, Overlay mit vxlan, Klassisches L2, Cisco-SDN/ACI) für verschiedene Anwendungszwecke und auch umfangreiches Policy-Framework. Das Contiv-Projekt ist vollständig Open Source. Der installer bietet sowohl kubeadm als auch nicht-kubeadm basierte Installationen.
- Contrail, basierend auf Tungsten Fabric, ist eine Open Source, multi-Cloud Netzwerkvirtualisierungs- und Policy-Management Plattform. Contrail und Tungsten Fabric sind mit Orechstratoren wie z.B. Kubernetes, OpenShift, OpenStack und Mesos integriert und bieten Isolationsmodi für Virtuelle Maschinen, Container (bzw. Pods) und Bare Metal workloads.
- Flannel ist ein Overlay-Network-Provider der mit Kubernetes genutzt werden kann.
- Knitter ist eine Network-Lösung die Mehrfach-Network in Kubernetes ermöglicht.
- Multus ist ein Multi-Plugin für Mehrfachnetzwerk-Unterstützung um alle CNI-Plugins (z.B. Calico, Cilium, Contiv, Flannel), zusätzlich zu SRIOV-, DPDK-, OVS-DPDK- und VPP-Basierten Workloads in Kubernetes zu unterstützen.
- NSX-T Container Plug-in (NCP) bietet eine Integration zwischen VMware NSX-T und einem Orchestator wie z.B. Kubernetes. Außerdem bietet es eine Integration zwischen NSX-T und Containerbasierten CaaS/PaaS-Plattformen wie z.B. Pivotal Container Service (PKS) und OpenShift.
- Nuage ist eine SDN-Plattform die Policy-Basiertes Networking zwischen Kubernetes Pods und nicht-Kubernetes Umgebungen inklusive Sichtbarkeit und Security-Monitoring bereitstellt.
- Romana ist eine Layer 3 Network-Lösung für Pod-Netzwerke welche auch die NetworkPolicy API unterstützt. Details zur Installation als kubeadm Add-On sind hier verfügbar.
- Weave Net bietet Networking and Network-Policies und arbeitet auf beiden Seiten der Network-Partition ohne auf eine externe Datenbank angwiesen zu sein.
Service-Discovery
- CoreDNS ist ein flexibler, erweiterbarer DNS-Server der in einem Cluster installiert werden kann und das Cluster-interne DNS für Pods bereitzustellen.
Visualisierung & Überwachung
- Dashboard ist ein Dashboard Web Interface für Kubernetes.
- Weave Scope ist ein Tool um Container, Pods, Services usw. Grafisch zu visualieren. Kann in Verbindung mit einem Weave Cloud Account genutzt oder selbst gehosted werden.
Infrastruktur
- KubeVirt ist ein Add-On um Virtuelle Maschinen in Kubernetes auszuführen. Wird typischer auf Bare-Metal Clustern eingesetzt.
Legacy Add-Ons
Es gibt einige weitere Add-Ons die in dem abgekündigten cluster/addons-Verzeichnis dokumentiert sind.
Add-Ons die ordentlich gewartet werden dürfen gerne hier aufgezählt werden. Wir freuen uns auf PRs!
3.10 - Kubernetes erweitern
3.11 - Konzept Dokumentations-Vorlage
Diese Seite erklärt ...
Verstehen ...
Kubernetes bietet ...
Verwenden ...
Benutzen Sie ...
Nächste Schritte
[Optionaler Bereich]
- Lernen Sie mehr über ein neues Thema schreiben.
- Besuchen Sie Seitenvorlagen verwenden - Konzeptvorlage wie Sie diese Vorlage verwenden.
4 - Aufgaben
Dieser Abschnitt der Kubernetes-Dokumentation enthält Seiten, die zeigen, wie man einzelne Aufgaben erledigt. Eine Aufgabenseite zeigt, wie man eine einzelne Aufgabe ausführt, typischerweise durch eine kurze Abfolge von Schritten.
Webbenutzeroberfläche (Dashboard)
Stellen Sie die Dashboard-Webbenutzeroberfläche bereit, und greifen Sie auf sie zu, um Sie bei der Verwaltung und Überwachung von Containeranwendungen in einem Kubernetes-Cluster zu unterstützen.
Die kubectl-Befehlszeile verwenden
Installieren und konfigurieren Sie das kubectl-Befehlszeilentool, mit dem Kubernetes-Cluster direkt verwaltet werden.
Pods und Container konfigurieren
Ausführen allgemeiner Konfigurationsaufgaben für Pods und Container.
Anwendungen ausführen
Ausführen allgemeiner Aufgaben zur Anwendungsverwaltung, z. B. Aktualisierungen, Einfügen von Informationen in Pods und automatisches horizontales Skalieren der Pods.
Jobs ausführen
Jobs mit Parallelverarbeitung ausführen.
Auf Anwendungen in einem Cluster zugreifen
Konfigurieren Sie den Lastausgleich, die Portweiterleitung oder die Einrichtung von Firewall- oder DNS-Konfigurationen für den Zugriff auf Anwendungen in einem Cluster.
Überwachung, Protokollierung und Fehlerbehebung
Richten Sie die Überwachung und Protokollierung ein, um einen Cluster zu behandeln oder eine Container-Anwendung zu debuggen.
Zugriff auf die Kubernetes-API
Lernen Sie verschiedene Methoden kennen, um direkt auf die Kubernetes-API zuzugreifen.
TLS verwenden
Konfigurieren Sie Ihre Anwendung so, dass sie der Cluster-Stammzertifizierungsstelle (Certificate Authority, CA) vertraut und diese verwendet.
Cluster verwalten
Erfahren Sie allgemeine Aufgaben zum Verwalten eines Clusters.
Föderation verwalten
Konfigurieren Sie Komponenten in einer Clusterföderation.
Managing Stateful Applications
Ausführen allgemeiner Aufgaben zum Verwalten von Stateful-Anwendungen, einschließlich Skalieren, Löschen und Debuggen von StatefulSets.
Cluster-Dämonen
Ausführen allgemeiner Aufgaben zum Verwalten eines DaemonSet, z. B. Durchführen eines fortlaufenden Updates.
GPUs verwalten
Konfigurieren und planen Sie NVIDIA-GPUs für die Verwendung durch Nodes in einem Cluster als Ressource.
Verwalten von HugePages
Konfigurieren und verwalten Sie HugePages als planbare Ressource in einem Cluster.
Nächste Schritte
Wenn Sie eine Aufgabenseite schreiben möchten, finden Sie weitere Informationen unter Erstellen einer Pull-Anfrage für Dokumentation.
4.1 - Werkzeuge installieren
kubectl
Das Kubernetes Befehlszeilenprogramm kubectl ermöglicht es Ihnen, Befehle auf einem Kubernetes-Cluster auszuführen. Sie können mit kubectl Anwendungen bereitstellen, Cluster-Ressourcen überwachen und verwalten sowie Logs einsehen.
Weitere Informationen über alle verfügbaren kubectl-Befehle finden Sie in der Kommandoreferenz von kubectl.
kubectl kann unter Linux, macOS und Windows installiert werden. Hier finden Sie Anleitungen zur Installation von kubectl.
kind
Mit kind können Sie Kubernetes lokal auf Ihrem Computer ausführen. Voraussetzung hierfür ist eine konfigurierte und funktionierende Docker-Installation.
Die kind Schnellstart-Seite gibt Informationen darüber, was für den schnellen Einstieg mit kind benötigt wird.
minikube
Ähnlich wie kind ist minikube ein Tool, mit dem man Kubernetes lokal auf dem Computer ausführen kann. Minikube erstellt Cluster mit einer Node oder mehreren Nodes. Somit ist es ein praktisches Tool für tägliche Entwicklungsaktivitäten mit Kubernetes, oder um Kubernetes einfach einmal lokal auszuprobieren.
Hier erfahren Sie, wie Sie minikube auf Ihrem Computer installieren können.
Falls Sie minikube bereits installiert haben, können Sie es verwenden, um eine Beispiel-Anwendung zu bereitzustellen..
kubeadm
Mit kubeadm können Sie Kubernetes-Cluster erstellen und verwalten. kubeadm führt alle notwendigen Schritte aus, um ein minimales aber sicheres Cluster in einer benutzerfreundlichen Art und Weise aufzusetzen.
Auf dieser Seite finden Sie Anleitungen zur Installation von kubeadm.
Sobald Sie kubeadm installiert haben, erfahren Sie hier wie man ein Cluster mit kubeadm erstellt.
4.1.1 - Installieren und konfigurieren von kubectl
Verwenden Sie das Kubernetes Befehlszeilenprogramm, kubectl, um Anwendungen auf Kubernetes bereitzustellen und zu verwalten. Mit kubectl können Sie Clusterressourcen überprüfen, Komponenten erstellen, löschen und aktualisieren; Ihren neuen Cluster betrachten; und Beispielanwendungen aufrufen.
Bevor Sie beginnen
Sie müssen eine kubectl-Version verwenden, die innerhalb eines geringfügigen Versionsunterschieds zur Version Ihres Clusters liegt. Ein v1.2-Client sollte beispielsweise mit einem v1.1, v1.2 und v1.3-Master arbeiten. Die Verwendung der neuesten Version von kubectl verhindert unvorhergesehene Probleme.
Kubectl installieren
Nachfolgend finden Sie einige Methoden zur Installation von kubectl.
Installieren der kubectl Anwendung mithilfe der systemeigenen Paketverwaltung
sudo apt-get update && sudo apt-get install -y apt-transport-https
curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo gpg --dearmour -o /usr/share/keyrings/kubernetes.gpg
echo "deb [arch=amd64 signed-by=/usr/share/keyrings/kubernetes.gpg] https://apt.kubernetes.io/ kubernetes-xenial main" | sudo tee -a /etc/apt/sources.list.d/kubernetes.list
sudo apt-get update
sudo apt-get install -y kubectl
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://packages.cloud.google.com/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://packages.cloud.google.com/yum/doc/rpm-package-key.gpg
EOF
yum install -y kubectl
Installation mit snap auf Ubuntu
Wenn Sie Ubuntu oder eine der anderen Linux-Distributionen verwenden, die den snap Paketmanager unterstützen, können Sie kubectl als snap-Anwendung installieren.
-
Wechseln Sie zum Snap-Benutzer und führen Sie den Installationsbefehl aus:
sudo snap install kubectl --classic -
Testen Sie, ob die installierte Version ausreichend aktuell ist:
kubectl version
Installation mit Homebrew auf macOS
Wenn Sie mit macOS arbeiten und den Homebrew Paketmanager verwenden, können Sie kubectl mit Homebrew installieren.
-
Führen Sie den Installationsbefehl aus:
brew install kubernetes-cli -
Testen Sie, ob die installierte Version ausreichend aktuell ist:
kubectl version
Installation mit Macports auf macOS
Wenn Sie mit macOS arbeiten und den Macports Paketmanager verwenden, können Sie kubectl mit Macports installieren.
-
Führen Sie den Installationsbefehl aus:
sudo port selfupdate sudo port install kubectl -
Testen Sie, ob die installierte Version ausreichend aktuell ist:
kubectl version
Installation mit PowerShell von PSGallery
Wenn Sie mit Windows arbeiten und den Powershell Gallery Paketmanager verwenden, können Sie kubectl mit Powershell installieren und aktualisieren.
-
Führen Sie die Installationsbefehle aus (stellen Sie sicher, dass eine
DownloadLocationangegeben wird):Install-Script -Name install-kubectl -Scope CurrentUser -Force install-kubectl.ps1 [-DownloadLocation <path>]Hinweis: Wenn Sie keineDownloadLocationangeben, wirdkubectlim temporären Verzeichnis des Benutzers installiert.Das Installationsprogramm erstellt
$HOME/.kubeund weist es an, eine Konfigurationsdatei zu erstellen -
Testen Sie, ob die installierte Version ausreichend aktuell ist:
kubectl versionHinweis: Die Aktualisierung der Installation erfolgt durch erneutes Ausführen der beiden in Schritt 1 aufgelisteten Befehle.
Installation auf Windows mit Chocolatey oder scoop
Um kubectl unter Windows zu installieren, können Sie entweder den Paketmanager Chocolatey oder das Befehlszeilen-Installationsprogramm scoop verwenden.
choco install kubernetes-cli
scoop install kubectl
```
kubectl version
```
-
Navigieren Sie zu Ihrem Heimatverzeichnis:
cd %USERPROFILE% -
Erstellen Sie das
.kube-Verzeichnis:mkdir .kube -
Wechseln Sie in das soeben erstellte
.kube-Verzeichnis:cd .kube -
Konfigurieren Sie kubectl für die Verwendung eines Remote-Kubernetes-Clusters:
New-Item config -type fileHinweis: Bearbeiten Sie die Konfigurationsdatei mit einem Texteditor Ihrer Wahl, z.B. Notepad.
Download als Teil des Google Cloud SDK herunter
Sie können kubectl als Teil des Google Cloud SDK installieren.
-
Installieren Sie das Google Cloud SDK.
-
Führen Sie den
kubectl-Installationsbefehl aus:gcloud components install kubectl -
Testen Sie, ob die installierte Version ausreichend aktuell ist:
kubectl version
Installation der kubectl Anwendung mit curl
-
Laden Sie die neueste Version herunter:
curl -LO https://dl.k8s.io/release/$(curl -LS https://dl.k8s.io/release/stable.txt)/bin/darwin/amd64/kubectlUm eine bestimmte Version herunterzuladen, ersetzen Sie den Befehlsteil
$(curl -LS https://dl.k8s.io/release/stable.txt)mit der jeweiligen Version.Um beispielsweise die Version 1.28.4 auf macOS herunterzuladen, verwenden Sie den folgenden Befehl:
curl -LO https://dl.k8s.io/release/v1.28.4/bin/darwin/amd64/kubectl -
Machen Sie die kubectl-Binärdatei ausführbar.
chmod +x ./kubectl -
Verschieben Sie die Binärdatei in Ihren PATH.
sudo mv ./kubectl /usr/local/bin/kubectl
-
Laden Sie die neueste Version mit dem Befehl herunter:
curl -LO https://dl.k8s.io/release/$(curl -LS https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectlUm eine bestimmte Version herunterzuladen, ersetzen Sie den Befehlsteil
$(curl -LS https://dl.k8s.io/release/stable.txt)mit der jeweiligen Version.Um beispielsweise die Version 1.28.4 auf Linux herunterzuladen, verwenden Sie den folgenden Befehl:
curl -LO https://dl.k8s.io/release/v1.28.4/bin/linux/amd64/kubectl -
Machen Sie die kubectl-Binärdatei ausführbar.
chmod +x ./kubectl -
Verschieben Sie die Binärdatei in Ihren PATH.
sudo mv ./kubectl /usr/local/bin/kubectl
-
Laden Sie das aktuellste Release 1.28.4 von diesem link herunter.
Oder, sofern Sie
curlinstalliert haven, verwenden Sie den folgenden Befehl:curl -LO https://dl.k8s.io/release/v1.28.4/bin/windows/amd64/kubectl.exeInformationen zur aktuellen stabilen Version (z. B. für scripting) finden Sie unter https://dl.k8s.io/release/stable.txt.
-
Verschieben Sie die Binärdatei in Ihren PATH.
kubectl konfigurieren
Damit kubectl einen Kubernetes-Cluster finden und darauf zugreifen kann, benötigt es eine kubeconfig Datei. Diese wird automatisch erstellt, wenn Sie einen Cluster mit kube-up.sh erstellen oder einen Minikube-Cluster erfolgreich implementieren. Weitere Informationen zum Erstellen von Clustern finden Sie in den Anleitungen für die ersten Schritte. Wenn Sie Zugriff auf einen Cluster benötigen, den Sie nicht erstellt haben, lesen Sie die Cluster-Zugriff freigeben Dokumentation.
Die kubectl-Konfiguration befindet sich standardmäßig unter ~/.kube/config.
Überprüfen der kubectl-Konfiguration
Überprüfen Sie, ob kubectl ordnungsgemäß konfiguriert ist, indem Sie den Clusterstatus abrufen:
kubectl cluster-info
Wenn Sie eine URL-Antwort sehen, ist kubectl korrekt für den Zugriff auf Ihren Cluster konfiguriert.
Wenn eine Meldung ähnlich der folgenden angezeigt wird, ist kubectl nicht richtig konfiguriert oder kann keine Verbindung zu einem Kubernetes-Cluster herstellen.
The connection to the server <server-name:port> was refused - did you specify the right host or port?
Wenn Sie beispielsweise vorhaben, einen Kubernetes-Cluster auf Ihrem Laptop (lokal) auszuführen, müssen Sie zunächst ein Tool wie minikube installieren und anschließend die oben genannten Befehle erneut ausführen.
Wenn kubectl cluster-info die URL-Antwort zurückgibt, Sie jedoch nicht auf Ihren Cluster zugreifen können, verwenden Sie Folgendes, um zu überprüfen, ob er ordnungsgemäß konfiguriert ist:
kubectl cluster-info dump
Aktivieren der automatischen Autovervollständigung der Shell
kubectl bietet Autocompletion-Unterstützung für Bash und Zsh, was Ihnen viel Tipparbeit erspart!
Im Folgenden werden die Verfahren zum Einrichten der automatischen Vervollständigung für Bash (einschließlich der Unterschiede zwischen Linux und macOS) und Zsh beschrieben.
Einführung
Das kubectl-Vervollständigungsskript für Bash kann mit dem Befehl kubectl completion bash generiert werden. Durch das Sourcing des Vervollständigungsskripts in Ihrer Shell wird die automatische Vervollständigung von kubectl ermöglicht.
Das Fertigstellungsskript benötigt jedoch bash-completion. Dies bedeutet, dass Sie diese Software zuerst installieren müssen (Sie können testen, ob Sie bereits bash-completion installiert haben, indem Sie type _init_completion ausführen).
Installation von bash-completion
bash-completion wird von vielen Paketmanagern bereitgestellt (siehe hier). Sie können es mittels apt-get install bash-completion oder yum install bash-completion, usw.
Die obigen Befehle erstellen /usr/share/bash-completion/bash_completion,Dies ist das Hauptskript für die Bash-Vollendung. Abhängig von Ihrem Paketmanager müssen Sie diese Datei manuell in Ihre ~ / .bashrc-Datei eingeben.
Um dies herauszufinden, laden Sie Ihre Shell erneut und führen Sie type _init_completion aus. Wenn der Befehl erfolgreich ist, ist bereits alles vorbereitet. Andernfalls fügen Sie der ~/.bashrc-Datei Folgendes hinzu:
source /usr/share/bash-completion/bash_completion
Laden Sie Ihre Shell erneut und vergewissern Sie sich, dass bash-completion korrekt installiert ist, indem Sie folgendes eingeben: type _init_completion.
Aktivieren der automatische Vervollständigung von kubectl
Sie müssen nun sicherstellen, dass das kubectl-Abschlussskript in allen Ihren Shell-Sitzungen verwendet wird. Es gibt zwei Möglichkeiten, dies zu tun:
-
Fügen Sie das Vervollständigungsskript Ihrer
~ /.bashrc-Datei hinzu:echo 'source <(kubectl completion bash)' >>~/.bashrc -
Fügen Sie das Vervollständigungsskript zum Verzeichnis
/etc/bash_completion.dhinzu:kubectl completion bash >/etc/bash_completion.d/kubectl
/etc/bash_completion.d.
Beide Ansätze sind gleichwertig. Nach dem erneuten Laden der Shell sollte kubectl autocompletion funktionieren.
Einführung
Das kubectl-Vervollständigungsskript für Bash kann mit dem Befehl kubectl completion bash generiert werden. Durch das Sourcing des Vervollständigungsskripts in Ihrer Shell wird die automatische Vervollständigung von kubectl ermöglicht.
Das Fertigstellungsskript benötigt jedoch bash-completion. Dies bedeutet, dass Sie diese Software zuerst installieren müssen (Sie können testen, ob Sie bereits bash-completion installiert haben, indem Sie type _init_completion ausführen).
