Das ist eine für den Ausdruck optimierte Ansicht des gesamten Kapitels inkl. Unterseiten. Druckvorgang starten.
Kubernetes Architektur
1 - Nodes
Ein Knoten (Node in Englisch) ist eine Arbeitsmaschine in Kubernetes. Ein Node kann je nach Cluster eine VM oder eine physische Maschine sein. Jeder Node enthält die für den Betrieb von Pods notwendigen Dienste und wird von den Master-Komponenten verwaltet. Die Dienste auf einem Node umfassen die Container Runtime, das Kubelet und den Kube-Proxy. Weitere Informationen finden Sie im Abschnitt Kubernetes Node in der Architekturdesign-Dokumentation.
Node Status
Der Status eines Nodes enthält folgende Informationen:
Jeder Abschnitt wird folgend detailliert beschrieben.
Adressen
Die Verwendung dieser Felder hängt von Ihrem Cloud-Anbieter oder der Bare-Metal-Konfiguration ab.
- HostName: Der vom Kernel des Nodes gemeldete Hostname. Kann mit dem kubelet-Parameter
--hostname-overrideüberschrieben werden. - ExternalIP: In der Regel die IP-Adresse des Nodes, die extern geroutet werden kann (von außerhalb des Clusters verfügbar).
- InternalIP: In der Regel die IP-Adresse des Nodes, die nur innerhalb des Clusters routbar ist.
Zustand
Das conditions Feld beschreibt den Zustand, aller Running Nodes.
| Node Condition | Beschreibung |
|---|---|
OutOfDisk |
True wenn auf dem Node nicht genügend freier Speicherplatz zum Hinzufügen neuer Pods vorhanden ist, andernfalls False |
Ready |
True wenn der Node in einem guten Zustand und bereit ist Pods aufzunehmen, False wenn der Node nicht in einem guten Zustand ist und nicht bereit ist Pods aufzunehmeb, und Unknown wenn der Node-Controller seit der letzten node-monitor-grace-period nichts von dem Node gehört hat (Die Standardeinstellung beträgt 40 Sekunden) |
MemoryPressure |
True wenn der verfügbare Speicher des Nodes niedrig ist; AndernfallsFalse |
PIDPressure |
True wenn zu viele Prozesse auf dem Node vorhanden sind; AndernfallsFalse |
DiskPressure |
True wenn die Festplattenkapazität niedrig ist. Andernfalls False |
NetworkUnavailable |
True wenn das Netzwerk für den Node nicht korrekt konfiguriert ist, andernfalls False |
Der Zustand eines Nodes wird als JSON-Objekt dargestellt. Die folgende Antwort beschreibt beispielsweise einen fehlerfreien Node.
"conditions": [
{
"type": "Ready",
"status": "True"
}
]
Wenn der Status der Ready-Bedingung Unknown oder False länger als der pod-eviction-timeout bleibt, wird ein Parameter an den kube-controller-manager übergeben und alle Pods auf dem Node werden vom Node Controller gelöscht.
Die voreingestellte Zeit vor der Entfernung beträgt fünf Minuten. In einigen Fällen, in denen der Node nicht erreichbar ist, kann der Apiserver nicht mit dem Kubelet auf dem Node kommunizieren. Die Entscheidung, die Pods zu löschen, kann dem Kublet erst mitgeteilt werden, wenn die Kommunikation mit dem Apiserver wiederhergestellt ist. In der Zwischenzeit können Pods, deren Löschen geplant ist, weiterhin auf dem unzugänglichen Node laufen.
In Versionen von Kubernetes vor 1.5 würde der Node Controller das Löschen dieser unerreichbaren Pods vom Apiserver erzwingen. In Version 1.5 und höher erzwingt der Node Controller jedoch keine Pod Löschung, bis bestätigt wird, dass sie nicht mehr im Cluster ausgeführt werden. Pods die auf einem unzugänglichen Node laufen sind eventuell in einem einem Terminating oder Unkown Status. In Fällen, in denen Kubernetes nicht aus der zugrunde liegenden Infrastruktur schließen kann, ob ein Node einen Cluster dauerhaft verlassen hat, muss der Clusteradministrator den Node möglicherweise manuell löschen.
Das Löschen des Kubernetes-Nodeobjekts bewirkt, dass alle auf dem Node ausgeführten Pod-Objekte gelöscht und deren Namen freigegeben werden.
In Version 1.12 wurde die Funktion TaintNodesByCondition als Beta-Version eingeführt, die es dem Node-Lebenszyklus-Controller ermöglicht, automatisch Markierungen (taints in Englisch) zu erstellen, die Bedingungen darstellen.