Installation von bash-completion
Sie können bash-completion mit Homebrew installieren:
brew install bash-completion@2
@2 steht für bash-completion 2, was vom kubectl Vervollständigungsskript benötigt wird (es funktioniert nicht mit bash-completion 1). Für bash-completion 2 ist wiederum Bash 4.1 oder höher erforderlich. Deshalb mussten Sie Bash aktualisieren.
Wie in der Ausgabe von brew install (Abschnitt "Vorsichtsmaßnahmen") angegeben, fügen Sie Ihrer ~/.bashrc oder ~/.bash_profile-Datei die folgenden Zeilen hinzu:
export BASH_COMPLETION_COMPAT_DIR=/usr/local/etc/bash_completion.d
[[ -r /usr/local/etc/profile.d/bash_completion.sh ]] && . /usr/local/etc/profile.d/bash_completion.sh
Laden Sie Ihre Shell erneut und vergewissern Sie sich, dass bash-completion korrekt installiert ist, indem Sie type _init_completion eingeben.
Aktivieren der automatischen Vervollständigung von kubectl
Sie müssen nun sicherstellen, dass das kubectl-Abschlussskript in allen Ihren Shell-Sitzungen verwendet wird. Es gibt mehrere Möglichkeiten, dies zu tun:
-
Fügen Sie das Vervollständigungsskript Ihrer
~ /.bashrc-Datei hinzu:echo 'source <(kubectl completion bash)' >>~/.bashrc -
Fügen Sie das Vervollständigungsskript zum Verzeichnis
/etc/bash_completion.dhinzu:kubectl completion bash >/usr/local/etc/bash_completion.d/kubectl -
Wenn Sie kubectl mit Homebrew installiert haben (wie hier beschrieben), dann wurde das Vervollständigungsskript automatisch in
/usr/local/etc/bash_completion.d/kubectlinstalliert. In diesem Fall müssen Sie nichts tun.
BASH_COMPLETION_COMPAT_DIRfestgelegt ist.
Alle Ansätze sind gleichwertig. Nach dem erneuten Laden der Shell sollte kubectl Autovervollständigung funktionieren.
Das kubectl Vervollständigungsskript für Zsh kann mit dem folgenden Befehl generiert werden: kubectl completion zsh. Durch das Sourcing des Completion-Skripts in Ihrer Shell wird die automatische Vervollständigung von kubectl ermöglicht.
Fügen Sie Ihrer ~/.zshrc-Datei dazu Folgendes hinzu:
source <(kubectl completion zsh)
Nach dem erneuten Laden der Shell sollte kubectl Autovervollständigung funktionieren.
Wenn eine Fehlermeldung wie complete: 13: command not found: compdef angezeigt wird, fügen Sie am Anfang der Datei `~/.zshrc" folgendes hinzu:
autoload -Uz compinit
compinit
Nächste Schritte
Erfahren Sie, wie Sie Ihre Anwendung starten und verfügbar machen.
4.1.2 - Kubectl installieren und konfigurieren auf Linux
Bevor Sie beginnen
Um kubectl zu verwenden darf die kubectl-Version nicht mehr als eine Minor-Version Unterschied zu dem Cluster aufweisen. Zum Beispiel: eine Client-Version v1.28 kann mit folgenden Versionen kommunizieren v1.27, v1.28, und v1.29. Die Verwendung der neuesten kompatiblen Version von kubectl hilft, unvorhergesehene Probleme zu vermeiden.
Kubectl auf Linux installieren
Um kubectl auf Linux zu installieren, gibt es die folgenden Möglichkeiten:
- Bevor Sie beginnen
- Kubectl auf Linux installieren
- Kubectl Konfiguration verifizieren
- Optionale kubectl Konfigurationen und Plugins
- Nächste Schritte
Kubectl Binary mit curl auf Linux installieren
-
Das aktuellste Release downloaden:
curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl"Hinweis:Um eine spezifische Version herunterzuladen, ersetze
$(curl -L -s https://dl.k8s.io/release/stable.txt)mit der spezifischen Version.Um zum Beispiel Version 1.28.4 auf Linux herunterzuladen:
curl -LO https://dl.k8s.io/release/v1.28.4/bin/linux/amd64/kubectl -
Binary validieren (optional)
Download der kubectl Checksum-Datei:
curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl.sha256"Kubectl Binary mit der Checksum-Datei validieren:
echo "$(cat kubectl.sha256) kubectl" | sha256sum --checkWenn Valide, dann sieht die Ausgabe wie folgt aus:
kubectl: OKFalls die Validierung fehlschlägt, beendet sich
sha256mit einem "nonzero"-Status und gibt einen Fehler aus, welcher so aussehen könnte:kubectl: FAILED sha256sum: WARNING: 1 computed checksum did NOT matchHinweis: Lade von der kubectl Binary und Checksum-Datei immer die selben Versionen herunter. -
kubectl installieren
sudo install -o root -g root -m 0755 kubectl /usr/local/bin/kubectlHinweis:Wenn kein root Zugriff auf das Zielsystem möglich ist, kann kubectl in das Verzeichnis
~/.local/bininstalliert werden:chmod +x kubectl mkdir -p ~/.local/bin mv ./kubectl ~/.local/bin/kubectl # und ~/.local/bin zur Umgebungsvariable $PATH hinzufügen -
Prüfen ob die installierte Version die aktuellste Version ist:
kubectl version --clientHinweis:Der oben stehende Befehl wirft folgende Warnung:
WARNING: This version information is deprecated and will be replaced with the output from kubectl version --short.Diese Warnung kann ignoriert werden. Prüfe lediglich die
kubectlVersion, eelche installiert wurde.Oder benutzte diesen Befehl für eine detailliertere Ansicht:
kubectl version --client --output=yaml
Installieren mit Hilfe des Linux eigenen Paketmanagers
-
Update des
aptPaketindex und Installation der benötigten Pakete um das KubernetesaptRepository zu nutzen:sudo apt-get update sudo apt-get install -y ca-certificates curlFalls Debian 9 (stretch) oder älter genutzt wird, müssen zusätzlich das Paket
apt-transport-httpsinstalliert werden:sudo apt-get install -y apt-transport-https -
Den öffentlichen Google Cloud Signaturschlüssel herunterladen:
curl -fsSL https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo gpg --dearmor -o /etc/apt/keyrings/kubernetes-archive-keyring.gpg -
Kubernetes zum
aptRepository:echo "deb [signed-by=/etc/apt/keyrings/kubernetes-archive-keyring.gpg] https://apt.kubernetes.io/ kubernetes-xenial main" | sudo tee /etc/apt/sources.list.d/kubernetes.list -
Den
aptPaketindex mit dem neuen Repository updaten und kubectl installieren:sudo apt-get update sudo apt-get install -y kubectl
/etc/apt/keyrings nicht per default.
Falls es benötigt wird, kann es angelegt werden. Hierzu sollte es danach von jedermann lesbar, aber nur von Admins schreibar gemacht werden.
cat <<EOF | sudo tee /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://packages.cloud.google.com/yum/repos/kubernetes-el7-\$basearch
enabled=1
gpgcheck=1
gpgkey=https://packages.cloud.google.com/yum/doc/yum-key.gpg https://packages.cloud.google.com/yum/doc/rpm-package-key.gpg
EOF
sudo yum install -y kubectl
Installation mit anderen Paketmanagern
Falls Ubuntu oder andere Linux Distributionen verwendet wird, und diese den snap Paketmanager unterstützen, kann kubectl als snap Anwendung installiert werden.
snap install kubectl --classic
kubectl version --client
Falls in Linux Homebrew als Paketmanager genutzt wird, kann kubectl über diesen installiert werden.
brew install kubectl
kubectl version --client
Kubectl Konfiguration verifizieren
Um mithilfe von kubectl ein Cluster zu finden und darauf zuzugreifen benötigt es eine
kubeconfig Datei,
welche automatisch angelegt wird, wenn ein Cluster mit Hilfe der
kube-up.sh
oder erfolgreich ein Cluster mit Minicube erstellt wurde.
Standardmäßig liegt die kubectl Konfigurationsdatei unter folgendem Pfad ~/.kube/config.
Um zu überprüfen ob kubectl korrekt konfiguriert ist, kann der Cluster-Status abgefragt werden:
kubectl cluster-info
Wenn als Antwort eine URL ausgegeben wird, ist kubectl korrekt konfiguriert und kann auf das Cluster zugreifen.
Falls eine Nachricht ähnlich wie die Folgende zu sehen ist, ist kubectl nicht korrekt konfiguriert oder nicht in der Lage das Cluster zu erreichen.
The connection to the server <server-name:port> was refused - did you specify the right host or port?
Wenn zum Beispiel versucht wird ein Kubernetes Cluster lokal auf dem Laptop zu starten, muss ein Tool wie zum Beispiel Minikube zuerst installiert werden. Danach können die oben erwähnten Befehle erneut ausgeführt werden.
Falls kubectl cluster-info eine URL zurück gibt, aber nicht auf das Cluster zugreifen kann, prüfe ob kubectl korrekt konfiguriert wurde:
kubectl cluster-info dump
Optionale kubectl Konfigurationen und Plugins
Shell Autovervollständigung einbinden
kubectl stellt Autovervollständigungen für Bash, Zsh, Fish und Powershell zur Verfügung, mit welchem sich Kommandozeilen Befehle beschleunigen lassen.
Untenstehend ist beschrieben, wie die Autovervollständigungen für Fish und Zsh eingebunden werden.
Das kubectl Autovervollständigungsskript für Fish kann mit folgendem Befehl kubectl completion fish generiert werden. Mit dem Befehl kubectl completion fish | source wird die Autovervollständigung in der aktuellen Sitzung aktiviert.
Um die Autovervollständigung in allen Sitzungen einzurichten, muss folgender Befehl in die ~/.config/fish/config.fish Datei eingetragen werden:
kubectl completion fish | source
Nach dem Neuladen der Shell, sollte die kubectl Autovervollständigung funktionieren.
Das kubectl Autovervollständigungsskript für Zsh kann mit folgendem Befehl kubectl completion zsh generiert werden. Mit dem Befehl kubectl completion zsh | source wird die Autovervollständigung in der aktuellen Sitzung aktiviert.
Um die Autovervollständigung in allen Sitzungen einzurichten, muss folgender Befehl in die ~/.zshrc Datei eingetragen werden:
source <(kubectl completion zsh)
Falls ein Alias für kubectl eingerichtet wurde, funktioniert die kubectl Autovervollständung automatisch.
Nach dem Neuladen der Shell, sollte die kubectl Autovervollständigung funktionieren.
Sollte ein Fehler auftreten wie dieser: 2: command not found: compdef, muss bitte folgendes am Anfang der ~/.zshrc Datei eingefügt werden:
autoload -Uz compinit
compinit
kubectl-convert Plugin installieren
Ein Plugin für das Kubernetes Kommandozeilentool kubectl, welches es ermöglicht Manifeste von einer Version der
Kubernetes API zu einer anderen zu konvertieren. Kann zum Beispiel hilfreich sein, Manifeste zu einer nicht als veraltet (deprecated)
markierten API Version mit einem neuerem Kubernetes Release zu migrieren.
Weitere Infos finden Sich unter: zu nicht veralteten APIs migrieren
-
Neueste Version des Kommandozeilenbefehls herunterladen:
curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl-convert" -
Binär-Datei validieren (optional)
Download der kubectl-convert Checksum-Datei:
curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl-convert.sha256"Kubectl-convert Binary mit der Checksum-Datei validieren:
echo "$(cat kubectl-convert.sha256) kubectl-convert" | sha256sum --checkWenn Valide, dann sieht die Ausgabe wie folgt aus:
kubectl-convert: OKFalls die Validierung fehlschlägt, beendet sich
sha256mit einem "nonzero"-Status und gibt einen Fehler aus, welcher so aussehen könnte:kubectl-convert: FAILED sha256sum: WARNING: 1 computed checksum did NOT matchHinweis: Lade von der kubectl Binary und Checksum-Datei immer die selben Versionen herunter. -
kubectl-convert installieren
sudo install -o root -g root -m 0755 kubectl-convert /usr/local/bin/kubectl-convert -
Verifizieren, dass das Pluign erfolgreich installiert wurde:
kubectl convert --help
Wenn kein Fehler ausgegeben wird, ist das Plugin erfolgreich installiert worden.
-
Nach Installation des Plugins, die Installationsdateien aufräumen:
rm kubectl-convert kubectl-convert.sha256
Nächste Schritte
- Minikube installieren
- Installations Guides ansehen um mehr über die Clustererstellung zu erfahren.
- Lernen wie man Applikationen startet und erreichbar macht.
- Falls Zugriff auf ein Cluster benötigt wird, welches nicht von einem selbst erstellt wurde, könnte Clusterzugang teilen interessant sein.
- Lies die kubectl Referenzdokumentation
4.1.3 - Kubectl installieren und konfigurieren auf macOS
Bevor Sie beginnen
Um kubectl zu verwenden darf die kubectl-Version nicht mehr als eine Minor-Version Unterschied zu deinem Cluster aufweisen. Zum Beispiel: eine Client-Version v1.28 kann mit folgenden Versionen kommunizieren v1.27, v1.28, und v1.29. Die Verwendung der neuesten kompatiblen Version von kubectl hilft, unvorhergesehene Probleme zu vermeiden.
Kubectl auf macOS installieren
Um kubectl auf macOS zu installieren, gibt es die folgenden Möglichkeiten:
- Bevor Sie beginnen
- Kubectl auf macOS installieren
- Kubectl Konfiguration verifizieren
- Optionale kubectl Konfigurationen und Plugins
- Nächste Schritte
Kubectl Binary mit curl auf macOS installieren
-
Das aktuellste Release downloaden:
curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/darwin/amd64/kubectl"curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/darwin/arm64/kubectl"Hinweis:Um eine spezifische Version herunterzuladen, ersetze
$(curl -L -s https://dl.k8s.io/release/stable.txt)mit der spezifischen VersionUm zum Beispiel Version 1.28.4 auf Intel macOS herunterzuladen:
curl -LO "https://dl.k8s.io/release/v1.28.4/bin/darwin/amd64/kubectl"Für macOS auf Apple Silicon (z.B. M1/M2):
curl -LO "https://dl.k8s.io/release/v1.28.4/bin/darwin/arm64/kubectl" -
Binary validieren (optional)
Download der kubectl Checksum-Datei:
curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/darwin/amd64/kubectl.sha256"curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/darwin/arm64/kubectl.sha256"Kubectl Binary mit der Checksum-Datei validieren:
echo "$(cat kubectl.sha256) kubectl" | shasum -a 256 --checkWenn Valide, dann sieht die Ausgabe wie folgt aus:
kubectl: OKFalls die Validierung fehlschlägt, beendet sich
shasummit einem "nonzero"-Status und gibt einen Fehler aus, welcher so aussehen könnte:kubectl: FAILED shasum: WARNING: 1 computed checksum did NOT matchHinweis: Lade von der kubectl Binary und Checksum-Datei immer die selben Versionen herunter. -
Kubectl Binary ausführbar machen.
chmod +x ./kubectl -
Kubectl Binary zu einem Ordner in Ihrem
PATHverschieben.sudo mv ./kubectl /usr/local/bin/kubectl sudo chown root: /usr/local/bin/kubectlHinweis: Stelle sicher, dass/usr/local/binin deiner PATH Umgebungsvariable gesetzt ist. -
Prüfen ob die installierte Version die aktuellste Version ist:
kubectl version --clientHinweis:Der oben stehende Befehl wirft folgende Warnung:
WARNING: This version information is deprecated and will be replaced with the output from kubectl version --short.Diese Warnung kann ignoriert werden. Prüfe lediglich die
kubectlVersion, welche installiert wurde.Oder benutzte diesen Befehl für eine detailliertere Ansicht:
kubectl version --client --output=yaml -
Nach Installation des Plugins, die Installationsdateien aufräumen:
rm kubectl kubectl.sha256
Mit Homebrew auf macOS installieren
Wenn macOS und Homebrew als Paketmanager benutzt wird, kann kubectl über diesen installiert werden.
-
Führe den Installationsbefehl aus:
brew install kubectloder
brew install kubernetes-cli -
Prüfen ob die installierte Version die aktuellste Version ist:
kubectl version --client
Mit Macports auf macOS installieren
Wenn macOS und Macports als Paketmanager benutzt wird, kann kubectl über diesen installiert werden.
-
Führe den Installationsbefehl aus:
sudo port selfupdate sudo port install kubectl -
Prüfen ob die installierte Version die aktuellste Version ist:
kubectl version --client
Kubectl Konfiguration verifizieren
Um mithilfe von kubectl ein Cluster zu finden und darauf zuzugreifen benötigt es eine
kubeconfig Datei,
welche automatisch angelegt wird, wenn ein Cluster mit Hilfe der
kube-up.sh
oder erfolgreich ein Cluster mit Minicube erstellt wurde.
Standardmäßig liegt die kubectl Konfigurationsdatei unter folgendem Pfad ~/.kube/config.
Um zu überprüfen ob kubectl korrekt konfiguriert ist, kann der Cluster-Status abgefragt werden:
kubectl cluster-info
Wenn als Antwort eine URL ausgegeben wird, ist kubectl korrekt konfiguriert und kann auf das Cluster zugreifen.
Falls eine Nachricht ähnlich wie die Folgende zu sehen ist, ist kubectl nicht korrekt konfiguriert oder nicht in der Lage das Cluster zu erreichen.
The connection to the server <server-name:port> was refused - did you specify the right host or port?
Wenn zum Beispiel versucht wird ein Kubernetes Cluster lokal auf dem Laptop zu starten, muss ein Tool wie zum Beispiel Minikube zuerst installiert werden. Danach können die oben erwähnten Befehle erneut ausgeführt werden.
Falls kubectl cluster-info eine URL zurück gibt, aber nicht auf das Cluster zugreifen kann, prüfe ob kubectl korrekt konfiguriert wurde:
kubectl cluster-info dump
Optionale kubectl Konfigurationen und Plugins
Shell Autovervollständigung einbinden
kubectl stellt Autovervollständigungen für Bash, Zsh, Fish und Powershell zur Verfügung, mit welchem Kommandozeilenbefehle beschleunigt werden können.
Untenstehend ist beschrieben, wie die Autovervollständigungen für Fish und Zsh eingebunden werden.
Das kubectl Autovervollständigungsskript für Fish kann mit folgendem Befehl kubectl completion fish generiert werden. Mit dem Befehl kubectl completion fish | source wird die Autovervollständigung in der aktuellen Sitzung aktiviert.
Um die Autovervollständigung in allen Sitzungen einzurichten, muss folgender Befehl in die ~/.config/fish/config.fish Datei eingetragen werden:
kubectl completion fish | source
Nach dem Neuladen der Shell, sollte die kubectl Autovervollständigung funktionieren.
Das kubectl Autovervollständigungsskript für Zsh kann mit folgendem Befehl kubectl completion zsh generiert werden. Mit dem Befehl kubectl completion zsh | source wird die Autovervollständigung in der aktuellen Sitzung aktiviert.
Um die Autovervollständigung in allen Sitzungen einzurichten, muss folgender Befehl in die ~/.zshrc Datei eingetragen werden:
source <(kubectl completion zsh)
Falls ein Alias für kubectl eingerichtet wurde, funktioniert die kubectl Autovervollständung automatisch.
Nach dem Neuladen der Shell, sollte die kubectl Autovervollständigung funktionieren.
Sollte ein Fehler auftreten wie dieser: 2: command not found: compdef, muss bitte folgendes am Anfang der ~/.zshrc Datei eingefügt werden:
autoload -Uz compinit
compinit
kubectl-convert Plugin installieren
Ein Plugin für das Kubernetes Kommandozeilentool kubectl, welches es ermöglicht Manifeste von einer Version der
Kubernetes API zu einer anderen zu konvertieren. Kann zum Beispiel hilfreich sein, Manifeste zu einer nicht als veraltet (deprecated)
markierten API Version mit einem neuerem Kubernetes Release zu migrieren.
Weitere Infos finden Sich unter: zu nicht veralteten APIs migrieren
-
Neueste Version des Kommandozeilenbefehls herunterladen:
curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/darwin/amd64/kubectl-convert"curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/darwin/arm64/kubectl-convert" -
Binär-Datei validieren (optional)
Download der kubectl-convert Checksum-Datei:
curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/darwin/amd64/kubectl-convert.sha256"curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/darwin/arm64/kubectl-convert.sha256"Validierung der kubectl-convert Binary mit der Checksum-Datei:
echo "$(cat kubectl-convert.sha256) kubectl-convert" | shasum -a 256 --checkWenn Valide, dann sieht die Ausgabe wie folgt aus:
kubectl-convert: OKFalls die Validierung fehlschlägt, beendet sich
shasummit einem "nonzero"-Status und gibt einen Fehler aus, welcher so aussehen könnte:kubectl-convert: FAILED shasum: WARNING: 1 computed checksum did NOT matchHinweis: Lade von der kubectl Binary und Checksum-Datei immer die selben Versionen herunter. -
Kubectl-convert Binary ausführbar machen
chmod +x ./kubectl-convert -
Kubectl-convert Binary zu einem Ordner in
PATHUmgebungsvariable verschieben.sudo mv ./kubectl-convert /usr/local/bin/kubectl-convert sudo chown root: /usr/local/bin/kubectl-convertHinweis: Stelle sicher, dass/usr/local/binin der PATH Umgebungsvariable gesetzt ist. -
Verifizieren, dass das Pluign erfolgreich installiert wurde:
kubectl convert --helpWenn kein Fehler ausgegeben wird, ist das Plugin erfolgreich installiert worden.
-
Nach Installation des Plugins, die Installationsdateien aufräumen:
rm kubectl-convert kubectl-convert.sha256
Nächste Schritte
- Minikube installieren
- Installations Guides ansehen um mehr über die Clustererstellung zu erfahren.
- Lernen wie man Applikationen startet und erreichbar macht.
- Falls Zugriff auf ein Cluster benötigt wird, welches nicht von einem selbst erstellt wurde, könnte Clusterzugang teilen interessant sein.
- Lies die kubectl Referenzdokumentation
4.1.4 - Installation von Minikube
Diese Seite zeigt Ihnen, wie Sie Minikube installieren, ein Programm, das einen Kubernetes-Cluster mit einem einzigen Node in einer virtuellen Maschine auf Ihrem Laptop ausführt.
Bevor Sie beginnen
Die VT-x- oder AMD-v-Virtualisierung muss im BIOS Ihres Computers aktiviert sein. Um dies unter Linux zu überprüfen, führen Sie Folgendes aus und vergewissern Sie sich, dass die Ausgabe nicht leer ist:
egrep --color 'vmx|svm' /proc/cpuinfo
Einen Hypervisor installieren
Wenn noch kein Hypervisor installiert ist, installieren Sie jetzt einen für Ihr Betriebssystem:
| Betriebssystem | Unterstützte Hypervisoren |
|---|---|
| macOS | VirtualBox, VMware Fusion, HyperKit |
| Linux | VirtualBox, KVM |
| Windows | VirtualBox, Hyper-V |
--vm-driver=none, mit der die Kubernetes-Komponenten auf dem Host und nicht in einer VM ausgeführt werden. Die Verwendung dieses Treibers erfordert Docker und eine Linux-Umgebung, jedoch keinen Hypervisor.
Kubectl installieren
- Installieren Sie kubectl gemäß den Anweisungen in kubectl installieren und einrichten.
Minikube installieren
macOS
Die einfachste Möglichkeit, Minikube unter macOS zu installieren, ist die Verwendung von Homebrew:
brew install minikube
Sie können es auch auf macOS installieren, indem Sie eine statische Binärdatei herunterladen:
curl -Lo minikube https://storage.googleapis.com/minikube/releases/latest/minikube-darwin-amd64 \
&& chmod +x minikube
So fügen Sie die Minikube-Programmdatei auf einfache Weise Ihrem Pfad hinzu:
sudo mv minikube /usr/local/bin
Linux
Sie können Minikube unter Linux installieren, indem Sie eine statische Binärdatei herunterladen:
curl -Lo minikube https://storage.googleapis.com/minikube/releases/latest/minikube-linux-amd64 \
&& chmod +x minikube
So fügen Sie die Minikube-Programmdatei auf einfache Weise Ihrem Pfad hinzu:
sudo cp minikube /usr/local/bin && rm minikube
Windows
Die einfachste Möglichkeit, Minikube unter Windows zu installieren, ist die Verwendung von Chocolatey (als Administrator ausführen):
choco install minikube kubernetes-cli
Schließen Sie nach der Installation von Minikube die aktuelle CLI-Sitzung und starten Sie sie neu. Minikube sollte automatisch zu Ihrem Pfad hinzugefügt werden.
Manuelle installation unter Windows
Um Minikube manuell unter Windows zu installieren, laden Sie die Datei minikube-windows-amd64 herunter, umbenennen Sie sie in minikube.exe und fügen Sie sie Ihrem Pfad zu.
Windows Installer
So installieren Sie Minikube manuell unter Windows mit Windows Installer, laden Sie die Datei minikube-installer.exe und führen Sie den Installer aus.
Eine bestehende Installation bereinigen
Wenn Sie minikube bereits installiert haben, starten Sie die Anwendung:
minikube start
Und der Befehl gibt einen Fehler zurück:
machine does not exist
Müssen Sie die Konfigurationsdateien löschen:
rm -rf ~/.minikube
Nächste Schritte
4.2 - Einen Cluster verwalten
4.2.1 - Verwaltung mit kubeadm
4.3 - Pods und Container konfigurieren
4.4 - Daten in Anwendungen injizieren
4.5 - Anwendungen ausführen
4.5.1 - Horizontal Pod Autoscaler
Der Horizontal Pod Autoscaler skaliert automatisch die Anzahl der Pods eines Replication Controller, Deployment oder Replikat Set basierend auf der beobachteten CPU-Auslastung (oder, mit Unterstützung von benutzerdefinierter Metriken, von der Anwendung bereitgestellten Metriken). Beachte, dass die horizontale Pod Autoskalierung nicht für Objekte gilt, die nicht skaliert werden können, z. B. DaemonSets.
Der Horizontal Pod Autoscaler ist als Kubernetes API-Ressource und einem Controller implementiert. Die Ressource bestimmt das Verhalten des Controllers. Der Controller passt die Anzahl der Replikate eines Replication Controller oder Deployments regelmäßig an, um die beobachtete durchschnittliche CPU-Auslastung an das vom Benutzer angegebene Ziel anzupassen.
Wie funktioniert der Horizontal Pod Autoscaler?

Der Horizontal Pod Autoscaler ist als Kontrollschleife mit einer Laufzeit implementiert, die durch das Flag --horizontal-pod-autoscaler-sync-period am Controller Manager gesteuert wird (mit einem Standardwert von 15 Sekunden).
Während jedem Durchlauf fragt der Controller Manager die Ressourcennutzung anhand der in jeder HorizontalPodAutoscaler Definition angegebenen Metriken ab. Der Controller Manager bezieht die Metriken entweder aus der Resource Metrics API (für Ressourcenmetriken pro Pod) oder aus der Custom Metrics API (für alle anderen Metriken).
- Für jede pro Pod Ressourcenmetriken (wie CPU) ruft der Controller die Metriken über die Ressourcenmetriken API für jeden Pod ab, der vom HorizontalPodAutoscaler angesprochen wird. Sofern ein Zielnutzungswert eingestellt ist, berechnet der Controller den Nutzungswert als Prozentsatz der äquivalenten Ressourcenanforderung der Containern in jedem Pod. Wenn ein Ziel-Rohwert eingestellt ist, werden die Rohmetrikenwerte direkt verwendet. Der Controller nimmt dann den Mittelwert der Auslastung oder den Rohwert (je nach Art des angegebenen Ziels) über alle Zielpods und erzeugt ein Quotienten, mit dem die Anzahl der gewünschten Replikate skaliert wird.
Beachte, dass, wenn einige der Container des Pods nicht über den entsprechenden Ressourcenanforderung verfügen, die CPU-Auslastung für den Pod nicht definiert wird und der Autoscaler keine Maßnahmen bezüglich dieser Metrik ergreift. Weitere Informationen zur Funktionsweise des Autoskalierungsalgorithmus finden Sie im folgenden Abschnitt über den Algorithmus.
-
Bei benutzerdefinierten Metriken pro Pod funktioniert die Steuerung ähnlich wie bei Ressourcenmetriken pro Pod, nur dass diese mit Rohwerten und nicht mit Nutzungswerten arbeitet.
-
Für Objektmetriken und externe Metriken wird eine einzelne Metrik abgerufen, die das jeweilige Objekt beschreibt. Diese Kennzahl wird mit dem Sollwert verglichen, um ein Verhältnis wie oben beschrieben zu erhalten. In der API-Version von
autoscaling/v2beta2kann dieser Wert optional durch die Anzahl der Pods geteilt werden, bevor der Vergleich durchgeführt wird.
Der HorizontalPodAutoscaler holt Metriken normalerweise aus einer Reihe von aggregierten APIs (metrics.k8s.io, custom.metrics.k8s.io und external.metrics.k8s.io). Die API metrics.k8s.io wird normalerweise vom Metrics Server bereitgestellt, der separat gestartet werden muss. Siehe Metrics Server für weitere Anweisungen. Der HorizontalPodAutoscaler kann auch Metriken direkt aus dem Heapster beziehen.
Kubernetes 1.11 [deprecated]
Das Verwenden von Metriken aus Heapster ist seit der Kubernetes Version 1.11 veraltet.
Siehe Unterstützung der Metrik APIs für weitere Details.
Der Autoscaler greift über die Scale Sub-Ressource auf die entsprechenden skalierbaren Controller (z.B. Replication Controller, Deployments und Replika Sets) zu. Scale ist eine Schnittstelle, mit der Sie die Anzahl der Replikate dynamisch einstellen und jeden ihrer aktuellen Zustände untersuchen können. Weitere Details zu der Scale Sub-Ressource findest du hier.
Details zum Algorithmus
Vereinfacht gesagt arbeitet der Horizontal Pod Autoscaler Controller mit dem Verhältnis zwischen dem gewünschten metrischen Wert und dem aktuellen metrischen Wert:
desiredReplicas = ceil[currentReplicas * ( currentMetricValue / desiredMetricValue )]
Wenn beispielsweise der aktuelle metrische Wert 200m und der gewünschte Wert 100m ist, wird die Anzahl der Replikate verdoppelt, da 200.0 / 100.0 == 2.0 ist. Wenn der aktuelle Wert jedoch 50m ist, halbieren sich die Anzahl der Replikate 50.0 / 100.0 == 0.5. Es wird auf die Skalierung verzichtet, wenn das Verhältnis ausreichend nahe bei 1,0 liegt (innerhalb einer global konfigurierbaren Toleranz, vom Flag --horizontal-pod-autoscaler-tolerance, das standardmäßig auf 0,1 gesetzt ist).
Wenn ein targetAverageValue oder targetAverageUtilization angegeben wird, wird der currentMetricValue berechnet, indem der Mittelwert der gegebenen Metrik über alle Pods im Skalierungsziel des HorizontalPodAutoscaler berechnet wird. Vor der Überprüfung der Toleranz und der Entscheidung über die finalen Werte berücksichtigen wir jedoch die Pod Readiness und fehlende Metriken.
Alle Pods mit einem gesetzten Zeitstempel zur Löschung (d.h. Pods, die gerade heruntergefahren werden) und alle ausgefallenen Pods werden verworfen.
Wenn einem bestimmten Pod Metriken fehlen, wird es für später zurückgestellt; Pods mit fehlenden Metriken werden verwendet, um den endgültigen Skalierungsmenge anzupassen.
Wenn bei der Skalierung anhand der CPU ein Pod noch nicht bereit ist (d.h. er wird noch initialisiert) oder der letzte metrische Punkt für den Pod vor dessen Einsatzbereitschaft liegt, wird auch dieser Pod zurückgestellt.
Aufgrund technischer Einschränkungen kann der HorizontalPodAutoscaler Controller nicht genau bestimmen, wann ein Pod zum ersten Mal bereit ist, wenn es darum geht, bestimmte CPU Metriken festzulegen. Stattdessen betrachtet er eine Pod als "not yet ready", wenn dieser noch nicht bereit ist und geht in "unready" über, innerhalb eines kurzen, konfigurierbaren Zeitfensters seit dem Start.
Dieser Wert wird mit dem Flag --horizontal-pod-autoscaler-initial-readiness-delay konfiguriert und ist standardmäßig auf 30 Sekunden eingestellt. Sobald ein Pod bereit ist, betrachtet er jeden Übergang zu Bereit als den ersten, wenn dies innerhalb einer längeren, konfigurierbaren Zeit seit seinem Start erfolgt ist. Dieser Wert wird mit dem Flag --horizontal-pod-autoscaler-cpu-initialization-period gesetzt und dessen Standardwert beträgt 5 Minuten.
Das Basisskalenverhältnis currentMetricValue / desiredMetricValue wird dann mit den restlichen Pods berechnet, die nicht zurückgestellt oder von den oben genannten Kriterien entsorgt wurden.
Wenn es irgendwelche fehlenden Metriken gab, berechnen wir den Durchschnitt konservativer, vorausgesetzt, dass die Pods 100% des gewünschten Wertes bei der Verringerung und 0% bei einer Vergrößerung verbrauchten. Dadurch wird die Dimension einer beliebigen potenziellen Skalierung verringert.
Wenn außerdem noch nicht bereite Pods vorhanden sind und es ohne Berücksichtigung fehlender Metriken oder noch nicht bereiter Pods skaliert wurde, wird konservativ davon ausgegangen, dass die noch nicht bereiten Pods 0% der gewünschten Metrik verbrauchen, was die Dimension einer Skalierung weiter dämpft.
Nach Berücksichtigung der noch nicht bereiten Pods und fehlender Metriken wird der Nutzungsgrad neu berechnet. Wenn das neue Verhältnis die Skalierungsrichtung umkehrt oder innerhalb der Toleranz liegt, wird das weitere Skalieren übersprungen. Andernfalls wird das neue Verhältnis zur Skalierung verwendet.
Beachte, dass der ursprüngliche Wert für die durchschnittliche Auslastung über den HorizontalPodAutoscaler Status zurückgemeldet wird, ohne die noch nicht bereiten Pods oder fehlende Metriken zu berücksichtigen, selbst wenn das neue Nutzungsverhältnis verwendet wird.
Wenn mehrere Metriken in einem HorizontalPodAutoscaler angegeben sind, wird die Berechnung für jede Metrik durchgeführt, und dann wird die größte der gewünschten Replikanzahl ausgewählt. Wenn eine dieser Metriken nicht in eine gewünschte Replikanzahl umgewandelt werden kann (z.B. aufgrund eines Fehlers beim Abrufen der Metriken aus den Metrik APIs), wird diese Skalierung übersprungen.
Schließlich, kurz bevor HPA das Ziel skaliert, wird die Skalierungsempfehlung aufgezeichnet. Der Controller berücksichtigt alle Empfehlungen innerhalb eines konfigurierbaren Fensters und wählt aus diesem Fenster die höchste Empfehlung aus. Dieser Wert kann mit dem Flag --horizontal-pod-autoscaler-downscale-stabilization konfiguriert werden, das standardmäßig auf 5 Minuten eingestellt ist. Dies bedeutet, dass die Skalierung schrittweise erfolgt, wodurch die Auswirkungen schnell schwankender metrischer Werte ausgeglichen werden.
API Objekt
Der Horizontal Pod Autoscaler ist eine API Ressource in der Kubernetes autoscaling API Gruppe.
Die aktuelle stabile Version, die nur die Unterstützung für die automatische Skalierung der CPU beinhaltet, befindet sich in der autoscaling/v1 API Version.
Die Beta-Version, welche die Skalierung des Speichers und benutzerdefinierte Metriken unterstützt, befindet sich unter autoscaling/v2beta2. Die in autoscaling/v2beta2 neu eingeführten Felder bleiben bei der Arbeit mit autoscaling/v1 als Anmerkungen erhalten.
Weitere Details über das API Objekt kann unter dem HorizontalPodAutoscaler Objekt gefunden werden.
Unterstützung des Horizontal Pod Autoscaler in kubectl
Der Horizontal Pod Autoscaler wird, wie jede API-Ressource, standardmäßig von kubectl unterstützt.
Ein neuer Autoskalierer kann mit dem Befehl kubectl create erstellt werden.
Das auflisten der Autoskalierer geschieht über kubectl get hpa und eine detaillierte Beschreibung erhält man mit kubectl describe hpa.
Letzendlich können wir einen Autoskalierer mit kubectl delete hpa löschen.
Zusätzlich gibt es einen speziellen Befehl kubectl autoscale zur einfachen Erstellung eines Horizontal Pod Autoscalers.
Wenn du beispielsweise kubectl autoscale rs foo --min=2 --max=5 --cpu-percent=80 ausführst, wird ein Autoskalierer für den ReplicaSet foo erstellt, wobei die Ziel-CPU-Auslastung auf 80% und die Anzahl der Replikate zwischen 2 und 5 gesetzt wird.
Die Detaildokumentation von kubectl autoscale kann hier gefunden werden.
Autoskalieren während rollierender Updates
Derzeit ist es in Kubernetes möglich, ein rollierendes Update durchzuführen, indem du den Replikationscontroller direkt verwaltest oder das Deployment Objekt verwendest, das die zugrunde liegenden Replica Sets für dich verwaltet. Der Horizontal Pod Autoscaler unterstützt nur den letztgenannten Ansatz: Der Horizontal Pod Autoscaler ist an das Deployment Objekt gebunden, er legt die Größe für das Deployment Objekt fest, und das Deployment ist für die Festlegung der Größen der zugrunde liegenden Replica Sets verantwortlich.
Der Horizontal Pod Autoscaler funktioniert nicht mit rollierendem Update durch direkte Manipulation vom Replikationscontrollern, d.h. du kannst einen Horizontal Pod Autoscaler nicht an einen Replikationscontroller binden und rollierend aktualisieren (z.B. mit kubectl rolling-update).
Der Grund dafür ist, dass beim Erstellen eines neuen Replikationscontrollers durch ein rollierendes Update der Horizontal Pod Autoscaler nicht an den neue Replikationscontroller gebunden wird.
Unterstützung von Abklingzeiten/Verzögerungen
Bei der Verwaltung der Größe einer Gruppe von Replikaten mit dem Horizontal Pod Autoscaler ist es möglich, dass die Anzahl der Replikate aufgrund der Dynamik der ausgewerteten Metriken häufig schwankt. Dies wird manchmal als thrashing, zu deutsch Flattern, bezeichnet.
Ab v1.6 kann ein Cluster Operator dieses Problem mitigieren, indem er die globalen HPA Einstellungen anpasst, die als Flags für die Komponente kube-controller-manager dargelegt werden:
Ab v1.12 erübrigt ein neues Update des Algorithmus die Notwendigkeit der Verzögerung beim hochskalieren.
--horizontal-pod-autoscaler-downscale-stabilization: Der Wert für diese Option ist eine Dauer, die angibt, wie lange der Autoscaler warten muss, bis nach Abschluss des aktuellen Skalierungsvorgangs ein weiterer Downscale durchgeführt werden kann. Der Standardwert ist 5 Minuten (5m0s).
Unterstützung von mehrere Metriken
Kubernetes 1.6 bietet Unterstützung für die Skalierung basierend auf mehreren Metriken. Du kannst die API Version autoscaling/v2beta2 verwenden, um mehrere Metriken für den Horizontal Pod Autoscaler zum Skalieren festzulegen. Anschließend wertet der Horizontal Pod Autoscaler Controller jede Metrik aus und schlägt eine neue Skalierung basierend auf diesen Metrik vor. Die größte der vorgeschlagenen Skalierung wird als neue Skalierung verwendet.
Unterstützung von benutzerdefinierte Metriken
Kubernetes 1.6 bietet Unterstützung für die Verwendung benutzerdefinierter Metriken im Horizontal Pod Autoscaler.