Ebenso ignoriert der Scheduler die Bedingungen, wenn er einen Node berücksichtigt; stattdessen betrachtet er die Markierungen (taints) des Nodes und die Toleranzen eines Pod.
Anwender können jetzt zwischen dem alten Scheduling-Modell und einem neuen, flexibleren Scheduling-Modell wählen.
Ein Pod, der keine Toleranzen aufweist, wird gemäß dem alten Modell geplant. Aber ein Pod, die die Taints eines bestimmten Node toleriert, kann auf diesem Node geplant werden.
Kapazität
Beschreibt die auf dem Node verfügbaren Ressourcen: CPU, Speicher und die maximale Anzahl der Pods, die auf dem Node ausgeführt werden können.
Info
Allgemeine Informationen zum Node, z. B. Kernelversion, Kubernetes-Version (kubelet- und kube-Proxy-Version), Docker-Version (falls verwendet), Betriebssystemname. Die Informationen werden von Kubelet vom Node gesammelt.
Management
Im Gegensatz zu Pods und Services, ein Node wird nicht von Kubernetes erstellt: Er wird extern von Cloud-Anbietern wie Google Compute Engine erstellt oder ist in Ihrem Pool physischer oder virtueller Maschinen vorhanden. Wenn Kubernetes also einen Node erstellt, wird ein Objekt erstellt, das den Node darstellt. Nach der Erstellung überprüft Kubernetes, ob der Node gültig ist oder nicht.
Wenn Sie beispielsweise versuchen, einen Node aus folgendem Inhalt zu erstellen:
{
"kind": "Node",
"apiVersion": "v1",
"metadata": {
"name": "10.240.79.157",
"labels": {
"name": "my-first-k8s-node"
}
}
}
Kubernetes erstellt intern ein Node-Objekt (die Darstellung) und validiert den Node durch Zustandsprüfung basierend auf dem Feld metadata.name.
Wenn der Node gültig ist, d.h. wenn alle notwendigen Dienste ausgeführt werden, ist er berechtigt, einen Pod auszuführen.
Andernfalls wird er für alle Clusteraktivitäten ignoriert, bis er gültig wird.
Aktuell gibt es drei Komponenten, die mit dem Kubernetes Node-Interface interagieren: Node Controller, Kubelet und Kubectl.
Node Controller
Der Node Controller ist eine Kubernetes-Master-Komponente, die verschiedene Aspekte von Nodes verwaltet.
Der Node Controller hat mehrere Rollen im Leben eines Nodes. Der erste ist die Zuordnung eines CIDR-Blocks zu dem Node, wenn er registriert ist (sofern die CIDR-Zuweisung aktiviert ist).
Die zweite ist, die interne Node-Liste des Node Controllers mit der Liste der verfügbaren Computer des Cloud-Anbieters auf dem neuesten Stand zu halten. Wenn ein Node in einer Cloud-Umgebung ausgeführt wird und sich in einem schlechten Zustand befindet, fragt der Node Controller den Cloud-Anbieter, ob die virtuelle Maschine für diesen Node noch verfügbar ist. Wenn nicht, löscht der Node Controller den Node aus seiner Node-Liste.
Der dritte ist die Überwachung des Zustands der Nodes. Der Node Controller ist dafür verantwortlich, die NodeReady-Bedingung von NodeStatus auf ConditionUnknown zu aktualisieren, wenn ein Node unerreichbar wird (der Node Controller empfängt aus irgendeinem Grund keine Herzschläge mehr, z.B. weil der Node heruntergefahren ist) und später alle Pods aus dem Node zu entfernen (und diese ordnungsgemäss zu beenden), wenn der Node weiterhin unzugänglich ist. (Die Standard-Timeouts sind 40s, um ConditionUnknown zu melden und 5 Minuten, um mit der Evakuierung der Pods zu beginnen).
Der Node Controller überprüft den Zustand jedes Nodes alle --node-monitor-period Sekunden.
In Versionen von Kubernetes vor 1.13 ist NodeStatus der Herzschlag des Nodes.
Ab Kubernetes 1.13 wird das Node-Lease-Feature als Alpha-Feature eingeführt (Feature-Gate NodeLease, KEP-0009).
Wenn die Node Lease Funktion aktiviert ist, hat jeder Node ein zugeordnetes Lease-Objekt im kube-node-lease-Namespace, das vom Node regelmäßig erneuert wird.
Sowohl NodeStatus als auch Node Lease werden als Herzschläge vom Node aus behandelt.
Node Leases werden häufig erneuert, während NodeStatus nur dann vom Node zu Master gemeldet wird, wenn sich etwas ändert oder genügend Zeit vergangen ist (Standard ist 1 Minute, was länger ist als der Standard-Timeout von 40 Sekunden für unerreichbare Nodes).
Da Node Leases viel lastärmer sind als NodeStatus, macht diese Funktion den Node Herzschlag sowohl in Bezug auf Skalierbarkeit als auch auf die Leistung deutlich effizienter.
In Kubernetes 1.4 haben wir die Logik der Node-Steuerung aktualisiert, um Fälle besser zu handhaben, in denen eine große Anzahl von Nodes Probleme hat, den Master zu erreichen (z.B. weil der Master Netzwerkprobleme hat). Ab 1.4 betrachtet der Node-Controller den Zustand aller Nodes im Cluster, wenn er eine Entscheidung über die Enterfung eines Pods trifft.
In den meisten Fällen begrenzt der Node-Controller die Entfernungsrate auf --node-eviction-rate (Standard 0,1) pro Sekunde, was bedeutet, dass er die Pods nicht von mehr als einem Node pro 10 Sekunden entfernt.
Das Entfernungsverhalten von Nodes ändert sich, wenn ein Node in einer bestimmten Verfügbarkeitszone ungesund wird.
Der Node-Controller überprüft gleichzeitig, wie viel Prozent der Nodes in der Zone ungesund sind (NodeReady-Bedingung ist ConditionUnknown oder ConditionFalse).
Wenn der Anteil der ungesunden Nodes mindestens --unhealthy-zone-threshold (Standard 0,55) beträgt, wird die Entfernungsrate reduziert:
Wenn der Cluster klein ist (d.h. weniger als oder gleich --large-cluster-size-threshold Node - Standard 50), werden die Entfernungen gestoppt. Andernfalls wird die Entfernungsrate auf --secondary-node-eviction-rate (Standard 0,01) pro Sekunde reduziert.
Der Grund, warum diese Richtlinien pro Verfügbarkeitszone implementiert werden, liegt darin, dass eine Verfügbarkeitszone vom Master unerreichbar werden könnte, während die anderen verbunden bleiben. Wenn Ihr Cluster nicht mehrere Verfügbarkeitszonen von Cloud-Anbietern umfasst, gibt es nur eine Verfügbarkeitszone (den gesamten Cluster).
Ein wichtiger Grund für die Verteilung Ihrer Nodes auf Verfügbarkeitszonen ist, dass die Arbeitsbelastung auf gesunde Zonen verlagert werden kann, wenn eine ganze Zone ausfällt.
Wenn also alle Nodes in einer Zone ungesund sind, entfernt Node Controller mit der normalen --node-eviction-rate Geschwindigkeit.
Der Ausnahmefall ist, wenn alle Zonen völlig ungesund sind (d.h. es gibt keine gesunden Node im Cluster).
In diesem Fall geht der Node-Controller davon aus, dass es ein Problem mit der Master-Konnektivität gibt und stoppt alle Entfernungen, bis die Verbindung wiederhergestellt ist.
Ab Kubernetes 1.6 ist der Node-Controller auch für die Entfernung von Pods zuständig, die auf Nodes mit NoExecute-Taints laufen, wenn die Pods die Markierungen nicht tolerieren.
Zusätzlich ist der NodeController als Alpha-Funktion, die standardmäßig deaktiviert ist, dafür verantwortlich, Taints hinzuzufügen, die Node Probleme, wie Node unreachable oder not ready entsprechen.
Siehe diese Dokumentation für Details über NoExecute Taints und die Alpha-Funktion.
Ab Version 1.8 kann der Node-Controller für die Erzeugung von Taints, die Node Bedingungen darstellen, verantwortlich gemacht werden. Dies ist eine Alpha-Funktion der Version 1.8.
Selbstregistrierung von Nodes
Wenn das Kubelet-Flag --register-node aktiv ist (Standard), versucht das Kubelet, sich beim API-Server zu registrieren. Dies ist das bevorzugte Muster, das von den meisten Distributionen verwendet wird.