Du kannst benutzerdefinierte Metriken für den Horizontal Pod Autoscaler hinzufügen, die in der autoscaling/v2beta2 API verwendet werden.
Kubernetes fragt dann die neue API für die benutzerdefinierte Metriken ab, um die Werte der entsprechenden benutzerdefinierten Metriken zu erhalten.
Die Voraussetzungen hierfür werden im nachfolgenden Kapitel Unterstützung für die Metrik APIs geklärt.
Unterstützung der Metrik APIs
Standardmäßig ruft der HorizontalPodAutoscaler Controller Metriken aus einer Reihe von APIs ab. Damit dieser auf die APIs zugreifen kann, muss der Cluster Administratoren sicherstellen, dass:
-
Der API Aggregations Layer aktiviert ist.
-
Die entsprechenden APIs registriert sind:
-
Für Ressourcenmetriken ist dies die API
metrics.k8s.io, die im Allgemeinen von metrics-server bereitgestellt wird. Es kann als Cluster-Addon gestartet werden. -
Für benutzerdefinierte Metriken ist dies die API
custom.metrics.k8s.io. Diese wird vom "Adapter" API Servern bereitgestellt, welches von Anbietern von Metrik Lösungen beliefert wird. Überprüfe dies mit deiner Metrik Pipeline. Falls du deinen eigenen schreiben möchtest hilft dir folgender boilerplate um zu starten. -
Für externe Metriken ist dies die
external.metrics.k8s.ioAPI. Es kann sein, dass dies durch den benutzerdefinierten Metrik Adapter bereitgestellt wird.
-
-
Das Flag
--horizontal-pod-autoscaler-use-rest-clientsist auftrueoder ungesetzt. Wird dies auffalsegesetzt wird die Heapster basierte Autoskalierung aktiviert, welche veraltet ist.
Nächste Schritte
- Design Dokument Horizontal Pod Autoscaling.
- kubectl autoscale Befehl: kubectl autoscale.
- Verwenden des Horizontal Pod Autoscaler.
4.6 - Jobs ausführen
4.7 - Auf Anwendungen in einem Cluster zugreifen
4.8 - Überwachung, Protokollierung und Fehlerbehebung
4.9 - Kubernetes erweitern
4.10 - TLS
4.11 - Föderation
4.12 - Cluster-Daemons verwalten
5 - Tutorials
Dieser Abschnitt der Kubernetes-Dokumentation enthält Tutorials. Ein Tutorial zeigt, wie Sie ein Ziel erreichen, das größer ist als eine einzelne Aufgabe. Ein Tutorial besteht normalerweise aus mehreren Abschnitten, die jeweils eine Abfolge von Schritten haben. Bevor Sie die einzelnen Lernprogramme durchgehen, möchten Sie möglicherweise ein Lesezeichen zur Seite mit dem Standardisierten Glossar setzen um später Informationen nachzuschlagen.
Grundlagen
-
Kubernetes Basics ist ein ausführliches interaktives Lernprogramm, das Ihnen hilft, das Kubernetes-System zu verstehen und einige grundlegende Kubernetes-Funktionen auszuprobieren.
-
Einführung in Kubernetes (edX) (Englisch)
Konfiguration
Stateless Anwendungen
-
Freigeben einer externen IP-Adresse für den Zugriff auf eine Anwendung in einem Cluster
-
Beispiel: Bereitstellung der PHP-Gästebuchanwendung mit Redis
Stateful Anwendungen
Clusters
Services
Nächste Schritte
Wenn Sie ein Tutorial schreiben möchten, lesen Sie Seitenvorlagen verwenden für weitere Informationen zum Typ der Tutorial-Seite und zur Tutorial-Vorlage.
5.1 - Hallo Minikube
Dieses Tutorial zeigt Ihnen, wie Sie eine einfache "Hallo Welt" Node.js-Anwendung auf Kubernetes mit Minikube und Katacoda ausführen. Katacoda bietet eine kostenlose Kubernetes-Umgebung im Browser.
Ziele
- Stellen Sie eine Hallo-Welt-Anwendung für Minikube bereit.
- Führen Sie die App aus.
- Betrachten Sie die Log Dateien.
Bevor Sie beginnen
Dieses Lernprogramm enthält ein aus den folgenden Dateien erstelltes Container-Image:

var http = require('http');
var handleRequest = function(request, response) {
console.log('Received request for URL: ' + request.url);
response.writeHead(200);
response.end('Hello World!');
};
var www = http.createServer(handleRequest);
www.listen(8080);
FROM node:6.14.2
EXPOSE 8080
COPY server.js .
CMD node server.js
Weitere Informationen zum docker build Befehl, lesen Sie die Docker Dokumentation.
Erstellen Sie einen Minikube-Cluster
-
Klicken Sie auf Launch Terminal.
Hinweis: Wenn Sie Minikube lokal installiert haben, führen Sieminikube startaus. -
Öffnen Sie das Kubernetes-Dashboard in einem Browser:
minikube dashboard -
In einer Katacoda-Umgebung: Klicken Sie oben im Terminalbereich auf das Pluszeichen und anschließend auf Select port to view on Host 1.
-
In einer Katacoda-Umgebung: Geben Sie
30000ein und klicken Sie dann auf Display Port.
Erstellen eines Deployments
Ein Kubernetes Pod ist eine Gruppe von einem oder mehreren Containern, die zu Verwaltungs- und Netzwerkzwecken miteinander verbunden sind. Der Pod in diesem Tutorial hat nur einen Container. Ein Kubernetes Deployment überprüft den Zustand Ihres Pods und startet den Container des Pods erneut, wenn er beendet wird. Deployments sind die empfohlene Methode zum Verwalten der Erstellung und Skalierung von Pods.
-
Verwenden Sie den Befehl
kubectl create, um ein Deployment zu erstellen, die einen Pod verwaltet. Der Pod führt einen Container basierend auf dem bereitgestellten Docker-Image aus.kubectl create deployment hello-node --image=registry.k8s.io/echoserver:1.4 -
Anzeigen des Deployments:
kubectl get deploymentsAusgabe:
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE hello-node 1 1 1 1 1m -
Den Pod anzeigen:
kubectl get podsAusgabe:
NAME READY STATUS RESTARTS AGE hello-node-5f76cf6ccf-br9b5 1/1 Running 0 1m -
Cluster Events anzeigen:
kubectl get events -
Die Konfiguration von
kubectlanzeigen:kubectl config viewHinweis: Weitere Informationen zukubectl-Befehlen finden Sie im kubectl Überblick.
Erstellen Sie einen Service
Standardmäßig ist der Pod nur über seine interne IP-Adresse im Kubernetes-Cluster erreichbar. Um den "Hallo-Welt"-Container außerhalb des virtuellen Netzwerks von Kubernetes zugänglich zu machen, müssen Sie den Pod als Kubernetes Service verfügbar machen.
-
Stellen Sie den Pod mit dem Befehl
kubectl exposeim öffentlichen Internet bereit:kubectl expose deployment hello-node --type=LoadBalancer --port=8080Das Flag
--type = LoadBalancerzeigt an, dass Sie Ihren Service außerhalb des Clusters verfügbar machen möchten. -
Zeigen Sie den gerade erstellten Service an:
kubectl get servicesAusgabe:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE hello-node LoadBalancer 10.108.144.78 <pending> 8080:30369/TCP 21s kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 23mBei Cloud-Anbietern, die Load-Balancer unterstützen, wird eine externe IP-Adresse für den Zugriff auf den Dienst bereitgestellt. Bei Minikube ermöglicht der Typ
LoadBalancerden Dienst über den Befehlminikube serviceverfügbar zu machen. -
Führen Sie den folgenden Befehl aus:
minikube service hello-node -
In einer Katacoda-Umgebung: Klicken Sie auf das Pluszeichen und dann auf Select port to view on Host 1.
-
In einer Katacoda-Umgebung: Geben Sie "30369" ein (siehe Port gegenüber "8080" in der service ausgabe), und klicken Sie dann auf
Daraufhin wird ein Browserfenster geöffnet, in dem Ihre App ausgeführt wird und die Meldung "Hello World" (Hallo Welt) angezeigt wird.
Addons aktivieren
Minikube verfügt über eine Reihe von integrierten Add-Ons, die in der lokalen Kubernetes-Umgebung aktiviert, deaktiviert und geöffnet werden können.
-
Listen Sie die aktuell unterstützten Addons auf:
minikube addons listAusgabe:
addon-manager: enabled coredns: disabled dashboard: enabled default-storageclass: enabled efk: disabled freshpod: disabled heapster: disabled ingress: disabled kube-dns: enabled metrics-server: disabled nvidia-driver-installer: disabled nvidia-gpu-device-plugin: disabled registry: disabled registry-creds: disabled storage-provisioner: enabled -
Aktivieren Sie ein Addon, zum Beispiel
heapster:minikube addons enable heapsterAusgabe:
heapster was successfully enabled -
Sehen Sie sich den Pod und den Service an, den Sie gerade erstellt haben:
kubectl get pod,svc -n kube-systemAusgabe:
NAME READY STATUS RESTARTS AGE pod/heapster-9jttx 1/1 Running 0 26s pod/influxdb-grafana-b29w8 2/2 Running 0 26s pod/kube-addon-manager-minikube 1/1 Running 0 34m pod/kube-dns-6dcb57bcc8-gv7mw 3/3 Running 0 34m pod/kubernetes-dashboard-5498ccf677-cgspw 1/1 Running 0 34m pod/storage-provisioner 1/1 Running 0 34m NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/heapster ClusterIP 10.96.241.45 <none> 80/TCP 26s service/kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP 34m service/kubernetes-dashboard NodePort 10.109.29.1 <none> 80:30000/TCP 34m service/monitoring-grafana NodePort 10.99.24.54 <none> 80:30002/TCP 26s service/monitoring-influxdb ClusterIP 10.111.169.94 <none> 8083/TCP,8086/TCP 26s -
Deaktivieren Sie
heapster:minikube addons disable heapsterAusgabe:
heapster was successfully disabled
Aufräumen
Jetzt können Sie die in Ihrem Cluster erstellten Ressourcen bereinigen:
kubectl delete service hello-node
kubectl delete deployment hello-node
Stoppen Sie optional die virtuelle Minikube-Maschine (VM):
minikube stop
Löschen Sie optional die Minikube-VM:
minikube delete
Nächste Schritte
- Lernen Sie mehr über Bereitstellungsobjekte.
- Lernen Sie mehr über Anwendungen bereitstellen.
- Lernen Sie mehr über Serviceobjekte.
5.2 - Kubernetes Grundlagen lernen
Kubernetes Grundlagen
Dieses Tutorial bietet einen Überblick über die Grundlagen des Kubernetes-Cluster-Orchestrierungssystems. Jedes Modul enthält einige Hintergrundinformationen zu den wichtigsten Funktionen und Konzepten von Kubernetes sowie ein interaktives Online-Lernprogramm. Mit diesen interaktiven Lernprogrammen können Sie einen einfachen Cluster und seine containerisierten Anwendungen selbst verwalten.
Mithilfe der interaktiven Tutorials können Sie Folgendes lernen:
- Eine containerisierte Anwendung in einem Cluster bereitstellen
- Skalieren des Deployments
- Aktualisieren der containerisierten Anwendung mit einer neuen Softwareversion
- Debuggen der containerisierten Anwendung
In den Lernprogrammen wird mit Katacoda ein virtuelles Terminal in Ihrem Webbrowser ausgeführt, in dem Minikube ausgeführt wird. Dies ist eine kleine lokale Bereitstellung von Kubernetes, die überall ausgeführt werden kann. Es muss keine Software installiert oder konfiguriert werden. Jedes interaktive Lernprogramm wird direkt von Ihrem Webbrowser aus ausgeführt.
Was kann Kubernetes für Sie tun?
Bei modernen Webservices erwarten Benutzer, dass Anwendungen rund um die Uhr verfügbar sind, und Entwickler erwarten, mehrmals täglich neue Versionen dieser Anwendungen bereitzustellen (deployen). Containerisierung hilft bei der Paketierung von Software, um diese Ziele zu erreichen, sodass Anwendungen einfach und schnell ohne Ausfallzeiten veröffentlicht und aktualisiert werden können. Kubernetes hilft Ihnen dabei, sicherzustellen, dass diese Containeranwendungen immer dort laufen, wo und wann Sie möchten, und hilft Ihnen, die Ressourcen und Tools zu finden, die Sie zum Arbeiten benötigen. Kubernetes ist eine produktionsbereite Open-Source-Plattform, die auf der gesammelten Erfahrung von Google in der Container-Orchestrierung basiert und mit den besten Ideen der Community kombiniert wird.
Kubernetes Grundlagen Module






5.2.1 - Einen Cluster erstellen
5.2.1.1 - Minikube zum Erstellen eines Clusters verwenden
Ziele
- Erfahren Sie, was ein Kubernetes-Cluster ist.
- Erfahren Sie, was Minikube ist.
- Starten Sie einen Kubernetes-Cluster mit einem Online-Terminal.
Kubernetes Clusters
Kubernetes koordiniert hochverfügbare Cluster von Computern, die miteinander verbunden sind, um als eine Einheit zu arbeiten. Die Abstraktionen in Kubernetes ermöglichen es Ihnen, containerisierte Anwendungen in einem Cluster bereitzustellen, ohne sie spezifisch an einzelne Maschinen zu binden. Um dieses neue Bereitstellungsmodell nutzen zu können, müssen Anwendungen so gebündelt werden, dass sie von einzelnen Hosts entkoppelt werden: Sie müssen in Container verpackt werden. Containerisierte Anwendungen sind flexibler und verfügbarer als in früheren Bereitstellungsmodellen, bei denen Anwendungen direkt auf bestimmten Computern als tief in den Host integrierte Pakete installiert wurden. Kubernetes automatisiert die Verteilung und Planung von Anwendungscontainern über einen Cluster hinweg auf effizientere Weise. Kubernetes ist eine Open-Source-Plattform und produktionsreif.
Ein Kubernetes-Cluster besteht aus zwei Arten von Ressourcen:
- Der Master koordiniert den Cluster
- Nodes sind die Arbeiter, die Anwendungen ausführen
Zusammenfassung:
- Kubernetes-Cluster
- Minikube
Kubernetes ist eine produktionsreife Open-Source-Plattform, die die Bereitstellung (scheduling) und Ausführung von Anwendungscontainern innerhalb und zwischen Computerclustern koordiniert.
Cluster-Diagramm

Der Master ist für die Verwaltung des Clusters verantwortlich. Der Master koordiniert alle Aktivitäten in Ihrem Cluster, z. B. das Planen von Anwendungen, das Verwalten des gewünschten Status der Anwendungen, das Skalieren von Anwendungen und das Rollout neuer Updates.
Ein Node ist eine VM oder ein physischer Computer, der als Arbeitsmaschine in einem Kubernetes-Cluster dient. Jeder Node verfügt über ein Kubelet, einen Agenten zur Verwaltung des Node und zur Kommunikation mit dem Kubernetes-Master. Der Node sollte auch über Werkzeuge zur Abwicklung von Containeroperationen verfügen, z. B. Docker oder rkt. Ein Kubernetes-Cluster, das den Produktionsverkehr abwickelt, sollte aus mindestens drei Nodes bestehen.
Master verwalten den Cluster und die Nodes werden zum Hosten der laufenden Anwendungen verwendet.
Wenn Sie Anwendungen auf Kubernetes bereitstellen, weisen Sie den Master an, die Anwendungscontainer zu starten. Der Master plant die Ausführung der Container auf den Nodes des Clusters. Die Nodes kommunizieren über die Kubernetes-API mit dem Master, die der Master bereitstellt. Endbenutzer können die Kubernetes-API auch direkt verwenden, um mit dem Cluster zu interagieren.
Ein Kubernetes-Cluster kann auf physischen oder virtuellen Maschinen bereitgestellt werden. Um mit der Entwicklung von Kubernetes zu beginnen, können Sie Minikube verwenden. Minikube ist eine einfache Kubernetes-Implementierung, die eine VM auf Ihrem lokalen Computer erstellt und einen einfachen Cluster mit nur einem Knoten bereitstellt. Minikube ist für Linux-, MacOS- und Windows-Systeme verfügbar. Die Minikube-CLI bietet grundlegende Bootstrapping-Vorgänge für die Arbeit mit Ihrem Cluster, einschließlich Start, Stopp, Status und Löschen. Für dieses Lernprogramm verwenden Sie jedoch ein bereitgestelltes Online-Terminal mit vorinstalliertem Minikube.
Nun, da Sie wissen, was Kubernetes ist, schreiten wir zum Online-Tutorial und starten unseren ersten Cluster!
5.2.1.2 - Interaktives Lernprogramm - Erstellen eines Clusters
5.2.2 - Eine App bereitstellen
5.2.2.1 - Verwenden von kubectl zum Erstellen eines Deployments
Ziele
- Erfahren Sie mehr über Anwendungsbereitstellungen.
- Stellen Sie Ihre erste App auf Kubernetes mit kubectl bereit.
Kubernetes-Bereitstellungen (Deployments)
Sobald Sie einen Kubernetes-Cluster ausgeführt haben, können Sie Ihre containerisierten Anwendungen darüber bereitstellen. Dazu erstellen Sie eine Kubernetes Deployment-Konfiguration. Das Deployment weist Kubernetes an, wie Instanzen Ihrer Anwendung erstellt und aktualisiert werden. Nachdem Sie ein Deployment erstellt haben, plant der Kubernetes-Master die genannten Anwendungsinstanzen für einzelne Nodes im Cluster.
Sobald die Anwendungsinstanzen erstellt wurden, überwacht ein Kubernetes Deployment Controller diese Instanzen kontinuierlich. Wenn der Node, der eine Instanz hostet, ausfällt oder gelöscht wird, ersetzt der Deployment Controller die Instanz durch eine Instanz auf einem anderen Node im Cluster. Dies bietet einen Selbstheilungsmechanismus, um Maschinenausfälle oder -wartungen zu vermeiden.
In einer Welt vor der Orchestrierung wurden häufig Installationsskripts zum Starten von Anwendungen verwendet, sie erlaubten jedoch keine Wiederherstellung nach einem Maschinenausfall. Kubernetes Deployments erstellen Ihre Anwendungsinstanzen und sorgen dafür, dass sie über mehrere Nodes hinweg ausgeführt werden. Dadurch bieten Kubernetes Deployments einen grundlegend anderen Ansatz für die Anwendungsverwaltung.
Zusammenfassung:
- Deployments
- Kubectl
Eine Bereitstellung (Deployment) ist für das Erstellen und Aktualisieren von Instanzen Ihrer Anwendung verantwortlich
Erste App auf Kubernetes bereitstellen

Sie können eine Bereitstellung mithilfe der Kubernetes-Befehlszeilenschnittstelle Kubectl erstellen und verwalten. Kubectl verwendet die Kubernetes-API, um mit dem Cluster zu interagieren. In diesem Modul lernen Sie die gebräuchlichsten Kubectl-Befehle kennen, die zum Erstellen von Deployments zum Ausführen Ihrer Anwendungen in einem Kubernetes-Cluster erforderlich sind.
Wenn Sie ein Deployment erstellen, müssen Sie das Container-Image für Ihre Anwendung und die Anzahl der Replikate angeben, die Sie ausführen möchten. Sie können diese Informationen später ändern, indem Sie Ihr Deployment aktualisieren; In den Modulen 5 und 6 des Bootcamps wird diskutiert, wie Sie Ihre Deployments skalieren und aktualisieren können.
Anwendungen müssen in eines der unterstützten Containerformate gepackt werden, um auf Kubernetes bereitgestellt zu werden
Für unser erstes Deployment verwenden wir eine Node.js-Anwendung, die in einem Docker-Container verpackt ist. Um die Node.js-Anwendung zu erstellen und den Docker-Container bereitzustellen, folgen Sie den Anweisungen im Hello Minikube tutorial.
Nun, da Sie wissen, was Deployments sind, gehen wir zum Online-Tutorial und stellen unsere erste App bereit!