Zur Selbstregistrierung wird das kubelet mit den folgenden Optionen gestartet:
--kubeconfig- Pfad zu Anmeldeinformationen, um sich beim Apiserver zu authentifizieren.--cloud-provider- Wie man sich mit einem Cloud-Anbieter unterhält, um Metadaten über sich selbst zu lesen.--register-node- Automatisch beim API-Server registrieren.--register-with-taints- Registrieren Sie den Node mit der angegebenen Taints-Liste (Kommagetrennt<key>=<value>:<effect>). No-op wennregister-nodefalse ist.--node-ip- IP-Adresse des Nodes.--node-labels- Labels, die bei der Registrierung des Nodes im Cluster hinzugefügt werden sollen (Beachten Sie die Richlinien des NodeRestriction admission plugin in 1.13+).--node-status-update-frequency- Gibt an, wie oft kubelet den Nodestatus an den Master übermittelt.
Wenn der Node authorization mode und NodeRestriction admission plugin aktiviert sind, dürfen kubelets nur ihre eigene Node-Ressource erstellen / ändern.
Manuelle Nodeverwaltung
Ein Cluster-Administrator kann Nodeobjekte erstellen und ändern.
Wenn der Administrator Nodeobjekte manuell erstellen möchte, setzen Sie das kubelet Flag --register-node=false.
Der Administrator kann Node-Ressourcen ändern (unabhängig von der Einstellung von --register-node).
Zu den Änderungen gehören das Setzen von Labels und das Markieren des Nodes.
Labels auf Nodes können in Verbindung mit node selectors auf Pods verwendet werden, um die Planung zu steuern, z.B. um einen Pod so zu beschränken, dass er nur auf einer Teilmenge der Nodes ausgeführt werden darf.
Das Markieren eines Nodes als nicht geplant, verhindert, dass neue Pods für diesen Node geplant werden. Dies hat jedoch keine Auswirkungen auf vorhandene Pods auf dem Node. Dies ist nützlich als vorbereitender Schritt vor einem Neustart eines Nodes usw. Um beispielsweise einen Node als nicht geplant zu markieren, führen Sie den folgenden Befehl aus:
kubectl cordon $NODENAME
Node Kapazität
Die Kapazität des Nodes (Anzahl der CPU und Speichermenge) ist Teil des Nodeobjekts. Normalerweise registrieren sich Nodes selbst und melden ihre Kapazität beim Erstellen des Nodeobjekts. Sofern Sie Manuelle Nodeverwaltung betreiben, müssen Sie die Node Kapazität setzen, wenn Sie einen Node hinzufügen.
Der Kubernetes-Scheduler stellt sicher, dass für alle Pods auf einem Nodes genügend Ressourcen vorhanden sind. Er prüft, dass die Summe der Requests von Containern auf dem Node nicht größer ist als die Kapazität des Nodes. Er beinhaltet alle Container die vom kubelet gestarted worden, aber keine Container die direkt von der container runtime gestartet wurden, noch jegleiche Prozesse die ausserhalb von Containern laufen.
Wenn Sie Ressourcen explizit für Nicht-Pod-Prozesse reservieren möchten, folgen Sie diesem Lernprogramm um Ressourcen für Systemdaemons zu reservieren.
API-Objekt
Node ist eine Top-Level-Ressource in der Kubernetes-REST-API. Weitere Details zum API-Objekt finden Sie unter: Node API object.
2 - Master-Node Kommunikation
Dieses Dokument katalogisiert die Kommunikationspfade zwischen dem Master (eigentlich dem Apiserver) und des Kubernetes-Clusters. Die Absicht besteht darin, Benutzern die Möglichkeit zu geben, ihre Installation so anzupassen, dass die Netzwerkkonfiguration so abgesichert wird, dass der Cluster in einem nicht vertrauenswürdigen Netzwerk (oder mit vollständig öffentlichen IP-Adressen eines Cloud-Providers) ausgeführt werden kann.
Cluster zum Master
Alle Kommunikationspfade vom Cluster zum Master enden beim Apiserver (keine der anderen Master-Komponenten ist dafür ausgelegt, Remote-Services verfügbar zu machen). In einem typischen Setup ist der Apiserver so konfiguriert, dass er Remote-Verbindungen an einem sicheren HTTPS-Port (443) mit einer oder mehreren Formen der Clientauthentifizierung überwacht. Eine oder mehrere Formene von Autorisierung sollte aktiviert sein, insbesondere wenn anonyme Anfragen oder Service Account Tokens aktiviert sind.
Nodes sollten mit dem öffentlichen Stammzertifikat für den Cluster konfiguriert werden, sodass sie eine sichere Verbindung zum Apiserver mit gültigen Client-Anmeldeinformationen herstellen können. Beispielsweise bei einer gewöhnlichen GKE-Konfiguration enstprechen die dem kubelet zur Verfügung gestellten Client-Anmeldeinformationen eines Client-Zertifikats. Lesen Sie über kubelet TLS bootstrapping zur automatisierten Bereitstellung von kubelet-Client-Zertifikaten.
Pods, die eine Verbindung zum Apiserver herstellen möchten, können dies auf sichere Weise tun, indem sie ein Dienstkonto verwenden, sodass Kubernetes das öffentliche Stammzertifikat und ein gültiges Trägertoken automatisch in den Pod einfügt, wenn er instanziiert wird.
Der kubernetes-Dienst (in allen Namespaces) ist mit einer virtuellen IP-Adresse konfiguriert, die (über den Kube-Proxy) an den HTTPS-Endpunkt auf dem Apiserver umgeleitet wird.
Die Master-Komponenten kommunizieren auch über den sicheren Port mit dem Cluster-Apiserver.
Der Standardbetriebsmodus für Verbindungen vom Cluster (Knoten und Pods, die auf den Knoten ausgeführt werden) zum Master ist daher standardmäßig gesichert und kann über nicht vertrauenswürdige und/oder öffentliche Netzwerke laufen.
Master zum Cluster
Es gibt zwei primäre Kommunikationspfade vom Master (Apiserver) zum Cluster. Der Erste ist vom Apiserver hin zum Kubelet-Prozess, der auf jedem Node im Cluster ausgeführt wird. Der Zweite ist vom Apiserver zu einem beliebigen Node, Pod oder Dienst über die Proxy-Funktionalität des Apiservers.
Apiserver zum kubelet
Die Verbindungen vom Apiserver zum Kubelet werden verwendet für:
- Das Abrufen von Protokollen für Pods.
- Das Verbinden (durch kubectl) mit laufenden Pods.
- Die Bereitstellung der Portweiterleitungsfunktion des kubelet.
Diese Verbindungen enden am HTTPS-Endpunkt des kubelet. Standardmäßig überprüft der Apiserver das Serverzertifikat des Kubelets nicht, was die Verbindung angreifbar für Man-in-the-Middle-Angriffe macht. Die Kommunikation ist daher unsicher, wenn die Verbindungen über nicht vertrauenswürdige und/oder öffentliche Netzwerke laufen.
Um diese Verbindung zu überprüfen, verwenden Sie das Flag --kubelet-certificate-authority, um dem Apiserver ein Stammzertifikatbündel bereitzustellen, das zur Überprüfung des Server-Zertifikats des kubelets verwendet wird.
Wenn dies nicht möglich ist, verwenden Sie SSH tunneling zwischen dem Apiserver und dem kubelet, falls es erforderlich ist eine Verbindung über ein nicht vertrauenswürdiges oder öffentliches Netz zu vermeiden.
Außerdem sollte Kubelet Authentifizierung und/oder Autorisierung aktiviert sein, um die kubelet-API abzusichern.
Apiserver zu Nodes, Pods und Services
Die Verbindungen vom Apiserver zu einem Node, Pod oder Dienst verwenden standardmäßig einfache HTTP-Verbindungen und werden daher weder authentifiziert noch verschlüsselt. Sie können über eine sichere HTTPS-Verbindung ausgeführt werden, indem dem Node, dem Pod oder dem Servicenamen in der API-URL "https:" vorangestellt wird. Das vom HTTPS-Endpunkt bereitgestellte Zertifikat wird jedoch nicht überprüft, und es werden keine Clientanmeldeinformationen bereitgestellt. Die Verbindung wird zwar verschlüsselt, garantiert jedoch keine Integrität. Diese Verbindungen sind derzeit nicht sicher innerhalb von nicht vertrauenswürdigen und/oder öffentlichen Netzen.
SSH Tunnels
Kubernetes unterstützt SSH-Tunnel zum Schutz der Master -> Cluster Kommunikationspfade. In dieser Konfiguration initiiert der Apiserver einen SSH-Tunnel zu jedem Node im Cluster (Verbindung mit dem SSH-Server, der mit Port 22 läuft), und leitet den gesamten Datenverkehr für ein kubelet, einen Node, einen Pod oder einen Dienst durch den Tunnel. Dieser Tunnel stellt sicher, dass der Datenverkehr nicht außerhalb des Netzwerks sichtbar ist, in dem die Knoten ausgeführt werden.
SSH-Tunnel werden zur Zeit nicht unterstützt. Sie sollten also nicht verwendet werden, sei denn, man weiß, was man tut. Ein Ersatz für diesen Kommunikationskanal wird entwickelt.