5.2.2.2 - Interaktives Lernprogramm - Bereitstellen einer App
5.2.3 - Entdecken Sie Ihre App
5.2.3.1 - Anzeigen von Pods und Nodes
Ziele:
- Erfahren Sie mehr über Kubernetes Pods.
- Erfahren Sie mehr über Kubernetes-Nodes.
- Beheben Sie Fehler in bereitgestellten Anwendungen.
Kubernetes Pods
Als Sie ein Deployment in Modul 2, hat Kubernetes einen Pod erstellt, der Ihre Anwendungsinstanz hostet. Ein Pod ist eine Kubernetes-Abstraktion, die eine Gruppe von einem oder mehreren Anwendungscontainern (z. B. Docker oder rkt) und einigen gemeinsam genutzten Ressourcen für diese Container darstellt. Diese Ressourcen umfassen:
- Gemeinsamer Speicher, als Volumes
- Networking, als eindeutige Cluster-IP-Adresse
- Informationen zur Ausführung der einzelnen Container, wie z.B. die Container-Image-Version oder bestimmte Ports, die verwendet werden sollen.
Ein Pod stellt einen anwendungsspezifischen "logischen Host" dar und kann verschiedene Anwendungscontainer enthalten, die relativ eng gekoppelt sind. Ein Pod kann beispielsweise sowohl den Container mit Ihrer Node.js-Applikation als auch einen anderen Container beinhalten, der die vom Webserver Node.js zu veröffentlichenden Daten einspeist. Die Container in einem Pod teilen sich eine IP-Adresse und einen Portbereich, sind immer kolokalisiert und gemeinsam geplant und laufen in einem gemeinsamen Kontext auf demselben Node.
Zusammenfassung:
- Pods
- Nodes
- Kubectl-Hauptbefehle
Ein Pod ist eine Gruppe von einem oder mehreren Anwendungscontainern (z. B. Docker oder rkt) und enthält gemeinsam genutzten Speicher (Volumes), IP-Adresse und Informationen zur Ausführung.
Pods-Übersicht

Nodes
Ein Pod läuft immer auf einem Node. Ein Node ist eine Arbeitsmaschine in Kubernetes und kann je nach Cluster entweder eine virtuelle oder eine physische Maschine sein. Jeder Node wird vom Master verwaltet. Ein Node kann über mehrere Pods verfügen, und der Kubernetes-Master übernimmt automatisch die Planung der Pods für die Nodes im Cluster. Die automatische Zeitplanung des Masters berücksichtigt die verfügbaren Ressourcen auf jedem Node.
Auf jedem Kubernetes Node läuft mindestens:
- Kubelet, ein Prozess, der für die Kommunikation zwischen dem Kubernetes Master und dem Node verantwortlich ist; Er verwaltet die Pods und die auf einer Maschine laufenden Container.
- Eine Containerlaufzeit (wie Docker, rkt), die für das Abrufen des Containerabbilds aus einer Registry, das Entpacken des Containers und das Ausführen der Anwendung verantwortlich ist.
Container sollten nur dann gemeinsam in einem Pod geplant werden, wenn sie eng miteinander verbunden sind und Ressourcen wie Festplatten gemeinsam nutzen müssen.
Node Überblick

Troubleshooting mit kubectl
In Modul 2 erstellt haben, haben Sie die Befehlszeilenschnittstelle von Kubectl verwendet. Sie verwenden sie weiterhin in Modul 3, um Informationen zu den bereitgestellten Anwendungen und ihren Umgebungen zu erhalten. Die häufigsten Operationen können mit den folgenden kubectl-Befehlen ausgeführt werden:
- kubectl get - Ressourcen auflisten
- kubectl describe - Detaillierte Informationen zu einer Ressource anzeigen
- kubectl logs - Die Logdateien von einem Container in einem Pod anzigen
- kubectl exec - Einen Befehl für einen Container in einem Pod ausführen
Mit diesen Befehlen können Sie sehen, wann Anwendungen bereitgestellt wurden, ihren aktuellen Status anzeigen, sehen wo sie ausgeführt werden und wie sie konfiguriert sind.
Nun, da wir mehr über unsere Clusterkomponenten und die Befehlszeile wissen, wollen wir unsere Anwendung untersuchen.
Ein Node ist eine Arbeitsmaschine in Kubernetes und kann je nach Cluster eine VM oder eine physische Maschine sein. Auf einem Node können mehrere Pods laufen.
5.2.3.2 - Interaktives Lernprogramm - Entdecken Sie Ihre App
5.2.4 - Machen Sie Ihre App öffentlich zugänglich
5.2.4.1 - Verwendung eines Services zum Veröffentlichen Ihrer App
Ziele:
- Erfahren Sie mehr über einen Service in Kubernetes
- Verstehen, wie Labels und LabelSelector-Objekte sich auf einen Dienst beziehen
- Stellen Sie eine Anwendung außerhalb eines Kubernetes-Clusters mithilfe eines Services bereit
Überblick über Kubernetes Services
Kubernetes Pods sind sterblich. Pods haben tatsächlich einen Lebenszyklus. Wenn ein Worker-Node stirbt, gehen auch die auf dem Knoten laufenden Pods verloren. Ein ReplicaSet kann dann durch Erstellen neuer Pods dynamisch den Cluster in den gewünschten Status zurückversetzen, damit die Anwendung weiterhin ausgeführt werden kann. Als ein anderes Beispiel betrachten wir ein Bildverarbeitungs-Backend mit 3 Reproduktionen. Diese Repliken sind austauschbar; Das Front-End-System sollte sich nicht für Backend-Replikate interessieren, selbst wenn ein Pod verloren geht und neu erstellt wird. Allerdings hat jeder Pod in einem Kubernetes-Cluster eine eindeutige IP-Adresse, sogar Pods auf demselben Knoten. Daher müssen Änderungen automatisch zwischen den Pods abgeglichen werden, damit Ihre Anwendungen weiterhin funktionieren.
Ein Dienst in Kubernetes ist eine Abstraktion, die einen logischen Satz von Pods und eine Richtlinie für den Zugriff auf diese definiert. Services ermöglichen eine lose Kopplung zwischen abhängigen Pods. Ein Service ist in YAML (bevorzugt) oder JSON spezifiziert, wie alle Kubernetes-Objekte. Die Gruppe von Pods, auf die ein Service abzielt, wird normalerweise von einem LabelSelector bestimmt (Siehe unten, warum Sie möglicherweise wünschen, einen Service ohne selector in die Spezifikation aufzunehmen).
Obwohl jeder Pod über eine eindeutige IP-Adresse verfügt, werden diese IP-Adressen nicht außerhalb des Clusters ohne einen Service verfügbar gemacht. Services ermöglichen es Ihren Anwendungen, Datenverkehr zu empfangen. Services können auf unterschiedliche Weise verfügbar gemacht werden, indem Sie einen type in der ServiceSpec angeben:
- ClusterIP (Standardeinstellung) - Macht den Service auf einer internen IP im Cluster verfügbar. Durch diesen Typ ist der Service nur innerhalb des Clusters erreichbar.
- NodePort - Macht den Dienst auf demselben Port jedes ausgewählten Knotens im Cluster mithilfe von NAT verfügbar. Macht einen Dienst von außerhalb des Clusters mit
<NodeIP>:<NodePort>zugänglich. Oberhalb von ClusterIP positioniert. - LoadBalancer - Erstellt einen externen Load-Balancer in der aktuellen Cloud (sofern unterstützt) und weist dem Service eine feste externe IP zu. Oberhalb von NodePort positioniert.
- ExternalName - Macht den Dienst mit einem beliebigen Namen verfügbar (Spezifiziert durch
externalNamein der Konfiguration) indem Sie einen CNAME-Datensatz mit dem Namen zurückgeben. Kein Proxy wird verwendet. Für diesen Typ ist v1.7 vonkube-dnsoder höher erforderlich.
Weitere Informationen zu den verschiedenen Arten von Services finden Sie im Verwendung von Source IP Tutorial. Siehe auch Anwendungen mit Services verbinden.
Beachten Sie außerdem, dass es einige Anwendungsfälle mit Services gibt, bei denen keine selector Spezifikation in der Konfiguration nötig ist. Ein Service ohne selector erstellt auch nicht das entsprechende Endpunktobjekt. Auf diese Weise können Benutzer einen Service manuell bestimmten Endpunkten zuordnen. Eine andere Möglichkeit, warum es keinen Selektor gibt, ist die strikte Verwendung type: ExternalName.
Zusammenfassung:
- Pods externen Verkehr aussetzen
- Lastverteilung über mehrere Pods
- Labels verwenden
Ein Kubernetes Service ist eine Abstraktionsschicht, die einen logischen Satz von Pods definiert und den externen Datenverkehr, Lastverteilung und Service Discovery für diese Pods ermöglicht.
Services und Labels

Ein Service leitet den Traffic über eine Reihe von Pods. Services sind die Abstraktion, die es Pods ermöglichen, in Kubernetes zu sterben und sich zu replizieren, ohne die Anwendung zu beeinträchtigen. Die Erkennung und das Routing zwischen abhängigen Pods (z. B. Frontend- und Backend-Komponenten in einer Anwendung) werden von Kubernetes Services ausgeführt.
Services passen zu einem Satz von Pods mit Labels und Selektoren, eine einfache Gruppierung, die logische Operationen an Objekten in Kubernetes ermöglicht. Labels sind Schlüssel/Wert-Paare, die an Objekte angehängt werden, und können auf verschiedene Arten verwendet werden:
- Festlegen von Objekten für Entwicklung, Test und Produktion
- Versions-Tags einbetten
- Klassifizieren von Objekten mithilfe von Tags
Sie können einen Service gleichzeitig mit dem Erstellen eines Deployments erstellen, indem Sie --expose in kubectl verwenden.

Labels können zum Zeitpunkt der Erstellung oder zu einem späteren Zeitpunkt an Objekte angehängt werden. Sie können jederzeit geändert werden. Lassen Sie uns jetzt unsere Anwendung mit einem Service verfügbar machen und einige Labels anbringen.
5.2.4.2 - Interaktives Lernprogramm - Ihre App öffentlich zugänglich machen
5.2.5 - Skalieren Sie Ihre App
5.2.5.1 - Mehrere Instanzen Ihrer App ausführen
Ziele:
- Skalieren einer App mit kubectl.
Eine Anwendung skalieren
In den vorherigen Modulen haben wir ein Deployment erstellt, und es dann öffentlich mittels einem Service bereitgestellt. Das Deployment hat nur einen Pod für die Ausführung unserer Anwendung erstellt. Wenn der Anfragen zunehmen, müssen wir die Anwendung skalieren, um den Anforderungen der Benutzer gerecht zu werden.
Skalieren wird durch Ändern der Anzahl der Repliken in einer Bereitstellung erreichtt
Zusammenfassung:
- Skalieren eines Deployments
Sie können von Anfang an eine Bereitstellung mit mehreren Instanzen erstellen, indem Sie den Parameter --replicas mit dem Befehl `kubectl run` verwenden
Skalierung - Übersicht


Durch das Skalieren eines Deployments wird sichergestellt, dass neue Pods erstellt und auf Nodes mit verfügbaren Ressourcen geplant werden. Durch die Skalierung wird die Anzahl der Pods auf den neuen gewünschten Status erhöht. Kubernetes unterstützt auch die automatische Skalierung von Pods, dies ist jedoch außerhalb des Anwendungsbereichs dieses Lernprogramms. Die Skalierung auf Null ist ebenfalls möglich und beendet alle Pods der angegebenen Bereitstellung.
Das Ausführen mehrerer Instanzen einer Anwendung erfordert eine Möglichkeit, den Datenverkehr auf alle Anwendungen zu verteilen. Services verfügen über eine integrierte Lastverteilung, der den Netzwerkverkehr auf alle Pods eines bereitgestellten Deployments verteilt. Die Services überwachen kontinuierlich die laufenden Pods mithilfe von Endpunkten, um sicherzustellen, dass der Datenverkehr nur an die verfügbaren Pods gesendet wird.
Die Skalierung wird durch Ändern der Anzahl der Repliken in einer Bereitstellung erreicht.
Wenn Sie mehrere Instanzen einer Anwendung ausgeführt haben, können Sie Rolling-Updates ohne Ausfallzeiten durchführen. Wir werden das im nächsten Modul behandeln. Nun gehen wir zum Online-Terminal und skalieren unsere Anwendung.
5.2.5.2 - Interaktives Lernprogramm - Skalieren Ihrer App
5.2.6 - Aktualisieren Sie Ihre App
5.2.6.1 - Durchführen eines Rolling-Updates
Objectives
- Führen Sie ein Rolling-Update mit kubectl durch.
Anwendung aktualisieren
Anwender erwarten, dass Anwendungen jederzeit verfügbar sind, und Entwickler haben das Bedürfnis mehrmals täglich neue Versionen davon bereitstellen. In Kubernetes geschieht dies mit laufenden Aktualisierungen. Rolling Updates ermöglichen die Aktualisierung von Deployments ohne Ausfallzeit, indem Pod-Instanzen inkrementell mit neuen aktualisiert werden. Die neuen Pods werden auf Nodes mit verfügbaren Ressourcen geplant.
Im vorherigen Modul haben wir unsere Anwendung so skaliert, dass mehrere Instanzen ausgeführt werden können. Dies ist eine Voraussetzung, um Aktualisierungen durchzuführen, ohne die Anwendungsverfügbarkeit zu beeinträchtigen. Standardmäßig ist die maximale Anzahl von Pods, die während der Aktualisierung nicht verfügbar sein kann, und die maximale Anzahl neuer Pods, die erstellt werden können, 1. Beide Optionen können entweder nach Zahlen oder Prozentsätzen (von Pods) konfiguriert werden. In Kubernetes werden Updates versioniert und jedes Deployment-Update kann auf die vorherige (stabile) Version zurückgesetzt werden.
Zusammenfassung:
- App aktualisieren
Rolling Updates ermöglichen die Aktualisierung der Deployments ohne Ausfallzeit, indem Pod-Instanzen inkrementell mit neuen aktualisiert werden.
Rolling Updates - Übersicht




Ähnlich wie bei der Anwendungsskalierung wird der Datenverkehr, wenn ein Deployment öffentlich verfügbar gemacht wird, während der Aktualisierung auf die verfügbaren Pods lastverteilt. Ein verfügbarer Pod ist eine Instanz, die den Benutzern der Anwendung zur Verfügung steht.
Rolling Updates ermöglichen die folgenden Aktionen:
- Heraufstufen einer Anwendung von einer Umgebung in eine andere (über Aktualisierungen der Container-Images)
- Rollback auf frühere Versionen
- Kontinuierliche Integration und kontinuierliche Bereitstellung von Anwendungen ohne Ausfallzeiten
Wenn ein Deployment öffentlich verfügbar gemacht wird, wird der Verkehr während des Updates nur auf verfügbare Pods verteilt.
Im folgenden interaktiven Tutorial werden wir unsere Anwendung auf eine neue Version aktualisieren und auch einen Rollback durchführen.
5.2.6.2 - Interaktives Lernprogramm - Aktualisieren Ihrer App
6 - Referenzen
Dieser Abschnitt der Kubernetes-Dokumentation enthält Referenzinformationen.
API-Referenz
- Kubernetes API Überblick - Übersicht über die API für Kubernetes.
- Kubernetes API Versionen
API-Clientbibliotheken
Um die Kubernetes-API aus einer Programmiersprache aufzurufen, können Sie Clientbibliotheken verwenden. Offiziell unterstützte Clientbibliotheken:
- Kubernetes Go Clientbibliothek
- Kubernetes Python Clientbibliothek
- Kubernetes Java Clientbibliothek
- Kubernetes JavaScript Clientbibliothek
CLI-Referenz
- kubectl - Haupt-CLI-Tool zum Ausführen von Befehlen und zum Verwalten von Kubernetes-Clustern.
- JSONPath - Syntax-Anleitung zur Verwendung von JSONPath expressionen mit kubectl.
- kubeadm - CLI-Tool zur einfachen Bereitstellung eines sicheren Kubernetes-Clusters.
- kubefed - CLI-Tool zur Verwaltung Ihres Clusterverbunds.
Konfigurationsreferenz
- kubelet - Der primäre Node-Agent, der auf jedem Node ausgeführt wird. Das Kubelet betrachtet eine Reihe von PodSpecs und stellt sicher, dass die beschriebenen Container ordnungsgemäß ausgeführt werden.
- kube-apiserver - REST-API zur Überprüfung und Konfiguration von Daten für API-Objekte wie Pods, Services und Replikationscontroller.
- kube-controller-manager - Daemon, der die mit Kubernetes gelieferten zentralen Regelkreise einbettet.
- kube-proxy - Kann einfache TCP/UDP-Stream-Weiterleitung oder Round-Robin-TCP/UDP-Weiterleitung über eine Reihe von Back-Ends durchführen.
- kube-scheduler - Scheduler, der Verfügbarkeit, Leistung und Kapazität verwaltet.
- federation-apiserver - API-Server für Cluster Föderationen.
- federation-controller-manager - Daemon, der die zentralen Regelkreise einbindet, die mit der Kubernetes-Föderation ausgeliefert werden.
Design Dokumentation
Ein Archiv der Designdokumente für Kubernetes-Funktionalität. Gute Ansatzpunkte sind Kubernetes Architektur und Kubernetes Design Übersicht.
6.1 - Standardisiertes Glossar
6.2 - Kubernetes Probleme und Sicherheit
6.3 - Verwendung der Kubernetes-API
6.4 - API Zugriff
6.5 - API Referenzinformationen
6.6 - Föderation API
6.7 - Setup-Tools Referenzinformationen
6.8 - Befehlszeilen-Werkzeug Referenzinformationen
6.9 - kubectl CLI
6.9.1 - kubectl Spickzettel
Siehe auch: Kubectl Überblick und JsonPath Dokumentation.
Diese Seite ist eine Übersicht über den Befehl kubectl.
kubectl - Spickzettel
Kubectl Autovervollständigung
BASH
source <(kubectl completion bash) # Wenn Sie autocomplete in bash in der aktuellen Shell einrichten, sollte zuerst das bash-completion-Paket installiert werden.
echo "source <(kubectl completion bash)" >> ~/.bashrc # Fügen Sie der Bash-Shell dauerhaft Autocomplete hinzu.
Sie können auch ein Abkürzungsalias für kubectl verwenden, welches auch mit Vervollständigung funktioniert:
alias k=kubectl
complete -F __start_kubectl k
ZSH
source <(kubectl completion zsh) # Richten Sie Autocomplete in zsh in der aktuellen Shell ein
echo "if [ $commands[kubectl] ]; then source <(kubectl completion zsh); fi" >> ~/.zshrc # Fügen Sie der Zsh-Shell dauerhaft Autocomplete hinzu
Kubectl Kontext und Konfiguration
Legen Sie fest, welcher Kubernetes-Cluster mit kubectl kommuniziert und dessen Konfiguration ändert. Lesen Sie die Dokumentation Authentifizierung mit kubeconfig über mehrere Cluster hinweg für ausführliche Informationen zur Konfigurationsdatei.
kubectl config view # Zusammengeführte kubeconfig-Einstellungen anzeigen.
# Verwenden Sie mehrere kubeconfig-Dateien gleichzeitig und zeigen Sie die zusammengeführte Konfiguration an
KUBECONFIG=~/.kube/config:~/.kube/kubconfig2 kubectl config view
# Zeigen Sie das Passwort für den e2e-Benutzer an
kubectl config view -o jsonpath='{.users[?(@.name == "e2e")].user.password}'
kubectl config view -o jsonpath='{.users[].name}' # den ersten Benutzer anzeigen
kubectl config view -o jsonpath='{.users[*].name}' # eine Liste der Benutzer erhalten
kubectl config current-context # den aktuellen Kontext anzeigen
kubectl config use-context my-cluster-name # Setzen Sie den Standardkontext auf my-cluster-name
# Fügen Sie Ihrer kubeconf einen neuen Cluster hinzu, der basic auth unterstützt
kubectl config set-credentials kubeuser/foo.kubernetes.com --username=kubeuser --password=kubepassword
# Legen Sie einen Kontext fest, indem Sie einen bestimmten Benutzernamen und einen bestimmten Namespace verwenden.
kubectl config set-context gce --user=cluster-admin --namespace=foo \
&& kubectl config use-context gce
kubectl config unset users.foo # delete user foo
Apply
apply verwaltet Anwendungen durch Dateien, die Kubernetes-Ressourcen definieren. Es erstellt und aktualisiert Ressourcen in einem Cluster durch Ausführen von kubectl apply. Dies ist die empfohlene Methode zur Verwaltung von Kubernetes-Anwendungen in der Produktion. Lesen Sie die ausführliche Kubectl Dokumentation für weitere Informationen.