3 - Zugrunde liegende Konzepte des Cloud Controller Manager
Das Konzept des Cloud Controller Managers (CCM) (nicht zu verwechseln mit der Binärdatei) wurde ursprünglich entwickelt, um Cloud-spezifischen Anbieter Code und den Kubernetes Kern unabhängig voneinander entwickeln zu können. Der Cloud Controller Manager läuft zusammen mit anderen Master Komponenten wie dem Kubernetes Controller Manager, dem API-Server und dem Scheduler auf dem Host. Es kann auch als Kubernetes Addon gestartet werden, in diesem Fall läuft er auf Kubernetes.
Das Design des Cloud Controller Managers basiert auf einem Plugin Mechanismus, der es neuen Cloud Anbietern ermöglicht, sich mit Kubernetes einfach über Plugins zu integrieren. Es gibt Pläne für die Einbindung neuer Cloud Anbieter auf Kubernetes und für die Migration von Cloud Anbietern vom alten Modell auf das neue CCM-Modell.
Dieses Dokument beschreibt die Konzepte hinter dem Cloud Controller Manager und gibt Details zu den damit verbundenen Funktionen.
Die Architektur eines Kubernetes Clusters ohne den Cloud Controller Manager sieht wie folgt aus:
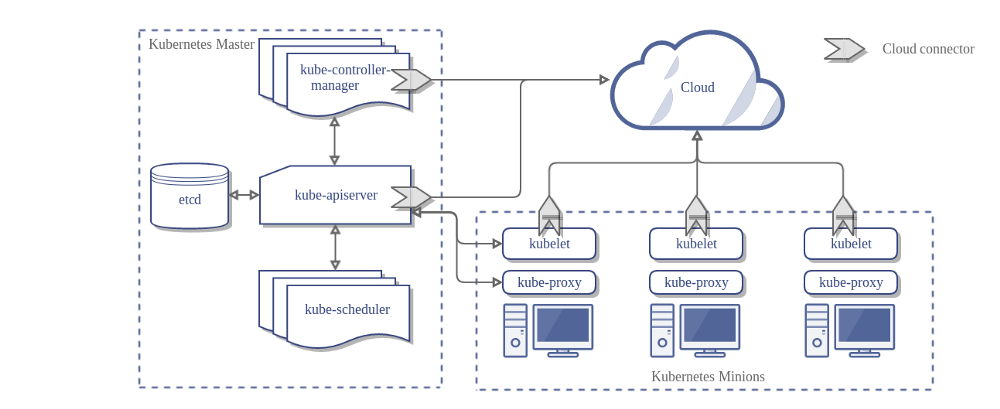
Design
Im vorhergehenden Diagramm sind Kubernetes und der Cloud-Provider über mehrere verschiedene Komponenten integriert:
- Kubelet
- Kubernetes Controller Manager
- Kubernetes API Server
CCM konsolidiert die gesamte Abhängigkeit der Cloud Logik von den drei vorhergehenden Komponenten zu einem einzigen Integrationspunkt mit der Cloud. So sieht die neue Architektur mit dem CCM aus:
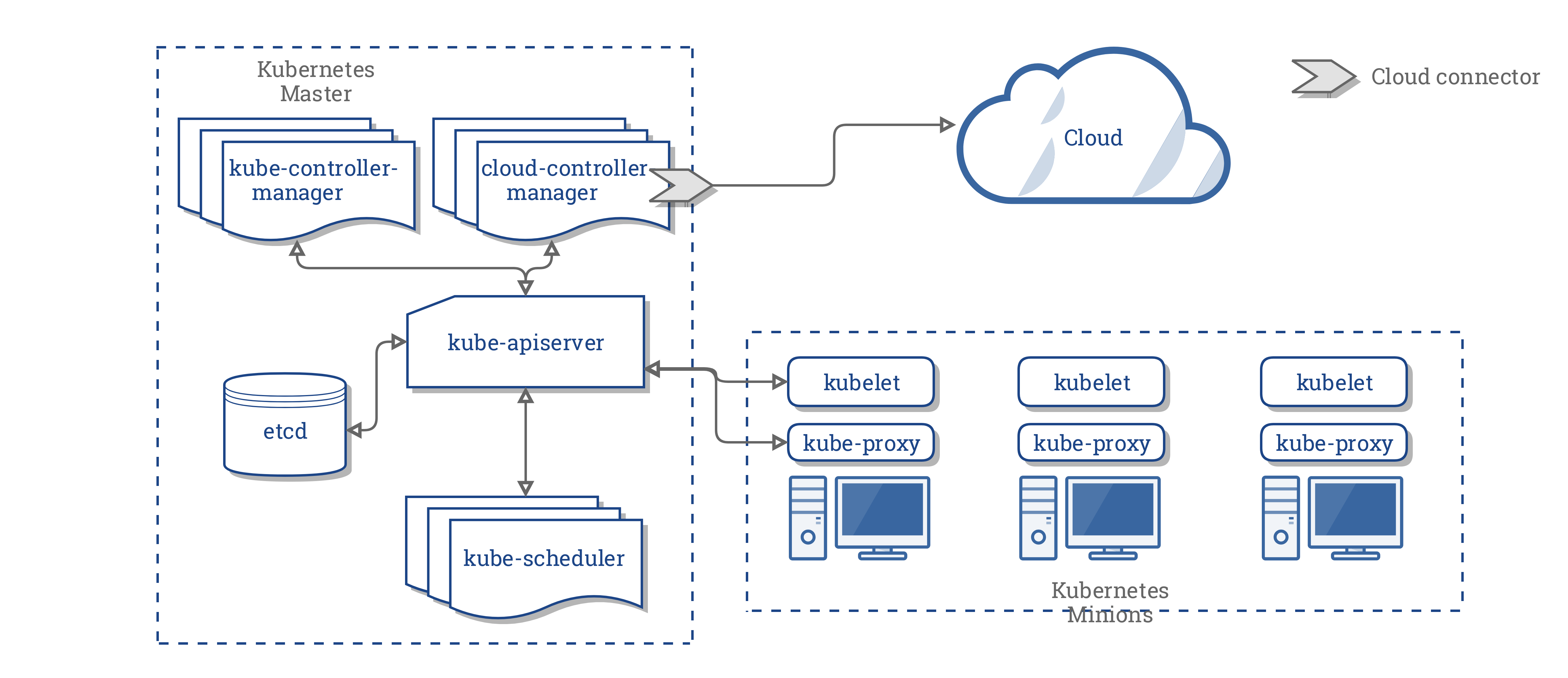
Komponenten des CCM
Der CCM löst einen Teil der Funktionalität des Kubernetes Controller Managers (KCM) ab und führt ihn als separaten Prozess aus. Konkret trennt es die Cloud abhängigen Controller im KCM. Der KCM verfügt über die folgenden Cloud abhängigen Steuerungsschleifen:
- Node Controller
- Volume Controller
- Route Controller
- Service Controller
In der Version 1.9 führt der CCM die folgenden Controller aus der vorhergehenden Liste aus:
- Node Controller
- Route Controller
- Service Controller
Der ursprüngliche Plan, Volumes mit CCM zu integrieren, sah die Verwendung von Flex-Volumes vor welche austauschbare Volumes unterstützt. Allerdings ist eine konkurrierende Initiative namens CSI geplant, um Flex zu ersetzen.
In Anbetracht dieser Dynamik haben wir uns entschieden, eine Zwischenstopp durchzuführen um die Unterschiede zu beobachten , bis das CSI bereit ist.
Funktionen des CCM
Der CCM erbt seine Funktionen von Komponenten des Kubernetes, die von einem Cloud Provider abhängig sind. Dieser Abschnitt ist auf der Grundlage dieser Komponenten strukturiert.
1. Kubernetes Controller Manager
Die meisten Funktionen des CCM stammen aus dem KCM. Wie im vorherigen Abschnitt erwähnt, führt das CCM die folgenden Steuerschleifen durch:
- Node Controller
- Route Controller
- Service Controller
Node Controller
Der Node Controller ist für die Initialisierung eines Knotens verantwortlich, indem er Informationen über die im Cluster laufenden Knoten vom Cloud Provider erhält. Der Node Controller führt die folgenden Funktionen aus:
- Initialisierung eines Knoten mit Cloud-spezifischen Zonen-/Regionen Labels.
- Initialisieren von Knoten mit Cloud-spezifischen Instanzdetails, z.B. Typ und Größe.
- Ermitteln der Netzwerkadressen und des Hostnamen des Knotens.
- Falls ein Knoten nicht mehr reagiert, überprüft der Controller die Cloud, um festzustellen, ob der Knoten aus der Cloud gelöscht wurde. Wenn der Knoten aus der Cloud gelöscht wurde, löscht der Controller das Kubernetes Node Objekt.
Route Controller
Der Route Controller ist dafür verantwortlich, Routen in der Cloud so zu konfigurieren, dass Container auf verschiedenen Knoten im Kubernetes Cluster miteinander kommunizieren können. Der Route Controller ist nur auf einem Google Compute Engine Cluster anwendbar.