Objekte erstellen
Kubernetes Manifeste können in Json oder Yaml definiert werden. Die Dateierweiterungen .yaml,
.yml, und .json können verwendet werden.
kubectl apply -f ./my-manifest.yaml # Ressource(n) erstellen
kubectl apply -f ./my1.yaml -f ./my2.yaml # aus mehreren Dateien erstellen
kubectl apply -f ./dir # Erstellen Sie Ressourcen in allen Manifestdateien in Verzeichnis
kubectl apply -f https://git.io/vPieo # Ressource(n) aus URL erstellen
kubectl create deployment nginx --image=nginx # Starten Sie eine einzelne Instanz von Nginx
kubectl explain pods,svc # Zeigen Sie die Dokumentation für Pod und SVC Manifeste an
# Erstellen Sie mehrere YAML-Objekte aus stdin
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Pod
metadata:
name: busybox-sleep
spec:
containers:
- name: busybox
image: busybox
args:
- sleep
- "1000000"
---
apiVersion: v1
kind: Pod
metadata:
name: busybox-sleep-less
spec:
containers:
- name: busybox
image: busybox
args:
- sleep
- "1000"
EOF
# Erstellen Sie ein "Secret" mit mehreren Schlüsseln
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Secret
metadata:
name: mysecret
type: Opaque
data:
password: $(echo -n "s33msi4" | base64 -w0)
username: $(echo -n "jane" | base64 -w0)
EOF
Suchen und Anzeigen von Ressourcen
# Get Befehle mit grundlegenden Ausgaben
kubectl get services # Listen Sie alle Dienste im Namespace auf
kubectl get pods --all-namespaces # Listen Sie alle Pods in allen Namespaces auf
kubectl get pods -o wide # Listen Sie alle Pods im Namespace mit weiteren Details auf
kubectl get deployment my-dep # Listen Sie eine bestimmte Bereitstellung auf
kubectl get pods # Listen Sie alle Pods im Namespace auf
# Describe Befehle mit ausführlicher Ausgabe
kubectl describe nodes my-node
kubectl describe pods my-pod
kubectl get services --sort-by=.metadata.name # Listen Sie Dienste nach Namen sortiert auf
# Listen Sie Pods Sortiert nach Restart Count auf
kubectl get pods --sort-by='.status.containerStatuses[0].restartCount'
# Erhalten Sie die Versionsbezeichnung aller Pods mit der Bezeichnung app=cassandra
kubectl get pods --selector=app=cassandra -o \
jsonpath='{.items[*].metadata.labels.version}'
# Alle Worker-Knoten abrufen (verwenden Sie einen Selektor, um Ergebnisse auszuschließen,
# die ein Label mit dem Namen 'node-role.kubernetes.io/master' tragen).
kubectl get node --selector='!node-role.kubernetes.io/master'
# Zeigen Sie alle laufenden Pods im Namespace an
kubectl get pods --field-selector=status.phase=Running
# Rufen Sie die externe IP aller Nodes ab
kubectl get nodes -o jsonpath='{.items[*].status.addresses[?(@.type=="ExternalIP")].address}'
# Listet die Namen der Pods auf, die zu einem bestimmten RC gehören
# Der Befehl "jq" ist nützlich für Transformationen, die für jsonpath zu komplex sind. Sie finden ihn unter https://stedolan.github.io/jq/
sel=${$(kubectl get rc my-rc --output=json | jq -j '.spec.selector | to_entries | .[] | "\(.key)=\(.value),"')%?}
echo $(kubectl get pods --selector=$sel --output=jsonpath={.items..metadata.name})
# Labels für alle Pods anzeigen (oder jedes andere Kubernetes-Objekt, das labelling unterstützt)
# Verwendet auch "jq"
for item in $( kubectl get pod --output=name); do printf "Labels for %s\n" "$item" | grep --color -E '[^/]+$' && kubectl get "$item" --output=json | jq -r -S '.metadata.labels | to_entries | .[] | " \(.key)=\(.value)"' 2>/dev/null; printf "\n"; done
# Prüfen Sie, welche Nodes bereit sind
JSONPATH='{range .items[*]}{@.metadata.name}:{range @.status.conditions[*]}{@.type}={@.status};{end}{end}' \
&& kubectl get nodes -o jsonpath="$JSONPATH" | grep "Ready=True"
# Listen Sie alle Secrets auf, die derzeit von einem Pod verwendet werden
kubectl get pods -o json | jq '.items[].spec.containers[].env[]?.valueFrom.secretKeyRef.name' | grep -v null | sort | uniq
# Ereignisse nach Zeitstempel sortiert auflisten
kubectl get events --sort-by=.metadata.creationTimestamp
Ressourcen aktualisieren
Ab Version 1.11 ist das rolling-update veraltet (Lesen Sie CHANGELOG-1.11.md für weitere Informationen), verwenden Sie stattdessen rollout.
kubectl set image deployment/frontend www=image:v2 # Fortlaufende Aktualisierung der "www" Container der "Frontend"-Bereitstellung, Aktualisierung des Images
kubectl rollout undo deployment/frontend # Rollback zur vorherigen Bereitstellung
kubectl rollout status -w deployment/frontend # Beobachten Sie den fortlaufenden Aktualisierungsstatus der "Frontend"-Bereitstellung bis zum Abschluss.
# veraltet ab Version 1.11
kubectl rolling-update frontend-v1 -f frontend-v2.json # (veraltet) Fortlaufendes Update der Pods von Frontend-v1
kubectl rolling-update frontend-v1 frontend-v2 --image=image:v2 # (veraltet) Ändern Sie den Namen der Ressource und aktualisieren Sie das Image
kubectl rolling-update frontend --image=image:v2 # (veraltet) Aktualisieren Sie das Pod-Image des Frontends
kubectl rolling-update frontend-v1 frontend-v2 --rollback # (veraltet) Bricht das laufende Rollout ab
cat pod.json | kubectl replace -f - # Ersetzen Sie einen Pod basierend auf der in std übergebenen JSON
# Ersetzen, löschen und Ressource neu erstellen. Dies führt zu einer temprären Unerreichbarkeit des Dienstes.
kubectl replace --force -f ./pod.json
# Erstellen Sie einen Dienst für eien replizierten nginx Webserver, der an Port 80 und in den Containern an Port 8000 lauscht
kubectl expose rc nginx --port=80 --target-port=8000
# Aktualisieren Sie die Image-Version (Tag) eines Einzelcontainer-Pods auf Version 4
kubectl get pod mypod -o yaml | sed 's/\(image: myimage\):.*$/\1:v4/' | kubectl replace -f -
kubectl label pods my-pod new-label=awesome # Label hinzufügen
kubectl annotate pods my-pod icon-url=http://goo.gl/XXBTWq # Eine Anmerkung hinzufügen
kubectl autoscale deployment foo --min=2 --max=10 # Automatische Skalierung einer Bereitstellung "Foo"
Ressourcen patchen
kubectl patch node k8s-node-1 -p '{"spec":{"unschedulable":true}}' # Aktualisieren Sie einen Node teilweise
# Aktualisieren Sie das Image eines Containers; spec.containers[*].name ist erforderlich, da es sich um einen Merge-Schlüssel handelt
kubectl patch pod valid-pod -p '{"spec":{"containers":[{"name":"kubernetes-serve-hostname","image":"new image"}]}}'
# Aktualisieren Sie das Image eines Containers mithilfe eines Json-Patches mit Positionsarrays
kubectl patch pod valid-pod --type='json' -p='[{"op": "replace", "path": "/spec/containers/0/image", "value":"new image"}]'
# Deaktivieren Sie eine Bereitstellung von livenessProbe durch verwenden eines Json-Patches mit Positionsarrays
kubectl patch deployment valid-deployment --type json -p='[{"op": "remove", "path": "/spec/template/spec/containers/0/livenessProbe"}]'
# Fügen Sie einem Positionsarray ein neues Element hinzu
kubectl patch sa default --type='json' -p='[{"op": "add", "path": "/secrets/1", "value": {"name": "whatever" } }]'
Ressourcen bearbeiten
Bearbeiten Sie eine beliebige API-Ressource in einem Editor.
kubectl edit svc/docker-registry # Bearbeiten Sie den Dienst docker-registry
KUBE_EDITOR="nano" kubectl edit svc/docker-registry # Verwenden Sie einen alternativen Texteditor
Ressourcen skalieren
kubectl scale --replicas=3 rs/foo # Skaliert ein Replikat mit dem Namen 'foo' auf 3
kubectl scale --replicas=3 -f foo.yaml # Skaliert eine in "foo.yaml" angegebene Ressource auf 3
kubectl scale --current-replicas=2 --replicas=3 deployment/mysql # Wenn die aktuelle Konfiguration der Replikation von mysql 2 ist, skaliert mysql auf 3
kubectl scale --replicas=5 rc/foo rc/bar rc/baz # Skaliert mehrere Replikationscontroller
Ressourcen löschen
kubectl delete -f ./pod.json # Löscht einen Pod mit dem in pod.json angegebenen Typ und Namen
kubectl delete pod,service baz foo # Löscht Pods und Services mit den gleichen Namen "baz" und "foo"
kubectl delete pods,services -l name=myLabel # Löscht Pods und Services mit dem Label name=myLabel
kubectl -n my-ns delete po,svc --all # Löscht alle Pods und Dienste, im Namespace my-ns
Interaktion mit laufenden Pods
kubectl logs my-pod # Pod-Logdatei ausgeben (stdout)
kubectl logs my-pod --previous # Pod-Logdatei für eine vorherige Instantiierung eines Containers ausgeben (stdout)
kubectl logs my-pod -c my-container # Pod Container-Logdatei ausgeben (stdout, multi-container case)
kubectl logs my-pod -c my-container --previous # Pod Container-Logdatei für eine vorherige Instantiierung eines Containers ausgeben (stdout, multi-container case)
kubectl logs -f my-pod # Pod-Logdatei streamen (stdout)
kubectl logs -f my-pod -c my-container # Pod Container-Logdatei streamen (stdout, multi-container case)
kubectl run -i --tty busybox --image=busybox -- sh # Pod als interaktive Shell ausführen
kubectl attach my-pod -i # An laufenden Container anhängen
kubectl port-forward my-pod 5000:6000 # Lauscht auf Port 5000 auf dem lokalen Computer und leitet den Port 6000 auf my-pod weiter
kubectl exec my-pod -- ls / # Befehl in vorhandenem Pod ausführen (1 Container)
kubectl exec my-pod -c my-container -- ls / # Befehl in vorhandenem Pod ausführen (Mehrere Container)
kubectl top pod POD_NAME --containers # Zeigt Metriken für einen bestimmten Pod und seine Container an
Mit Nodes und Clustern interagieren
kubectl cordon my-node # Markiert "my-node" als unplanbar
kubectl drain my-node # Entleert "my-node" zur Vorbereitung der Wartung
kubectl uncordon my-node # Markiert "my-node" als planbar
kubectl top node my-node # Metriken für einen bestimmten Node anzeigen
kubectl cluster-info # Adressen des Masters und der Services anzeigen
kubectl cluster-info dump # Ausgabe des aktuellen Clusterstatus in stdout
kubectl cluster-info dump --output-directory=/pfad/zum/cluster-status # Aktuellen Cluster-Status in /pfad/zum/cluster-status ausgeben
# Wenn bereits ein Taint mit diesem Key und Effekt vorhanden ist, wird sein Wert wie angegeben ersetzt.
kubectl taint nodes foo dedicated=special-user:NoSchedule
Ressourcentypen
Liste aller unterstützten Ressourcentypen mit ihren Kurzbezeichnungen, der API-Gruppe, unabhängig davon ob sie im Namespace liegen, und der Art:
kubectl api-resources
Andere Operationen zum Erkunden von API-Ressourcen:
kubectl api-resources --namespaced=true # Alle Ressourcen im Namespace
kubectl api-resources --namespaced=false # Alle nicht im Namespace befindlichen Ressourcen
kubectl api-resources -o name # Alle Ressourcen mit einfacher Ausgabe (nur der Ressourcenname)
kubectl api-resources -o wide # Alle Ressourcen mit erweiterter Ausgabe (aka "Wide")
kubectl api-resources --verbs=list,get # Alle Ressourcen, die "list" und "get" Verben unterstützen anfordern
kubectl api-resources --api-group=extensions # Alle Ressourcen in der API-Gruppe "extensions"
Ausgabe formatieren
Um Details in einem bestimmten Format an Ihr Terminalfenster auszugeben, können Sie entweder das -o oder --output Flag zu einem unterstützten kubectl Befehl anhängens.
| Ausgabeformat | Beschreibung |
|---|---|
-o=custom-columns=<spec> |
Ausgabe einer Tabelle mit einer durch Kommas getrennten Liste benutzerdefinierter Spalten |
-o=custom-columns-file=<dateiname> |
Drucken Sie eine Tabelle mit der benutzerdefinierten Spaltenvorlage in der <dateiname> Datei |
-o=json |
Ausgabe eines JSON-formatierten API-Objekts |
-o=jsonpath=<template> |
Ausgabe der in einem jsonpath-Ausdruck definierten Felder |
-o=jsonpath-file=<dateiname> |
Ausgabe der in einem jsonpath-Ausdruck definierten Felder in der <dateiname> Datei |
-o=name |
Ausgabe von nur dem Ressourcennamen und nichts anderes |
-o=wide |
Ausgabe im Klartextformat mit zusätzlichen Informationen. Bei Pods ist der Node-Name enthalten |
-o=yaml |
Gibt ein YAML-formatiertes API-Objekt aus |
Kubectl Ausgabe Ausführlichkeit und Debugging
Die Ausführlichkeit von Kubectl wird mit den Flags -v oder --v gesteuert, gefolgt von einer Ganzzahl, die die Protokollebene darstellt. Allgemeine Protokollierungskonventionen für Kubernetes und die zugehörigen Protokollebenen werden hier beschrieben.
| Ausführlichkeit | Beschreibung |
|---|---|
--v=0 |
Allgemein nützlich, damit dies für den Bediener IMMER sichtbar ist. |
--v=1 |
Eine vernünftige Standardprotokollebene, wenn Sie keine Ausführlichkeit wünschen. |
--v=2 |
Nützliche Informationen zum stabilen Status des Dienstes und wichtige Protokollnachrichten, die möglicherweise zu erheblichen Änderungen im System führen. Dies ist die empfohlene Standardprotokollebene für die meisten Systeme. |
--v=3 |
Erweiterte Informationen zu Änderungen. |
--v=4 |
Debug-Level-Ausführlichkeit. |
--v=6 |
Angeforderte Ressourcen anzeigen |
--v=7 |
HTTP-Anforderungsheader anzeigen |
--v=8 |
HTTP-Anforderungsinhalt anzeigen |
--v=9 |
HTTP-Anforderungsinhalt anzeigen, ohne den Inhalt zu kürzen. |
Nächste Schritte
-
Lernen Sie mehr im Überblick auf kubectl.
-
Erkunden Sie kubectl Optionen.
-
Und ebenfalls die kubectl Nutzungskonventionen um zu verstehen, wie man es in wiederverwendbaren Skripten verwendet.
-
Entdecken Sie mehr Community kubectl Spickzettel.
6.10 - Tools
Kubernetes enthält mehrere integrierte Tools, die Ihnen bei der Arbeit mit dem Kubernetes System helfen.
Kubectl
kubectl ist ein Kommandozeilenprogramm für Kubernetes. Es steuert den Kubernetes Clustermanager.
Kubeadm
kubeadm ist ein Kommandozeilenprogramm zur einfachen Bereitstellung eines sicheren Kubernetes-Clusters auf physischen oder Cloud-Servern oder virtuellen Maschinen (derzeit in alpha).
Kubefed
kubefed ist ein Kommandozeilenprogramm um Ihnen bei der Verwaltung Ihrer Verbundcluster zu helfen.
Minikube
minikube ist ein Tool, das es Ihnen einfach macht, einen Kubernetes-Cluster mit einem einzigen Knoten lokal auf Ihrer Workstation für Entwicklungs- und Testzwecke auszuführen.
Dashboard
Dashboard, die webbasierte Benutzeroberfläche von Kubernetes ermöglicht es Ihnen containerisierte Anwendungen in einem Kubernetes-Cluster bereitzustellen Fehler zu beheben und den Cluster und seine Ressourcen selbst zu verwalten.
Helm
Kubernetes Helm ist ein Tool zur Verwaltung von Paketen mit vorkonfigurierten Kubernetes-Ressourcen, auch bekannt als Kubernetes charts.
Verwenden Sie Helm um:
- Beliebte Software verpackt als Kubernetes charts zu finden und zu verwenden
- Ihre eigenen Applikationen als Kubernetes charts zu teilen
- Reproduzierbare Builds Ihrer Kubernetes Anwendungen zu erstellen
- Intelligenten Verwaltung von Ihren Kubernetes manifest files
- Verwalten von Versionen von Helm Paketen
Kompose
Kompose ist ein Tool, das Docker Compose Benutzern hilft, nach Kubernetes zu wechseln.
Verwenden Sie Kompose um:
- Ein Docker Compose Datei in Kubernetes Objekte zu übersetzen
- Von Ihrer lokalen Docker Entwicklung auf eine Kubernetes verwaltete Entwicklung zu wechseln
- v1 oder v2 Docker Compose
yamlDateien oder Distributed Application Bundles zu konvertieren
7 - Zur Kubernetes-Dokumentation beitragen
Wenn Sie an der Dokumentation oder der Website von Kubernetes mitwirken möchten, freuen wir uns über Ihre Hilfe! Jeder kann seinen Beitrag leisten, unabhängig davon ob Sie neu im Projekt sind oder schon lange dabei sind, und ob Sie sich als Entwickler, Endbenutzer oder einfach jemanden, der es einfach nicht aushält, Tippfehler zu sehen sehen.
Weitere Möglichkeiten, sich in der Kubernetes-Community zu engagieren oder mehr über uns zu erfahren, finden Sie auf der Kubernetes-Community-Seite. Informationen zum Handbuch zur Dokumentation von Kubernetes finden Sie im Gestaltungshandbuch.
Arten von Mitwirkenden
- Ein Member der Kubernetes Organisation, hat die CLA unterzeichnet und etwas Zeit und Energie zum Projekt beigetragen. Siehe Community-Mitgliedschaft für spezifische Kriterien bezüglich der Mitgliedschaft.
- Ein SIG Docs Reviewer ist ein Mitglied der Kubernetes-Organisation, das Interesse an der Überprüfung von
Dokumentationsanfragen geäußert hat und von einem SIG Docs Approver zu der entsprechenden Github-Gruppe
und den
OWNERS-Dateien im Github-Repository hinzugefügt wurde. - Ein SIG Docs approver ist ein Mitglied mit gutem Ansehen, das sich kontinuierlich für das Projekt engagiert hat. Ein Approver kann Pull-Anfragen zusammenführen und Inhalte im Namen der Kubernetes-Organisation veröffentlichen. Approver können SIG Docs auch in der größeren Kubernetes-Community vertreten. Einige der Aufgaben eines SIG Docs Approvers, wie z.B. die Koordination einer Freigabe, erfordern einen erheblichen Zeitaufwand.
Möglichkeiten, einen Beitrag zu leisten
Diese Liste ist in Funktionen unterteilt, die jeder tun kann, die von Mitgliedern der Kubernetes-Organisation durchgeführt werden können, und Dinge, die ein höheres Maß an Zugriff und eine bessere Kenntnis der SIG Docs-Prozesse erfordern. Wenn Sie im Laufe der Zeit einen konstanten Beitrag leisten, können Sie einige der bereits getroffenen Tools und organisatorischen Entscheidungen nachvollziehen.
Dies ist keine vollständige Liste von Möglichkeiten, wie Sie zur Kubernetes-Dokumentation beitragen können, aber sie sollte Ihnen den Einstieg erleichtern.
- Jeder
- Umsetzbare issues eröffnen
- Member
- Vorhandene Dokumente verbessern
- Ideen zur Verbesserung in Slack oder der SIG docs Mailingliste einbringen
- Den Zugriff auf Dokumente verbessern
- Unverbindliches Feedback zu PRs verfassen
- Enen Blogbeitrag oder eine Fallstudie schreiben
- Reviewer
- Neue Funktionen dokumentieren
- Auswerten und Kategorisieren von Problemen
- PRs überprüfen
- Diagramme, Grafiken und einbettbare Screencasts / Videos erstellen
- Lokalisierung
- Als Vertreter von docs zu anderen Repos beitragen
- An Benutzer gerichtete Zeichenfolgen im Code bearbeiten
- Code-Kommentare verbessern, Godoc
- Approver
- Veröffentlichen Sie den Inhalt von Members, indem Sie PRs genehmigen und zusammenführen
- Nehmen Sie als Docs-Vertreter an einem Kubernetes-Release-Team teil
- Verbesserungsvorschläge für den Style Guide
- Verbesserungsvorschläge für Dokumentprüfungen vorschlagen
- Vorschläge für Verbesserungen der Kubernetes-Website oder anderer Tools
7.1 - Lokalisierung der Kubernetes Dokumentation
Diese Seite zeigt dir wie die Dokumentation für verschiedene Sprachen lokalisiert wird.
Erste Schritte
Da Mitwirkende nicht ihren eigenen Pull Request freigeben können, brauchst du mindestens zwei Mitwirkende um mit der Lokalisierung anfangen zu können.
Alle Lokalisierungsteams müssen sich mit ihren eigenen Ressourcen selbst tragen. Die Kubernetes-Website ist gerne bereit, deine Arbeit zu beherbergen, aber es liegt an dir, sie zu übersetzen.
Ermittlung deines Zwei-Buchstaben-Sprachcodes
Rufe den ISO 639-1 Standard auf und finde deinen Zwei-Buchstaben-Ländercode zur Lokalisierung. Zum Beispiel ist der Zwei-Buchstaben-Code für Korea ko.
Duplizieren und Klonen des Repositories
Als erstes erstellst du dir deine eigenes Duplikat vom [kubernetes/website] Repository.
Dann klonst du das Duplikat und wechselst in das neu erstellte Verzeichnis:
git clone https://github.com/<username>/website
cd website
Eröffnen eines Pull Requests
Als nächstes eröffnest du einen Pull Request (PR) um eine Lokalisierung zum kubernetes/website Repository hinzuzufügen.
Der PR muss die minimalen Inhaltsanforderungen erfüllen, bevor dieser genehmigt werden kann.
Wie der PR für eine neue Lokalisierung aussieht, kannst du dir an dem PR für die Französische Dokumentation ansehen.
Tritt der Kubernetes GitHub Organisation bei
Sobald du eine Lokalisierungs-PR eröffnet hast, kannst du Mitglied der Kubernetes GitHub Organisation werden. Jede Person im Team muss einen eigenen Antrag auf Mitgliedschaft in der Organisation im kubernetes/org-Repository erstellen.
Lokalisierungs-Team in GitHub hinzufügen
Im nächsten Schritt musst du dein Kubernetes Lokalisierungs-Team in die sig-docs/teams.yaml eintragen.
Der PR des Spanischen Lokalisierungs-Teams kann dir hierbei eine Hilfestellung sein.
Mitglieder der @kubernetes/sig-docs-**-owners können nur PRs freigeben die innerhalb deines Lokalisierungs-Ordners Änderungen vorgenommen haben: /content/**/.
Für jede Lokalisierung automatisiert das Team @kubernetes/sig-docs-**-reviews die Review-Zuweisung für neue PRs.
Mitglieder von @kubernetes/website-maintainers können neue Entwicklungszweige schaffen, um die Übersetzungsarbeiten zu koordinieren.
Mitglieder von @kubernetes/website-milestone-maintainers können den Befehl /milestone Prow Kommando verwenden, um Themen oder PRs einen Meilenstein zuzuweisen.
Workflow konfigurieren
Als nächstes fügst du ein GitHub-Label für deine Lokalisierung im kubernetes/test-infra-Repository hinzu. Mit einem Label kannst du Aufgaben filtern und Anfragen für deine spezifische Sprache abrufen.
Schau dir den PR zum Hinzufügen der Labels für die [Italienischen Sprachen-Labels](https://github.com/kubernetes/test-infra/pull/11316 an.
Finde eine Gemeinschaft
Lasse die Kubernetes SIG Docs wissen, dass du an der Erstellung einer Lokalisierung interessiert bist! Trete dem SIG Docs Slack-Kanal bei. Andere Lokalisierungsteams helfen dir gerne beim Einstieg und beantworten deine Fragen.
Du kannst auch einen Slack-Kanal für deine Lokalisierung im kubernetes/community-Repository erstellen. Ein Beispiel für das Hinzufügen eines Slack-Kanals findest du im PR für Kanäle für Indonesisch und Portugiesisch hinzufügen.
Mindestanforderungen
Ändere die Website-Konfiguration
Die Kubernetes-Website verwendet Hugo als Web-Framework. Die Hugo-Konfiguration der Website befindet sich in der Datei hugo.toml. Um eine neue Lokalisierung zu unterstützen, musst du die Datei hugo.toml modifizieren.
Dazu fügst du einen neuen Block für die neue Sprache unter den bereits existierenden [languages] Block in das hugo.toml ein, wie folgendes Beispiel zeigt:
[languages.de]
title = "Kubernetes"
description = "Produktionsreife Container-Verwaltung"
languageName = "Deutsch"
contentDir = "content/de"
weight = 3
Wenn du deinem Block einen Parameter weight zuweist, suche den Sprachblock mit dem höchsten Gewicht und addiere 1 zu diesem Wert.
Weitere Informationen zu Hugos multilingualem Support findest du unter "Multilingual Mode" auf in der Hugo Dokumentation.
Neuen Lokalisierungsordner erstellen
Füge eine sprachspezifisches Unterverzeichnis zum Ordner content im Repository hinzu. Der Zwei-Buchstaben-Code für Deutsch ist zum Beispiel de:
mkdir content/de
Lokalisiere den Verhaltenscodex
Öffne einen PR gegen das cncf/foundation Repository, um den Verhaltenskodex in deiner Sprache hinzuzufügen.
Lokalisierungs README Datei hinzufügen
Um andere Lokalisierungsmitwirkende anzuleiten, füge eine neue README-**.md auf der obersten Ebene von kubernetes/website hinzu, wobei ** der aus zwei Buchstaben bestehende Sprachcode ist. Eine deutsche README-Datei wäre zum Beispiel README-de.md.
Gebe den Lokalisierungsmitwirkende in der lokalisierten README-**.md-Datei Anleitung zum Mitwirken. Füge dieselben Informationen ein, die auch in README.md enthalten sind, sowie:
- Eine Anlaufstelle für das Lokalisierungsprojekt
- Alle für die Lokalisierung spezifischen Informationen
Nachdem du das lokalisierte README erstellt hast, füge der Datei einen Link aus der englischen Hauptdatei README.md hinzu und gebe die Kontaktinformationen auf Englisch an. Du kannst eine GitHub-ID, eine E-Mail-Adresse, Slack-Kanal oder eine andere Kontaktmethode angeben. Du musst auch einen Link zu deinem lokalisierten Verhaltenskodex der Gemeinschaft angeben.
Richte eine OWNERS Datei ein
Um die Rollen der einzelnen an der Lokalisierung beteiligten Benutzer festzulegen, erstelle eine OWNERS-Datei innerhalb des sprachspezifischen Unterverzeichnisses mit:
- reviewers: Eine Liste von kubernetes-Teams mit Gutachter-Rollen, in diesem Fall das
sig-docs-**-reviewsTeam, das in Lokalisierungsteam in GitHub hinzufügen erstellt wurde. - approvers: Eine Liste der Kubernetes-Teams mit der Rolle des Genehmigers, in diesem Fall das
sig-docs-**-ownersTeam, das in Lokalisierungsteam in GitHub hinzufügen erstellt wurde. - labels: Eine Liste von GitHub-Labels, die automatisch auf einen PR angewendet werden sollen, in diesem Fall das Sprachlabel, das unter Workflow konfigurieren erstellt wurde.
Weitere Informationen über die Datei OWNERS findest du unter go.k8s.io/owners.
Die Datei Spanish OWNERS file, mit dem Sprachcode es, sieht wie folgt aus:
# See the OWNERS docs at https://go.k8s.io/owners
# This is the localization project for Spanish.
# Teams and members are visible at https://github.com/orgs/kubernetes/teams.
reviewers:
- sig-docs-es-reviews
approvers:
- sig-docs-es-owners
labels:
- language/es
Nachdem du die sprachspezifische Datei OWNERS hinzugefügt hast, aktualisiere die root Datei OWNERS_ALIASES mit den neuen Kubernetes-Teams für die Lokalisierung, sig-docs-**-owners und sig-docs-**-reviews.
Füge für jedes Team die Liste der unter Ihr Lokalisierungsteam in GitHub hinzufügen angeforderten GitHub-Benutzer in alphabetischer Reihenfolge hinzu.
--- a/OWNERS_ALIASES
+++ b/OWNERS_ALIASES
@@ -48,6 +48,14 @@ aliases:
- stewart-yu
- xiangpengzhao
- zhangxiaoyu-zidif
+ sig-docs-es-owners: # Admins for Spanish content
+ - alexbrand
+ - raelga
+ sig-docs-es-reviews: # PR reviews for Spanish content
+ - alexbrand
+ - electrocucaracha
+ - glo-pena
+ - raelga
sig-docs-fr-owners: # Admins for French content
- perriea
- remyleone
Inhalte übersetzen
Die Lokalisierung aller Dokumentationen des Kubernetes ist eine enorme Aufgabe. Es ist in Ordnung, klein anzufangen und mit der Zeit zu erweitern.
Alle Lokalisierungen müssen folgende Inhalte enthalten:
| Beschreibung | URLs |
|---|---|
| Startseite | Alle Überschriften und Untertitel URLs |
| Einrichtung | Alle Überschriften und Untertitel URLs |
| Tutorials | Kubernetes Grundlagen, Hello Minikube |
| Site strings | Alle Website-Zeichenfolgen in einer neuen lokalisierten TOML-Datei |
Übersetzte Dokumente müssen sich in ihrem eigenen Unterverzeichnis content/**/ befinden, aber ansonsten dem gleichen URL-Pfad wie die englische Quelle folgen. Um z.B. das Tutorial Kubernetes Grundlagen für die Übersetzung ins Deutsche vorzubereiten, erstelle einen Unterordner unter dem Ordner content/de/ und kopiere die englische Quelle:
mkdir -p content/de/docs/tutorials
cp content/en/docs/tutorials/kubernetes-basics.md content/de/docs/tutorials/kubernetes-basics.md
Übersetzungswerkzeuge können den Übersetzungsprozess beschleunigen. Einige Redakteure bieten beispielsweise Plugins zur schnellen Übersetzung von Text an.
Um die Genauigkeit in Grammatik und Bedeutung zu gewährleisten, sollten die Mitglieder deines Lokalisierungsteams alle maschinell erstellten Übersetzungen vor der Veröffentlichung sorgfältig überprüfen.
Quelldaten
Lokalisierungen müssen auf den englischen Dateien der neuesten Version basieren, v1.28.
Um die Quelldatei für das neueste Release führe folgende Schritte durch:
- Navigiere zum Repository der Website Kubernetes unter https://github.com/kubernetes/website.
- Wähle den
release-1.X-Zweig für die aktuellste Version.
Die neueste Version ist v1.28, so dass der neueste Versionszweig release-1.28 ist.
Seitenverlinkung in der Internationalisierung
Lokalisierungen müssen den Inhalt von i18n/de.toml in einer neuen sprachspezifischen Datei enthalten. Als Beispiel: i18n/de.toml.
Füge eine neue Lokalisierungsdatei zu i18n/ hinzu. Zum Beispiel mit Deutsch (de):
cp i18n/en.toml i18n/de.toml
Übersetze dann den Wert jeder Zeichenfolge:
[docs_label_i_am]
other = "ICH BIN..."
Durch die Lokalisierung von Website-Zeichenfolgen kannst du Website-weiten Text und Funktionen anpassen: z. B. den gesetzlichen Copyright-Text in der Fußzeile auf jeder Seite.
Sprachspezifischer Styleguide
Einige Sprachteams haben ihren eigenen sprachspezifischen Styleguide und ihr eigenes Glossar. Siehe zum Beispiel den Leitfaden zur koreanischen Lokalisierung.
Informale Schreibweise
Für die deutsche Übersetzungen verwenden wir eine informelle Schreibweise und der Ansprache per Du. Allerdings werden keine Jargon, Slang, Wortspiele, Redewendungen oder kulturspezifische Bezüge eingebracht.
Datums und Maßeinheiten
Wenn notwendig sollten Datumsangaben in das in Deutschland übliche dd.mm.yyyy überführt werden. Alternativ können diese auch in den Textfluss eingebunden werden: "... am 24. April ....".
Abkürzungen
Abkürzungen sollten nach Möglichkeit nicht verwendet werden und entweder ausgeschrieben oder anderweitig umgangen werden.
Zusammengesetzte Wörter
Durch die Übersetzung werden oft Nomen aneinandergereiht, diese Wortketten müssen durch Bindestriche verbunden werden. Dies ist auch möglich wenn ein Teil ins Deutsche übersetzt wird ein weiterer jedoch im Englischen bestehen bleibt. Als Richtlinie gilt hier der Duden.
Anglizismen
Die Verwendung von Anglizismen ist dann wünschenswert, wenn die Verwendung eines deutschen Wortes, vor allem für technische Begriffe, nicht eindeutig ist oder zu Unklarheiten führt.
Branching Strategie
Da Lokalisierungsprojekte in hohem Maße gemeinschaftliche Bemühungen sind, ermutigen wir Teams, in gemeinsamen Entwicklungszweigen zu arbeiten.
In einem Entwicklungszweig zusammenzuarbeiten:
-
Ein Teammitglied von @kubernetes/website-maintainers eröffnet einen Entwicklungszweig aus einem Quellzweig auf https://github.com/kubernetes/website.
Deine Genehmiger sind dem
@kubernetes/website-maintainers-Team beigetreten, als du dein Lokalisierungsteam zum Repositorykubernetes/orghinzugefügt hast.Wir empfehlen das folgende Zweigbenennungsschema:
dev-<Quellversion>-<Sprachcode>.<Team-Meilenstein>Beispielsweise öffnet ein Genehmigender in einem deutschen Lokalisierungsteam den Entwicklungszweig
dev-1.12-de.1direkt gegen das kubernetes/website-Repository, basierend auf dem Quellzweig für Kubernetes v1.12. -
Einzelne Mitwirkende öffnen Feature-Zweige, die auf dem Entwicklungszweig basieren.
Zum Beispiel öffnet ein deutscher Mitwirkende eine Pull-Anfrage mit Änderungen an
kubernetes:dev-1.12-de.1vonBenutzername:lokaler-Zweig-Name. -
Genehmiger Überprüfen und führen die Feature-Zweigen in den Entwicklungszweig zusammen.
-
In regelmäßigen Abständen führt ein Genehmiger den Entwicklungszweig mit seinem Ursprungszweig zusammen, indem er eine neue Pull-Anfrage eröffnet und genehmigt. Achtet darauf, die Commits zusammenzuführen (squash), bevor die Pull-Anfrage genehmigt wird.
Wiederhole die Schritte 1-4 nach Bedarf, bis die Lokalisierung abgeschlossen ist. Zum Beispiel würden nachfolgende deutsche Entwicklungszweige sein: dev-1.12-de.2, dev-1.12-de.3, usw.
Die Teams müssen den lokalisierten Inhalt in demselben Versionszweig zusammenführen, aus dem der Inhalt stammt. Beispielsweise muss ein Entwicklungszweig, der von release-1.28 ausgeht, auf {{release-1.28} basieren.
Ein Genehmiger muss einen Entwicklungszweig aufrechterhalten, indem er seinen Quellzweig auf dem aktuellen Stand hält und Merge-Konflikte auflöst. Je länger ein Entwicklungszweig geöffnet bleibt, desto mehr Wartung erfordert er in der Regel. Ziehe in Betracht, regelmäßig Entwicklungszweige zusammenzuführen und neue zu eröffnen, anstatt einen extrem lang laufenden Entwicklungszweig zu unterhalten.
Zu Beginn jedes Team-Meilensteins ist es hilfreich, ein Problem Vergleich der Upstream-Änderungen zwischen dem vorherigen Entwicklungszweig und dem aktuellen Entwicklungszweig zu öffnen.
Während nur Genehmiger einen neuen Entwicklungszweig eröffnen und Pull-Anfragen zusammenführen können, kann jeder eine Pull-Anfrage für einen neuen Entwicklungszweig eröffnen. Es sind keine besonderen Genehmigungen erforderlich.
Weitere Informationen über das Arbeiten von Forks oder direkt vom Repository aus findest du unter "fork and clone the repo".
Am Upstream Mitwirken
SIG Docs begrüßt Upstream Beiträge, also auf das englische Original, und Korrekturen an der englischen Quelle.
Unterstütze bereits bestehende Lokalisierungen
Du kannst auch dazu beitragen, Inhalte zu einer bestehenden Lokalisierung hinzuzufügen oder zu verbessern. Trete dem Slack-Kanal für die Lokalisierung bei und beginne mit der Eröffnung von PRs, um zu helfen. Bitte beschränke deine Pull-Anfragen auf eine einzige Lokalisierung, da Pull-Anfragen, die Inhalte in mehreren Lokalisierungen ändern, schwer zu überprüfen sein könnten.
Nächste Schritte
Sobald eine Lokalisierung die Anforderungen an den Arbeitsablauf und die Mindestausgabe erfüllt, wird SIG docs:
- Die Sprachauswahl auf der Website aktivieren
- Die Verfügbarkeit der Lokalisierung über die Kanäle der Cloud Native Computing Foundation (CNCF), einschließlich des Kubernetes Blogs veröffentlichen.
7.2 - Bei SIG Docs mitmachen
Die SIG Docs ist eine der Special Interest Groups (Fachspezifischen Interessengruppen) innerhalb des Kubernetes-Projekts, die sich auf das Schreiben, Aktualisieren und Pflegen der Dokumentation für Kubernetes als Ganzes konzentriert. Weitere Informationen über die SIG findest du unter SIG Docs im GitHub Repository der Community.
SIG Docs begrüßt Inhalte und Bewertungen von allen Mitwirkenden. Jeder kann einen Pull Request (PR) eröffnen, und jeder ist willkommen, Fragen zum Inhalt zu stellen oder Kommentare zu laufenden Pull Requests abzugeben.
Du kannst dich ausserdem als Member, Reviewer, oder Approver beteiligen. Diese Rollen erfordern einen erweiterten Zugriff und bringen bestimmte Verantwortlichkeiten zur Genehmigung und Bestätigung von Änderungen mit sich. Unter community-membership findest du weitere Informationen darüber, wie die Mitgliedschaft in der Kubernetes-Community funktioniert.
Der Rest dieses Dokuments umreißt einige spezielle Vorgehensweisen dieser Rollen innerhalb von SIG Docs, die für die Pflege eines der öffentlichsten Aushängeschilder von Kubernetes verantwortlich ist - die Kubernetes-Website und die Dokumentation.
SIG Docs Vorstand
Jede SIG, auch die SIG Docs, wählt ein oder mehrere SIG-Mitglieder, die als Vorstand fungieren. Sie sind die Kontaktstellen zwischen der SIG Docs und anderen Teilen der der Kubernetes-Organisation. Sie benötigen umfassende Kenntnisse über die Struktur des Kubernetes-Projekts als Ganzes und wie SIG Docs darin arbeitet. Hier findest alle weiteren Informationen zu den aktuellen Vorsitzenden und der Leitung.