Service Controller
Der Service Controller ist verantwortlich für das Abhören von Ereignissen zum Erstellen, Aktualisieren und Löschen von Diensten. Basierend auf dem aktuellen Stand der Services in Kubernetes konfiguriert es Cloud Load Balancer (wie ELB, Google LB oder Oracle Cloud Infrastructure LB), um den Zustand der Services in Kubernetes abzubilden. Darüber hinaus wird sichergestellt, dass die Service Backends für Cloud Loadbalancer auf dem neuesten Stand sind.
2. Kubelet
Der Node Controller enthält die Cloud-abhängige Funktionalität des Kubelets. Vor der Einführung des CCM war das Kubelet für die Initialisierung eines Knotens mit cloudspezifischen Details wie IP-Adressen, Regions-/Zonenbezeichnungen und Instanztypinformationen verantwortlich. Mit der Einführung des CCM wurde diese Initialisierungsoperation aus dem Kubelet in das CCM verschoben.
In diesem neuen Modell initialisiert das Kubelet einen Knoten ohne cloudspezifische Informationen. Es fügt jedoch dem neu angelegten Knoten einen Taint hinzu, der den Knoten nicht verplanbar macht, bis der CCM den Knoten mit cloudspezifischen Informationen initialisiert. Dann wird der Taint entfernt.
Plugin Mechanismus
Der Cloud Controller Manager verwendet die Go Schnittstellen, um Implementierungen aus jeder Cloud einzubinden. Konkret verwendet dieser das CloudProvider Interface, das hier definiert ist.
Die Implementierung der vier oben genannten geteiltent Controllern und einigen Scaffolding sowie die gemeinsame CloudProvider Schnittstelle bleiben im Kubernetes Kern. Cloud Provider spezifische Implementierungen werden außerhalb des Kerns aufgebaut und implementieren im Kern definierte Schnittstellen.
Weitere Informationen zur Entwicklung von Plugins findest du im Bereich Entwickeln von Cloud Controller Manager.
Autorisierung
Dieser Abschnitt beschreibt den Zugriff, den der CCM für die Ausführung seiner Operationen auf verschiedene API Objekte benötigt.
Node Controller
Der Node Controller funktioniert nur mit Node Objekten. Es benötigt vollen Zugang zu get, list, create, update, patch, watch, und delete Node Objekten.
v1/Node:
- Get
- List
- Create
- Update
- Patch
- Watch
- Delete
Route Controller
Der Route Controller horcht auf die Erstellung von Node Objekten und konfiguriert die Routen entsprechend. Es erfordert get Zugriff auf die Node Objekte.
v1/Node:
- Get
Service Controller
Der Service Controller hört auf die Service Objekt Events create, update und delete und konfiguriert dann die Endpunkte für diese Services entsprechend.
Um auf Services zuzugreifen, benötigt man list und watch Berechtigung. Um die Services zu aktualisieren, sind patch und update Zugriffsrechte erforderlich.
Um die Endpunkte für die Dienste einzurichten, benötigt der Controller Zugriff auf create, list, get, watch und update.
v1/Service:
- List
- Get
- Watch
- Patch
- Update
Sonstiges
Die Implementierung des Kerns des CCM erfordert den Zugriff auf die Erstellung von Ereignissen und zur Gewährleistung eines sicheren Betriebs den Zugriff auf die Erstellung von ServiceAccounts.
v1/Event:
- Create
- Patch
- Update
v1/ServiceAccount:
- Create
Die RBAC ClusterRole für CCM sieht wie folgt aus:
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: cloud-controller-manager
rules:
- apiGroups:
- ""
resources:
- events
verbs:
- create
- patch
- update
- apiGroups:
- ""
resources:
- nodes
verbs:
- '*'
- apiGroups:
- ""
resources:
- nodes/status
verbs:
- patch
- apiGroups:
- ""
resources:
- services
verbs:
- list
- patch
- update
- watch
- apiGroups:
- ""
resources:
- serviceaccounts
verbs:
- create
- apiGroups:
- ""
resources:
- persistentvolumes
verbs:
- get
- list
- update
- watch
- apiGroups:
- ""
resources:
- endpoints
verbs:
- create
- get
- list
- watch
- update
Anbieter Implementierung
Die folgenden Cloud Anbieter haben CCMs implementiert:
Cluster Administration
Eine vollständige Anleitung zur Konfiguration und zum Betrieb des CCM findest du hier.