SIG Docs-Teams und Automatisierung
Die Automatisierung in SIG Docs stützt sich auf zwei verschiedene Mechanismen: GitHub-Teams und OWNERS-Dateien.
GitHub Teams
Es gibt zwei Kategorien von SIG Docs Teams auf GitHub:
@sig-docs-{language}-ownerssind Genehmiger und Verantwortliche@sig-docs-{language}-reviewssind Reviewer
Jede Gruppe kann in GitHub-Kommentaren mit ihrem @name referenziert werden, um mit allen Mitgliedern dieser Gruppe zu kommunizieren.
Manchmal überschneiden sich Prow- und GitHub-Teams, ohne eine genaue Übereinstimmung. Für die Zuordnung von Issues, Pull-Requests und zur Unterstützung von PR-Genehmigungen verwendet die
Automatisierung die Informationen aus den OWNERS-Dateien.
OWNERS Dateien und Front-Matter
Das Kubernetes-Projekt verwendet ein Automatisierungstool namens prow für die Automatisierung im Zusammenhang mit GitHub-Issues und Pull-Requests. Das Kubernetes-Website-Repository verwendet zwei prow-Plugins:
- blunderbuss
- approve
Diese beiden Plugins nutzen die
OWNERS und
OWNERS_ALIASES
Dateien auf der obersten Ebene des GitHub-Repositorys kubernetes/website, um zu steuern
wie prow innerhalb des Repositorys arbeitet.
Eine OWNERS-Datei enthält eine Liste von Personen, die SIG Docs-Reviewer und Genehmiger sind. OWNERS-Dateien können auch in Unterverzeichnissen existieren und bestimmen, wer Dateien in diesem Unterverzeichnis und seinen Unterverzeichnissen als Gutachter oder Genehmiger bestätigen darf. Weitere Informationen über OWNERS-Dateien im Allgemeinen findest du unter OWNERS.
Außerdem kann eine einzelne Markdown-Datei in ihrem Front-Matter (Vorspann) Reviewer und Genehmiger auflisten. Entweder durch Auflistung einzelner GitHub-Benutzernamen oder GitHub-Gruppen.
Die Kombination aus OWNERS-Dateien und Front-Matter in Markdown-Dateien bestimmt, welche Empfehlungen PR-Eigentümer von automatisierten Systemen erhalten, und wen sie um eine technische und redaktionelle Überprüfung ihres PRs bitten sollen.
So funktioniert das Zusammenführen
Wenn ein Pull Request mit der Branch (Ast) zusammengeführt wird, in dem der Inhalt bereitgestellt werden soll, wird dieser Inhalt auf http://kubernetes.io veröffentlicht. Um sicherzustellen, dass die Qualität der veröffentlichten Inhalte hoch ist, beschränken wir das Zusammenführen von Pull Requests auf SIG Docs Freigabeberechtigte. So funktioniert es:
- Wenn eine Pull-Anfrage sowohl das
lgtm- als auch dasapprove-Label hat, keinhold-Label hat, und alle Tests bestanden sind, wird der Pull Request automatisch zusammengeführt. - Jedes Kubernetes-Mitglied kann das
lgtm-Label hinzufügen, indem es einen/lgtm-Kommentar hinzufügt. - Mitglieder der Kubernetes-Organisation und SIG Docs-Genehmiger können kommentieren, um das automatische Zusammenführen eines Pull Requests zu verhindern (durch Hinzufügen eines
/hold-Kommentars kann ein vorheriger/lgtm-Kommentar zurückgehalten werden). - Nur SIG Docs-Genehmiger können einen Pull Request zusammenführen indem sie einen
/approveKommentar hinzufügen. Einige Genehmiger übernehmen auch weitere spezielle Rollen, wie zum Beispiel PR Wrangler oder SIG Docs Vorsitzende.
Nächste Schritte
Weitere Informationen über die Mitarbeit an der Kubernetes-Dokumentation findest du unter:
7.2.1 - Rollen und Verantwortlichkeiten
Jeder kann zu Kubernetes beitragen. Wenn deine Beiträge zu SIG Docs wachsen, kannst du dich für verschiedene Stufen der Mitgliedschaft in der Community bewerben. Diese Rollen ermöglichen es dir, mehr Verantwortung innerhalb der Gemeinschaft zu übernehmen. Jede Rolle erfordert mehr Zeit und Engagement. Die Rollen sind:
- Jeder: kann regelmäßig zur Kubernetes-Dokumentation beitragen
- Member: können Issues zuweisen und einstufen und Pull Requests unverbindlich prüfen
- Reviewer: können die Überprüfung von Dokumentations-Pull-Requests leiten und für die Qualität einer Änderung bürgen
- Approver: können die Überprüfung von Dokumentations- und Merge-Änderungen leiten
Jeder
Jeder mit einem GitHub-Konto kann zu Kubernetes beitragen. SIG Docs heißt alle neuen Mitwirkenden willkommen!
Jeder kann:
- Ein Problem in einem beliebigen Kubernetes
Repository, einschließlich
kubernetes/websitemelden - Unverbindliches Feedback zu einem Pull Request geben
- Zu einer Lokalisierung beitragen
- Verbesserungen auf Slack oder der SIG docs mailing list vorschlagen.
Nach dem Signieren des CLA kann jeder auch:
- eine Pull-Anfrage öffnen, um bestehende Inhalte zu verbessern, neue Inhalte hinzuzufügen oder einen Blogbeitrag oder eine Fallstudie zu schreiben
- Diagramme, Grafiken und einbettbare Screencasts und Videos erstellen
Weitere Informationen findest du unter neue Inhalte beisteuern.
Member
Ein Member (Mitglied) ist jemand, der bereits mehrere Pull Requests an
kubernetes/website eingereicht hat. Mitglieder sind ein Teil der
Kubernetes GitHub Organisation.
Member können:
-
Alles tun, was unter Jeder aufgeführt ist
-
Den Kommentar
/lgtmverwenden, um einem Pull Request das Label LGTM (looks good to me) hinzuzufügenHinweis: Die Verwendung von/lgtmlöst eine Automatisierung aus. Wenn du eine unverbindliche Zustimmung geben willst, funktioniert der Kommentar "LGTM" auch! -
Verwende den Kommentar
/hold, um das Zusammenführen eines Pull Requests zu blockieren. -
Benutze den Kommentar
/assign, um einem Pull Request einen Reviewer zuzuweisen. -
Unverbindliche Überprüfung von Pull Requests
-
Nutze die Automatisierung, um Issues zu sortieren und zu kategorisieren
-
Neue Funktionen dokumentieren
Mitglied werden
Du kannst ein Mitglied werden, nachdem du mindestens 5 substantielle Pull Requests eingereicht hast und die anderen Anforderungen erforderst:
-
Finde zwei Reviewer oder Approver, die deine Mitgliedschaft sponsern.
Bitte um Sponsoring im #sig-docs channel on Slack oder auf der SIG Docs Mailingliste.
Hinweis: Schicke keine direkte E-Mail oder Slack-Direktnachricht an ein einzelnes SIG Docs-Mitglied. Du musst das Sponsoring beantragen, bevor du deine Bewerbung einreichst. -
Eröffne ein GitHub-Issue im
kubernetes/orgRepository. Verwende dabei das Organization Membership Request issue template. -
Informiere deine Sponsoren über das GitHub-Issue. Du kannst entweder:
-
Ihren GitHub-Benutzernamen in deinem Issue (
@<GitHub-Benutzername>) erwähnen -
Ihnen den Issue-Link über Slack oder per E-Mail senden.
Die Sponsoren werden deine Anfrage mit einer "+1"-Stimme genehmigen. Sobald deine Sponsoren genehmigen, fügt dich ein Kubernetes-GitHub-Admin als Mitglied hinzu. Herzlichen Glückwunsch!
Wenn dein Antrag auf Mitgliedschaft nicht angenommen wird, erhältst du eine Rückmeldung. Nachdem du dich mit dem Feedback auseinandergesetzt hast, kannst du dich erneut bewerben.
-
-
Nimm die Einladung zur Kubernetes GitHub Organisation in deinem E-Mail-Konto an.
Hinweis: GitHub sendet die Einladung an die Standard-E-Mail-Adresse in deinem Konto.
Reviewer
Reviewer (Gutachteren) sind dafür verantwortlich, offene Pull Requests zu überprüfen. Anders als bei den Mitgliedern musst du auf das Feedback der Prüfer eingehen. Reviewer sind Mitglieder des @kubernetes/sig-docs-{language}-reviews GitHub-Teams.
Gutachteren können:
-
Pull Requests überprüfen und verbindliches Feedback geben
Hinweis: Um unverbindliches Feedback zu geben, stellst du deinen Kommentaren eine Formulierung wie "Optional:" voran. -
Bearbeite benutzerseitige Zeichenfolgen im Code
-
Verbessere Code-Kommentare
Zuweisung von Reviewern zu Pull Requests
Die Automatisierung weist allen Pull Requests Reviewer zu. Du kannst eine
Review von einer bestimmten Person anfordern, indem du einen Kommentar schreibst: /assign [@_github_handle].
Wenn der zugewiesene Prüfer den PR nicht kommentiert hat, kann ein anderer Prüfer einspringen. Du kannst bei Bedarf auch technische Prüfer zuweisen.
Verwendung von /lgtm
LGTM steht für "Looks good to me" und zeigt an, dass ein Pull Request
technisch korrekt und bereit zum Zusammenführen ist. Alle PRs brauchen einen /lgtm Kommentar von einem
Reviewer und einen /approve Kommentar von einem Approver, um zusammengeführt zu werden.
Ein /lgtm-Kommentar vom Reviewer ist verbindlich und löst eine Automatisierung aus, die das lgtm-Label hinzufügt.
Reviewer werden
Wenn du die Anforderungen erfüllst, kannst du ein SIG Docs-Reviewer werden. Reviewer in anderen SIGs müssen sich gesondert für den Reviewer-Status in SIG Docs bewerben.
So bewirbst du dich:
-
Eröffne einen Pull Request, in dem du deinen GitHub-Benutzernamen in einen Abschnitt der OWNERS_ALIASES Datei im
kubernetes/websiteRepository hinzufügt.Hinweis: Wenn du dir nicht sicher bist, wo du dich hinzufügen sollst, füge dich zusig-docs-de-reviewshinzu. -
Weise den PR einem oder mehreren SIG-Docs-Genehmigern zu (Benutzernamen, die unter
sig-docs-{language}-ownersaufgelisted sind). Wenn der PR genehmigt wurde, fügt dich ein SIG Docs-Lead dem entsprechenden GitHub-Team hinzu. Sobald du hinzugefügt bist, wird @k8s-ci-robot dich als Reviewer für neue Pull Requests vorschlagen und zuweisen.
Approver
Approver (Genehmiger) prüfen und genehmigen Pull Requests zum Zusammenführen. Genehmigende sind Mitglieder des @kubernetes/sig-docs-{language}-owners GitHub-Teams.
Genehmigende können Folgendes tun:
- Alles, was unter Jeder, Member und Reviewer aufgeführt ist
- Inhalte von Mitwirkenden veröffentlichen, indem sie Pull Requests mit dem Kommentar
/approvegenehmigen und zusammenführen - Verbesserungen für den Style Guide vorschlagen
- Verbesserungsvorschläge für Docs-Tests einbringen
- Verbesserungsvorschläge für die Kubernetes-Website oder andere Tools machen
Wenn der PR bereits einen /lgtm hat, oder wenn der Genehmigende ebenfalls mit
/lgtm kommentiert, wird der PR automatisch zusammengeführt. Ein SIG Docs-Genehmiger sollte nur ein
/lgtm für eine Änderung hinterlassen, die keine weitere technische Überprüfung erfordert.
Pull Requests genehmigen
Genehmiger und SIG Docs-Leads sind die Einzigen, die Pull Requests in das Website-Repository aufnehmen. Damit sind bestimmte Verantwortlichkeiten verbunden.
-
Genehmigende können den Befehl
/approveverwenden, der PRs in das Repository einfügt.Warnung: Ein unvorsichtiges Zusammenführen kann die Website lahmlegen, also sei dir sicher, dass du es auch so meinst, wenn du etwas zusammenführst. -
Vergewissere dich, dass die vorgeschlagenen Änderungen den Beitragsrichtlinien entsprechen.
Wenn du jemals eine Frage hast oder dir bei etwas nicht sicher bist, fordere einfach Hilfe an, um eine zusätzliche Überprüfung zu erhalten.
-
Vergewissere dich, dass die Netlify-Tests erfolgreich sind, bevor du einen PR mittels
/approvegenehmigst.
-
Besuche die Netlify-Seitenvorschau für den PR, um sicherzustellen, dass alles gut aussieht, bevor du es genehmigst.
-
Nimm am PR Wrangler Rotationsplan für wöchentliche Rotationen teil. SIG Docs erwartet von allen Genehmigern, dass sie an dieser Rotation teilnehmen. Siehe PR-Wranglers. für weitere Details.
Approver werden
Wenn du die Anforderungen erfüllst, kannst du ein SIG Docs Approver werden. Genehmigende in anderen SIGs müssen sich separat für den Approver-Status in SIG Docs bewerben.
So bewirbst du dich:
-
Eröffne eine Pull-Anfrage, in der du dich in einem Abschnitt der OWNERS_ALIASES Datei im
kubernetes/websiteRepository hinzuzufügen.Hinweis: Wenn du dir nicht sicher bist, wo du dich hinzufügen sollst, füge dich zusig-docs-de-ownershinzu. -
Weise den PR einem oder mehreren aktuellen SIG Docs Genehmigern zu.
Wenn der PR genehmigt wurde, fügt dich ein SIG Docs-Lead dem entsprechenden GitHub-Team hinzu. Sobald du hinzugefügt bist, wird @k8s-ci-robot dich als Reviewer für neue Pull Requests vorschlagen und zuweisen.
Nächste Schritte
- Erfahre mehr über PR-Wrangling, eine Rolle, die alle Genehmiger im Wechsel übernehmen.
7.2.2 - PR Wranglers
SIG Docs approvers übernehmen einwöchige Schichten um die Pull Requests des Repositories zu verwalten.
Dieser Abschnitt behandelt die Aufgaben eines PR-Wranglers. Weitere Informationen über gute Reviews findest du unter Überprüfen von Änderungen.
Aufgaben
Tägliche Aufgaben in einer einwöchigen Schicht als PR Wrangler:
- Sortiere und kennzeichne täglich eingehende Probleme. Siehe Einstufung und Kategorisierung von Problemen für Richtlinien, wie SIG Docs Metadaten verwendet.
- Überprüfe offene Pull Requests auf Qualität und Einhaltung der Style und Content Leitfäden.
- Beginne mit den kleinsten PRs (
size/XS) und ende mit den größten (size/XXL). Überprüfe so viele PRs, wie du kannst.
- Beginne mit den kleinsten PRs (
- Achte darauf, dass die PR-Autoren den CLA unterschreiben.
- Verwende dieses Skript, um diejenigen, die den CLA noch nicht unterschrieben haben, daran zu erinnern, dies zu tun.
- Gib Feedback zu den Änderungen und bitte die Mitglieder anderer SIGs um technische Überprüfung.
- Gib inline Vorschläge für die vorgeschlagenen inhaltlichen Änderungen in den PR ein.
- Wenn du den Inhalt überprüfen musst, kommentiere den PR und bitte um weitere Details.
- Vergebe das/die entsprechende(n)
sig/-Label. - Falls nötig, weise die Reviever aus dem Block
revievers:im Vorspann der Datei zu.
- Benutze den Kommentar
/approve, um einen PR zum Zusammenführen zu genehmigen. Führe den PR zusammen, wenn er inhaltlich und technisch einwandfrei ist.- PRs sollten einen
/lgtm-Kommentar von einem anderen Mitglied haben, bevor sie zusammengeführt werden. - Erwäge, technisch korrekte Inhalte zu akzeptieren, die nicht den Stilrichtlinien entsprechen. Eröffne ein neues Thema mit dem Label
good first issue, um Stilprobleme anzusprechen.
- PRs sollten einen
Hilfreiche GitHub-Anfragen für Wranglers
Die folgenden Anfragen sind beim Wrangling hilfreich.
Wenn du diese Anfragen abgearbeitet hast, ist die verbleibende Liste der zu prüfenden PRs meist klein.
Diese Anfragen schließen Lokalisierungs-PRs aus. Alle Anfragen beziehen sich auf den main-Branch, außer der letzten.
- Kein CLA, nicht zusammenfürbar: Erinnere den Beitragenden daran, den CLA zu unterschreiben. Wenn sowohl der Bot als auch ein Mensch sie daran erinnert haben, schließe den PR und erinnere die Autoren daran, dass sie ihn erneut öffnen können, nachdem sie den CLA unterschrieben haben. Überprüfe keine PRs, deren Autoren den CLA nicht unterschrieben haben!
- Benötigt LGTM: Listet PRs auf, die ein LGTM von einem Mitglied benötigen. Wenn der PR eine technische Überprüfung benötigt, schalte einen der vom Bot vorgeschlagenen Reviewer ein. Wenn der Inhalt überarbeitet werden muss, füge Vorschläge und Feedback in-line hinzu.
- Hat LGTM, braucht die Zustimmung von Docs:
Listet PRs auf, die einen
/approve-Kommentar benötigen, um zusammengeführt zu werden. - Quick Wins: Listet PRs gegen den Hauptzweig auf, die nicht eindeutig blockiert sind. (ändere "XS" in der Größenbezeichnung, wenn du dich durch die PRs arbeitest [XS, S, M, L, XL, XXL]).
- Nicht gegen den
main-Branch: Wenn der PR gegen einendev-Ast gerichtet ist, ist er für eine kommende Veröffentlichung. Weise diesen dem Docs Release Manager zu:/assign @<manager's_github-username>. Wenn der PR gegen einen alten Ast gerichtet ist, hilf dem Autor herauszufinden, ob er auf den richtigen Ast gerichtet ist.
Hilfreiche Prow-Befehle für Wranglers
# Englisches Label hinzufügen
/language en
# füge dem PR ein Squash-Label hinzu, wenn es mehr als einen Commit gibt
/label tide/merge-method-squash
# einen PR ueber Prow neu betiteln (z.B. als Work-in-Progress [WIP])
/retitle [WIP] <TITLE>
Wann sind Pull Requests zu schließen
Reviews und Genehmigungen sind ein Mittel, um unsere PR-Warteschlange kurz und aktuell zu halten. Ein weiteres Mittel ist das Schließen.
PRs werden geschlossen, wenn:
-
Der Autor den CLA seit zwei Wochen nicht unterschrieben hat.
Die Autoren können den PR wieder öffnen, nachdem sie den CLA unterschrieben haben. Dies ist ein risikoarmer Weg, um sicherzustellen, dass nichts zusammengeführt wird, ohne dass ein CLA unterzeichnet wurde.
-
Der Autor hat seit Zwei oder mehr Wochen nicht auf Kommentare oder Feedback geantwortet.
Hab keine Angst, Pull Requests zu schließen. Mitwirkende können sie leicht wieder öffnen und die laufenden Arbeiten fortsetzen. Oft ist es die Nachricht über die Schließung, die einen Autor dazu anspornt, seinen Beitrag wieder aufzunehmen und zu beenden.
Um eine Pull-Anfrage zu schließen, hinterlasse einen /close-Kommentar zu dem PR.
k8s-ci-robot Bot markiert Themen nach 90 Tagen Inaktivität als veraltet. Nach weiteren 30 Tagen markiert er Issues als faul und schließt sie. PR-Beauftragte sollten Themen nach 14-30 Tagen Inaktivität schließen.
8 -
Klicken Sie auf Tags oder verwenden Sie die Dropdown-Liste zum Filtern. Klicken Sie auf Tabellenköpfe, um die Ergebnisse zu sortieren oder umzukehren.
Nach Konzept filtern:
Nach Objekt filtern:
Nach Befehl filtern: