이 섹션의 다중 페이지 출력 화면임. 여기를 클릭하여 프린트.
쿠버네티스 블로그
- 쿠버네티스 1.24: gRPC 컨테이너 프로브 베타
- 쿠버네티스 1.22: 새로운 정점에 도달(Reaching New Peaks)
- 당황하지 마세요. 쿠버네티스와 도커
- 쿠버네티스에서 어려움 없이 gRPC 로드밸런싱하기
쿠버네티스 1.24: gRPC 컨테이너 프로브 베타
저자: Sergey Kanzhelev (Google)
번역: 송원석 (쏘카), 손석호 (ETRI), 김상홍 (국민대), 김보배 (11번가)
쿠버네티스 1.24에서 gRPC 프로브 기능이 베타에 진입했으며 기본적으로 사용 가능하다. 이제 HTTP 엔드포인트를 노출하지 않고, gRPC 앱에 대한 스타트업(startup), 활성(liveness) 및 준비성(readiness) 프로브를 구성할 수 있으며, 실행 파일도 필요하지 않는다. 쿠버네티스는 기본적으로 gRPC를 통해 워크로드에 자체적으로(natively) 연결 가능하며, 상태를 쿼리할 수 있다.
약간의 히스토리
시스템이 워크로드의 앱이 정상인지, 정상적으로 시작되었는지, 트래픽을 수용할 수 있는지에 대해 관리하는 것은 유용하다. gRPC 지원이 추가되기 전에도, 쿠버네티스는 이미 컨테이너 이미지 내부에서 실행 파일을 실행하거나, HTTP 요청을 하거나, TCP 연결이 성공했는지 여부를 확인하여 상태를 확인할 수 있었다.
대부분의 앱은, 이러한 검사로 충분하다. 앱이 상태(또는 준비성) 확인을
위한 gRPC 엔드포인트를 제공하는 경우 exec 프로브를
gRPC 상태 확인에 사용하도록 쉽게 용도를 변경할 수 있다.
블로그 기사 쿠버네티스의 gRPC 서버 상태 확인에서, Ahmet Alp Balkan은 이를 수행하는 방법을 설명하였으며, 이는 지금도 여전히 작동하는 메커니즘이다.
이것을 활성화하기 위해 일반적으로 사용하는 도구는 2018년 8월 21일에 생성되었으며, 이 도구의 첫 릴리즈는 2018년 9월 19일에 나왔다.
gRPC 앱 상태 확인을 위한 이 접근 방식은 매우 인기있다. grpc_health_probe를 포함하고 있는 Dockerfile은 3,626개이며, (문서 작성 시점에)GitHub의 기본 검색으로 발견된 yaml 파일은 6,621개가 있다. 이것은 도구의 인기와 이를 기본적으로 지원해야 할 필요성을 잘 나타낸다.
쿠버네티스 v1.23은 gRPC를 사용하여 워크로드 상태를 쿼리하는 기본(native) 지원을 알파 수준의 구현으로 기본 지원으로 도입 및 소개했다. 알파 기능이었기 때문에 v1.23 릴리스에서는 기본적으로 비활성화되었다.
기능 사용
우리는 다른 프로브와 유사한 방식으로 gRPC 상태를 확인할 수 있도록 구축했으며, 쿠버네티스의 다른 프로브에 익숙하다면 사용하기 쉬울 것이라 믿는다.
자체적으로 지원되는 상태 프로브는 grpc_health_probe 실행 파일과 관련되어 있던 차선책에 비해 많은 이점이 있다.
기본 gRPC 지원을 사용하면 이미지에 10MB의 추가 실행 파일을 다운로드하여 저장할 필요가 없다.
Exec 프로브는 실행 파일을 실행하기 위해 새 프로세스를 인스턴스화해야 하므로 일반적으로 gRPC 호출보다 느리다.
또한 파드가 리소스 최대치로 실행 중이고 새 프로세스를 인스턴스화하는데 문제가 있는 경우에는 검사의 분별성을 낮추게 만든다.
그러나 여기에는 몇 가지 제약이 있다. 프로브용 클라이언트 인증서(certificate)를 구성하는 것이 어렵기 때문에, 클라이언트 인증(authentication)이 필요한 서비스는 지원하지 않는다. 기본 제공(built-in) 프로브도 서버 인증서를 확인하지 않고 관련 문제를 무시한다.
또한 기본 제공 검사는 특정 유형의 오류를 무시하도록 구성할 수 없으며 (grpc_health_probe는 다른 오류에 대해 다른 종료 코드를 반환함), 단일 프로브에서 여러 서비스 상태 검사를 실행하도록 "연계(chained)"할 수 없다.
그러나 이러한 모든 제한 사항은 gRPC에서 꽤 일반적이며 이에 대한 쉬운 해결 방법이 있다.
직접 해 보기
클러스터 수준의 설정
오늘 이 기능을 사용해 볼 수 있다. 기본 gRPC 프로브 사용을 시도하려면, GRPCContainerProbe 기능 게이트를 활성화하여 쿠버네티스 클러스터를 직접 가동한다. 가용한 도구가 많이 있다.
기능 게이트 GRPCContainerProbe는 1.24에서 기본적으로 활성화되어 있으므로, 많은 공급업체가 이 기능을 즉시 사용 가능하도록 제공할 것이다.
따라서 선택한 플랫폼에서 1.24 클러스터를 그냥 생성하면 된다. 일부 공급업체는 1.23 클러스터에서 알파 기능을 사용 할 수 있도록 허용한다.
예를 들어, 빠른 테스트를 위해 GKE에서 테스트 클러스터를 가동할 수 있다. (해당 문서 작성 시점 기준) 다른 공급업체도 유사한 기능을 가지고 있을 수 있다. 특히 쿠버네티스 1.24 릴리스 이후 이 블로그 게시물을 읽고 있는 경우에는 더욱 그렇다.
GKE에서 다음 명령어를 사용한다. (참고로 버전은 1.23이고 enable-kubernetes-alpha가 지정됨).
gcloud container clusters create test-grpc \
--enable-kubernetes-alpha \
--no-enable-autorepair \
--no-enable-autoupgrade \
--release-channel=rapid \
--cluster-version=1.23
또한 클러스터에 접근하기 위해서 kubectl을 구성할 필요가 있다.
gcloud container clusters get-credentials test-grpc
기능 사용해 보기
gRPC 프로브가 작동하는 방식을 테스트하기 위해 파드를 생성해 보겠다. 이 테스트에서는 agnhost 이미지를 사용한다.
이것은 모든 종류의 워크로드 테스트에 사용할 수 있도록, k8s가 유지 관리하는 이미지다.
예를 들어, 두 개의 포트를 노출하는 유용한 grpc-health-checking 모듈을 가지고 있다. 하나는 상태 확인 서비스를 제공하고 다른 하나는 make-serving 및 make-not-serving 명령에 반응하는 http 포트다.
다음은 파드 정의의 예시이다. 이 예시는 grpc-health-checking 모듈을 시작하고, 포트 5000 및 8080을 노출하며, gRPC 준비성 프로브를 구성한다.
---
apiVersion: v1
kind: Pod
metadata:
name: test-grpc
spec:
containers:
- name: agnhost
# 이미지가 변경됨 (기존에는 "k8s.gcr.io" 레지스트리를 사용)
image: registry.k8s.io/e2e-test-images/agnhost:2.35
command: ["/agnhost", "grpc-health-checking"]
ports:
- containerPort: 5000
- containerPort: 8080
readinessProbe:
grpc:
port: 5000
test.yaml이라는 파일이 있으면, 파드를 생성하고 상태를 확인할 수 있다. 파드는 아래 출력 스니펫(snippet)에 표시된 대로 준비(ready) 상태가 된다.
kubectl apply -f test.yaml
kubectl describe test-grpc
출력에는 다음과 같은 내용이 포함된다.
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
이제 상태 확인 엔드포인트 상태를 NOT_SERVING으로 변경해 보겠다. 파드의 http 포트를 호출하기 위해 포트 포워드를 생성한다.
kubectl port-forward test-grpc 8080:8080
명령을 호출하기 위해 curl을 사용할 수 있다 ...
curl http://localhost:8080/make-not-serving
... 그리고 몇 초 후에 포트 상태가 준비되지 않음으로 전환된다.
kubectl describe pod test-grpc
이제 다음과 같은 출력을 확인할 수 있을 것이다.
Conditions:
Type Status
Initialized True
Ready False
ContainersReady False
PodScheduled True
...
Warning Unhealthy 2s (x6 over 42s) kubelet Readiness probe failed: service unhealthy (responded with "NOT_SERVING")
다시 전환되면, 약 1초 후에 파드가 준비(ready) 상태로 돌아간다.
curl http://localhost:8080/make-serving
kubectl describe test-grpc
아래 출력은 파드가 다시 Ready 상태로 돌아갔다는 것을 나타낸다.
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
쿠버네티스에 내장된 이 새로운 gRPC 상태 프로브를 사용하면 별도의 exec 프로브를 사용하는 이전 접근 방식보다 gRPC를 통한 상태 확인을 훨씬 쉽게 구현할 수 있다. 더 자세한 내용 파악을 위해 공식 문서를 자세히 살펴보고, 기능이 GA로 승격되기 전에 피드백을 제공하길 바란다.
요약
쿠버네티스는 인기 있는 워크로드 오케스트레이션 플랫폼이며 피드백과 수요를 기반으로 기능을 추가한다. gRPC 프로브 지원과 같은 기능은 많은 앱 개발자의 삶을 더 쉽게 만들고 앱을 더 탄력적으로 만들 수 있는 마이너한 개선이다. 오늘 기능을 사용해보고 기능이 GA로 전환되기 전에 오늘 사용해 보고 피드백을 제공해보자.
쿠버네티스 1.22: 새로운 정점에 도달(Reaching New Peaks)
저자: 쿠버네티스 1.22 릴리스 팀
번역: 손석호(ETRI), 서지훈(ETRI), 쿠버네티스 문서 한글화 팀
2021년의 두 번째 릴리스인 쿠버네티스 1.22 릴리스를 발표하게 되어 기쁘게 생각합니다!
이번 릴리스는 53개의 개선 사항(enhancement)으로 구성되어 있습니다. 13개의 개선 사항은 스테이블(stable)로 졸업하였으며(graduated), 24개의 개선 사항은 베타(beta)로 이동하였고, 16개는 알파(alpha)에 진입하였습니다. 또한, 3개의 기능(feature)을 더 이상 사용하지 않게 되었습니다(deprecated).
이번 해 4월에는 쿠버네티스 릴리스 케이던스(cadence)가 1년에 4회에서 3회로 공식적으로 변경되었습니다. 이번 릴리스가 해당 방식에 따라 긴 주기를 가진 첫 번째 릴리스입니다. 쿠버네티스 프로젝트가 성숙해짐에 따라, 사이클(cycle) 당 개선 사항도 늘어나고 있습니다. 이것은 기여자 커뮤니티 및 릴리스 엔지니어링 팀에게, 버전과 버전 사이에 더 많은 작업이 필요하다는 것을 의미합니다. 또한 점점 더 많은 기능을 포함하는 릴리스로 최신 상태를 유지하려는 최종-사용자 커뮤니티에도 부담을 줄 수 있습니다.
연간 4회에서 3회로의 릴리스 케이던스 변경을 통해 프로젝트의 다양한 측면(기여와 릴리스가 관리되는 방법, 업그레이드 및 최신 릴리스 유지에 대한 커뮤니티의 역량 등)에 대한 균형을 이루고자 하였습니다.
더 자세한 사항은 공식 블로그 포스트 쿠버네티스 릴리스 케이던스 변경: 알아두어야 할 사항에서 확인할 수 있습니다.
주요 주제
서버-사이드 어플라이(Server-side Apply)가 GA로 졸업
서버-사이드 어플라이는 쿠버네티스 API 서버에서 동작하는 신규 필드 오너십이며 오브젝트 병합 알고리즘입니다. 서버-사이드 어플라이는 사용자와 컨트롤러가 선언적인 구성을 통해서 자신의 리소스를 관리할 수 있도록 돕습니다. 이 기능은 단순히 fully specified intent를 전송하는 것만으로 자신의 오브젝트를 선언적으로 생성 또는 수정할 수 있도록 허용합니다. 몇 릴리스에 걸친 베타 과정 이후, 서버-사이드 어플라이는 이제 GA(generally available)가 되었습니다.
외부 크리덴셜 제공자가 이제 스테이블이 됨
쿠버네티스 클라이언트 크리덴셜 플러그인에 대한 지원은 1.11부터 베타였으나, 쿠버네티스 1.22 릴리스에서 스테이블로 졸업하였습니다. 해당 GA 기능 집합은 인터랙티브 로그인 플로우(interactive login flow)를 제공하는 플러그인에 대한 향상된 지원을 포함합니다. 또한, 많은 버그가 수정되었습니다. 플러그인 개발은 sample-exec-plugin을 통해 시작할 수 있습니다.
etcd 3.5.0으로 변경
쿠버네티스의 기본 백엔드 저장소인 etcd 3.5.0이 신규로 릴리스되었습니다. 신규 릴리스에는 보안, 성능, 모니터링, 개발자 경험 측면의 개선 사항이 포함되어 있습니다. 많은 버그가 수정되었으며 구조화된 로깅으로 마이그레이션(migration to structured logging) 및 빌트-인 로그 순환(built-in log rotation)과 같은 신규 중요 기능들도 일부 포함되었습니다. 해당 릴리스는 트래픽 부하에 대한 솔루션 구현을 위한 자세한 차기 로드맵도 제시하고 있습니다. 3.5.0 릴리스 발표에서 변경에 대한 자세한 항목을 확인할 수 있습니다.
메모리 리소스에 대한 서비스 품질(Quality of Service)
쿠버네티스는 원래 v1 cgroups API를 사용했습니다. 해당 디자인에 의해서, Pod에 대한 QoS 클래스는 CPU 리소스(예를 들면, cpu_shares)에만 적용되었습니다. 알파 기능으로, 쿠버네티스 v1.22에서는 메모리 할당(allocation)과 격리(isolation)를 제어하기 위한 cgroups v2 API를 사용할 수 있습니다. 이 기능은 메모리 리소스에 대한 컨텐션(contention)이 있을 때 워크로드와 노드의 가용성을 향상시키고, 컨테이너 라이프사이클에 대한 예측 가능성을 향상시킬 수 있도록 디자인되었습니다.
노드 시스템 스왑(swap) 지원
모든 시스템 관리자나 쿠버네티스 사용자는 쿠버네티스를 설정하거나 사용할 때 스왑 공간(space)을 비활성화해야 한다는 동일한 상황에 놓여 있었습니다. 쿠버네티스 1.22 릴리스에서는 노드의 스왑 메모리를 지원합니다(알파). 이 변경은 블록 스토리지의 일부를 추가적인 가상 메모리로 취급하도록, 관리자의 옵트인(opt in)을 받아서 리눅스 노드에 스왑을 구성합니다.
윈도우(Windows) 개선 사항 및 기능
SIG Windows는 계속해서 성장하는 개발자 커뮤니티를 지원하기 위해서 개발 환경을 릴리스하였습니다. 이 새로운 도구는 여러 CNI 제공자를 지원하며, 여러 플랫폼에서 구동할 수 있습니다. 윈도우 kubelet과 kube-proxy를 컴파일하고, 다른 쿠버네티스 컴포넌트와 함께 빌드될 수 있도록 하는 새로운 방법을 제공하여, 최신(bleeding-edge) 윈도우 기능을 스크래치(scratch)부터 실행할 수 있도록 지원합니다.
1.22 릴리스에서 윈도우 노드의 CSI 지원이 GA 상태가 되었습니다. 쿠버네티스 v1.22에서는 특권을 가진(privileged) 윈도우 컨테이너가 알파가 되었습니다. 윈도우 노드에서 CSI 스토리지를 사용하도록, 노드에서의 스토리지 작업에 대한 특권을 가진(privileged) CSIProxy가 CSI 노드 플러그인을 특권을 가지지 않은(unprivileged) 파드로 배치되도록 합니다.
기본(default) seccomp 프로파일
알파 기능인 기본 seccomp 프로파일이 신규 커맨드라인 플래그 및 설정과 함께 kubelet에 추가되었습니다. 이 신규 기능을 사용하면, Unconfined대신 RuntimeDefault seccomp 프로파일을 기본으로 사용하는 seccomp이 클러스터 전반에서 기본이 됩니다. 이는 쿠버네티스 디플로이먼트(Deployment)의 기본 보안을 강화합니다. 워크로드에 대한 보안이 기본으로 더 강화되었으므로, 이제 보안 관리자도 조금 더 안심하고 쉴 수 있습니다. 이 기능에 대한 자세한 사항은 공식적인 seccomp 튜토리얼을 참고하시기 바랍니다.
kubeadm을 통한 보안성이 더 높은 컨트롤 플레인
이 신규 알파 기능을 사용하면 kubeadm 컨트롤 플레인 컴포넌트들을 루트가 아닌(non-root) 사용자로 동작시킬 수 있습니다. 이것은 kubeadm에 오랫동안 요청되어 온 보안 조치 사항입니다. 이 기능을 사용하려면 kubeadm에 한정된 RootlessControlPlane 기능 게이트를 활성화해야 합니다. 이 알파 기능을 사용하여 클러스터를 배치하는 경우, 사용자의 컨트롤 플레인은 더 낮은 특권(privileges)을 가지고 동작하게 됩니다.
또한 쿠버네티스 1.22는 kubeadm의 신규 v1beta3 구성 API를 제공합니다. 이 버전에는 오랫동안 요청되어 온 몇 가지 기능들이 추가되었고, 기존의 일부 기능들은 사용 중단(deprecated)되었습니다. 이제 v1beta3 버전이 선호되는(preferred) API 버전입니다. 그러나, v1beta2 API도 여전히 사용 가능하며 아직 사용 중단(deprecated)되지 않았습니다.
주요 변경 사항
사용 중단된(deprecated) 일부 베타 APIs의 제거
GA 버전과 중복된 사용 중단(deprecated)된 여러 베타 API가 1.22에서 제거되었습니다. 기존의 모든 오브젝트는 스테이블 APIs를 통해 상호 작용할 수 있습니다. 이 제거에는 Ingress, IngressClass, Lease, APIService, ValidatingWebhookConfiguration, MutatingWebhookConfiguration, CustomResourceDefinition, TokenReview, SubjectAccessReview, CertificateSigningRequest API의 베타 버전이 포함되었습니다.
전체 항목은 사용 중단된 API에 대한 마이그레이션 지침과 블로그 포스트 1.22에서 쿠버네티스 API와 제거된 기능: 알아두어야 할 사항에서 확인 가능합니다.
임시(ephemeral) 컨테이너에 대한 API 변경 및 개선
1.22에서 임시 컨테이너를 생성하기 위한 API가 변경되었습니다. 임시 컨테이너 기능은 알파이며 기본적으로 비활성화되었습니다. 신규 API는 예전 API를 사용하려는 클라이언트에 대해 동작하지 않습니다.
스테이블 기능에 대해서, kubectl 도구는 쿠버네티스의 버전 차이(skew) 정책을 따릅니다. 그러나, kubectl v1.21 이하의 버전은 임시 컨테이너에 대한 신규 API를 지원하지 않습니다. 만약 kubectl debug를 사용하여 임시 컨테이너를 생성할 계획이 있고 클러스터에서 쿠버네티스 v1.22로 구동하고 있는 경우, kubectl v1.21 이하의 버전에서는 그렇게 할 수 없다는 것을 알아두어야 합니다. 따라서 만약 클러스터 버전을 혼합하여 kubectl debug를 사용하려면 kubectl를 1.22로 업데이트하길 바랍니다.
기타 업데이트
스테이블로 졸업
- 바운드 서비스 어카운트 토큰 볼륨(Bound Service Account Token Volumes)
- CSI 서비스 어카운트 토큰(CSI Service Account Token)
- 윈도우의 CSI 플러그인 지원
- 사용 중단된 API 사용에 대한 경고(warning) 메커니즘
- PodDisruptionBudget 축출(eviction)
주목할만한 기능 업데이트
- 파드시큐리티폴리시(PodSecurityPolicy)를 대체하기 위한 새로운 파드시큐리티(PodSecurity) 어드미션(admission) 알파 기능이 소개됨.
- 메모리 관리자(manager)가 베타가 됨.
- API 서버 트레이싱(tracing)을 활성화하는 새로운 알파 기능.
- kubeadm 설정(configuration) 포맷의 신규 v1beta3 버전.
- 퍼시스턴트볼륨(PersistentVolume)을 위한 Generic data populators를 알파로 활용 가능.
- 쿠버네티스 컨트롤 플레인이 이제 크론잡 v2 컨트롤러(CronJobs v2 controller)를 사용하게 됨.
- 알파 기능으로, 모든 쿠버네티스 노드 컴포넌트(kubelet, kube-proxy, 컨테이너 런타임을 포함)는 루트가 아닌 사용자로 동작시킬 수 있음.
릴리스 노트
1.22 릴리스의 자세한 전체 사항은 릴리스 노트에서 확인할 수 있습니다.
릴리스 위치
쿠버네티스 1.22는 여기에서 다운로드할 수 있고, GitHub 프로젝트에서도 찾을 수 있습니다.
쿠버네티스를 시작하는 데 도움이 되는 좋은 자료가 많이 있습니다. 쿠버네티스 사이트에서 상호 작용형 튜토리얼을 수행할 수도 있고, kind와 도커 컨테이너를 사용하여 로컬 클러스터를 사용자의 머신에서 구동해볼 수도 있습니다. 클러스터를 스크래치(scratch)부터 구축해보고 싶다면, Kelsey Hightower의 쿠버네티스 어렵게 익히기(the Hard Way) 튜토리얼을 확인해보시기 바랍니다.
릴리스 팀
이 릴리스는 쿠버네티스 릴리스에 포함되는 모든 기술 콘텐츠, 문서, 코드, 기타 구성 요소 등을 제공하기 위해 팀들로 모인 매우 헌신적인 개인 그룹에 의해 가능했습니다.
팀을 성공적인 릴리스로 이끈 릴리스 리드 Savitha Raghunathan에게 감사드리며, 릴리스 팀 이외에도 커뮤니티에 1.22 릴리스를 제공하기 위해 열심히 작업하고 지원한 모든 사람들에게 감사드립니다.
우리는 또한 이 자리를 빌려 올해 초에 생을 마감한 팀 멤버 Peeyush Gupta를 추모하고 싶습니다. Peeyush Gupta는 SIG ContribEx 및 쿠버네티스 릴리스 팀에 활발히 참여했으며, 최근에는 1.22 커뮤니케이션 리드를 역임하였습니다. 그의 기여와 노력은 앞으로도 커뮤니티에 지속적으로 영향을 줄 것입니다. 그에 대한 추억과 추모를 공유하기 위한 CNCF 추모 페이지가 생성되어 있습니다.
릴리스 로고

진행 중인 팬데믹, 자연재해 및 항상 존재하는 번아웃의 그림자 속에서도, 쿠버네티스 1.22 릴리스는 53개의 개선 사항을 제공하였습니다. 이것은 현재까지 가장 큰 릴리스입니다. 이 성과는 열심히 일하고 열정적인 릴리스 팀 구성원과 쿠버네티스 생태계의 대단한 기여자들 덕분에 달성할 수 있었습니다. 이 릴리스 로고는 새로운 마일스톤과 새로운 기록을 세우기 위한 리마인더입니다. 이 로고를 모든 릴리스 팀 구성원, 등산객, 별을 보는 사람들에게 바칩니다!
이 로고는 Boris Zotkin가 디자인하였습니다. Boris는 MathWorks에서 Mac/Linux 관리자 역할을 맡고 있습니다. 그는 인생에서의 소소한 재미를 즐기고 가족과 함께 시간을 보내는 것을 사랑합니다. 이 기술에 정통(tech-savvy)한 개인은 항상 도전을 준비하며 친구를 돕는 것에 행복을 느낍니다!
사용자 하이라이트
- 5월에 CNCF가 전 세계에 걸친 27 기관을 다양한 클라우드 네이티브 생태계의 신규 멤버로 받았습니다. 이 신규 멤버는 다가오는 KubeCon + CloudNativeCon NA in Los Angeles (October 12 – 15, 2021)를 포함한 CNCF 이벤트들에 참여할 것입니다.
- CNCF는 KubeCon + CloudNativeCon EU – Virtual 2021에서 Spotify에 최고 엔드 유저 상(Top End User Award)을 수여했습니다.
프로젝트 속도(Velocity)
CNCF K8s DevStats 프로젝트는 쿠버네티스와 다양한 서브-프로젝트에 대한 흥미로운 데이터를 수집하고 있습니다. 여기에는 개인 기여부터 기여하는 회사 수에 이르기까지 모든 것이 포함되며, 이 생태계를 발전시키는 데 필요한 노력의 깊이와 넓이를 보여줍니다.
우리는 15주(4월 26일에서 8월 4일) 간 진행된 v1.22 릴리스 주기에서, 1063개의 기업과 2054명의 개인의 기여를 보았습니다.
생태계 업데이트
- 세 번째 가상 이벤트인 KubeCon + CloudNativeCon Europe 2021이 5월에 열렸습니다. 모든 발표가 온디맨드로 확인 가능합니다.
- Spring Term LFX 프로그램이 28명의 성공적인 인턴을 배출한 최대 규모의 졸업반을 가졌습니다!
- CNCF가 연초에 클라우드 네이티브 커뮤니티와 함께 배우고, 성장하고, 협업하기를 원하는 전 세계 누구에게나 상호 작용형 미디어 경험을 제공하고자, Twitch에서 라이브스트리밍을 시작하였습니다.
이벤트 업데이트
- KubeCon + CloudNativeCon North America 2021가 October 12 – 15, 2021에 Los Angeles에서 열립니다! 컨퍼런스와 등록에 대한 더 자세한 정보는 이벤트 사이트에서 찾을 수 있습니다.
- 쿠버네티스 커뮤니티 Days가 Italy, UK, Washington DC에서 이벤트를 앞두고 있습니다.
다가오는 릴리스 웨비나
이번 릴리스에 대한 중요 기능뿐만 아니라 업그레이드 계획을 위해 필요한 사용 중지된 사항이나 제거에 대한 사항을 학습하고 싶다면, 2021년 10월 5일에 쿠버네티스 1.22 릴리스 팀 웨비나에 참여하세요. 더 자세한 정보와 등록에 대해서는 CNCF 온라인 프로그램 사이트의 이벤트 페이지를 확인하세요.
참여하기
만약 쿠버네티스 커뮤니티 기여에 관심이 있다면, 특별 관심 그룹(Special Interest Groups, SIGs)이 좋은 시작 지점이 될 수 있습니다. 그중 많은 SIG가 당신의 관심사와 일치될 수 있습니다! 만약 커뮤니티와 공유하고 싶은 것이 있다면, 주간 커뮤니티 미팅에 참석할 수 있습니다. 또한 다음 중 어떠한 채널이라도 활용할 수 있습니다.
- 쿠버네티스 기여자 웹사이트에서 기여에 대한 더 자세한 사항을 확인
- 최신 정보 업데이트를 위해 @Kubernetesio 트위터 팔로우
- 논의(discuss)에서 커뮤니티 논의에 참여
- 슬랙에서 커뮤니티에 참여
- 쿠버네티스 사용기 공유
- 쿠버네티스에서 일어나는 일에 대한 자세한 사항을 블로그를 통해 읽기
- 쿠버네티스 릴리스 팀에 대해 더 알아보기
당황하지 마세요. 쿠버네티스와 도커
업데이트: 쿠버네티스의 도커심을 통한 도커 지원이 제거되었습니다. 더 자세한 정보는 제거와 관련된 자주 묻는 질문을 참고하세요. 또는 지원 중단에 대한 GitHub 이슈에서 논의를 할 수도 있습니다.
저자: Jorge Castro, Duffie Cooley, Kat Cosgrove, Justin Garrison, Noah Kantrowitz, Bob Killen, Rey Lejano, Dan “POP” Papandrea, Jeffrey Sica, Davanum “Dims” Srinivas
번역: 박재화(삼성SDS), 손석호(한국전자통신연구원)
쿠버네티스는 v1.20 이후 컨테이너 런타임으로서 도커를 사용 중단(deprecating)합니다.
당황할 필요는 없습니다. 말처럼 극적이진 않습니다.
요약하자면, 기본(underlying) 런타임 중 하나인 도커는 쿠버네티스의 컨테이너 런타임 인터페이스(CRI)를 사용하는 런타임으로써는 더 이상 사용되지 않습니다(deprecated). 도커가 생성한 이미지는 늘 그래왔듯이 모든 런타임을 통해 클러스터에서 계속 작동될 것입니다.
쿠버네티스의 엔드유저에게는 많은 변화가 없을 것입니다.
이 내용은 도커의 끝을 의미하지 않으며, 도커를 더 이상 개발 도구로 사용할 수 없다거나,
사용하면 안 된다는 의미도 아닙니다. 도커는 여전히 컨테이너를
빌드하는 데 유용한 도구이며, docker build 실행 결과로 만들어진 이미지도 여전히 쿠버네티스 클러스터에서 동작합니다.
AKS, EKS 또는 GKE와 같은 관리형 쿠버네티스 서비스를 사용하는 경우 쿠버네티스의 향후 버전에서 도커에 대한 지원이 없어지기 전에, 워커 노드가 지원되는 컨테이너 런타임을 사용하고 있는지 확인해야 합니다. 노드에 사용자 정의가 적용된 경우 사용자 환경 및 런타임 요구 사항에 따라 업데이트가 필요할 수도 있습니다. 서비스 공급자와 협업하여 적절한 업그레이드 테스트 및 계획을 확인하세요.
자체 클러스터를 운영하는 경우에도, 클러스터의 고장을 피하기 위해서
변경을 수행해야 합니다. v1.20에서는 도커에 대한 지원 중단 경고(deprecation warning)가 표시됩니다.
도커 런타임 지원이 쿠버네티스의 향후 릴리스(현재는 2021년 하반기의
1.22 릴리스로 계획됨)에서 제거되면 더 이상 지원되지
않으며, containerd 또는 CRI-O와 같은 다른 호환 컨테이너 런타임 중
하나로 전환해야 합니다. 선택한 런타임이 현재 사용 중인
도커 데몬 구성(예: 로깅)을 지원하는지 확인하세요.
많은 사람들이 걱정하는 이유는 무엇이며, 왜 이런 혼란이 야기되었나요?
우리는 여기서 두 가지 다른 환경에 대해 이야기하고 있는데, 이것이 혼란을 야기하고 있습니다. 쿠버네티스 클러스터 내부에는 컨테이너 이미지를 가져오고 실행하는 역할을 하는 컨테이너 런타임이라는 것이 있습니다. 도커를 컨테이너 런타임(다른 일반적인 옵션에는 containerd 및 CRI-O가 있음)으로 많이 선택하지만, 도커는 쿠버네티스 내부에 포함(embedded)되도록 설계되지 않았기에 문제를 유발합니다.
우리가 "도커"라고 부르는 것은 실제로는 하나가 아닙니다. 도커는 전체 기술 스택이고, 그 중 한 부분은 그 자체로서 고수준(high-level)의 컨테이너 런타임인 "containerd" 입니다. 도커는 개발을 하는 동안 사람이 정말 쉽게 상호 작용할 수 있도록 많은 UX 개선을 포함하므로 도커는 멋지고 유용합니다. 하지만, 쿠버네티스는 사람이 아니기 때문에 이런 UX 개선 사항들이 필요하지 않습니다.
이 인간 친화적인 추상화 계층의 결과로, 쿠버네티스 클러스터는 containerd가 정말 필요로 하는 것들을 확보하기 위해서 도커심(Dockershim)이라는 다른 도구를 사용해야 합니다. 이것은 좋지 않습니다. 왜냐하면, 이는 추가적인 유지 관리를 필요로 하고 오류의 가능성도 높이기 때문입니다. 여기서 실제로 일어나는 일은 도커심이 빠르면 v1.23 릴리스에 Kubelet에서 제거되어, 결과적으로 도커에 대한 컨테이너 런타임으로서의 지원이 제거된다는 것입니다. 여러분 스스로도 생각할 수 있을 것입니다. containerd가 도커 스택에 포함되어 있는 것이라면, 도커심이 쿠버네티스에 왜 필요할까요?
도커는 컨테이너 런타임 인터페이스인 CRI를 준수하지 않습니다. 만약 이를 준수했다면, 심(shim)이 필요하지 않았을 것입니다. 그러나 이건 세상의 종말이 아니며, 당황할 필요도 없습니다. 여러분은 단지 컨테이너 런타임을 도커에서 지원되는 다른 컨테이너 런타임으로 변경하기만 하면 됩니다.
참고할 사항 한 가지: 현재 클러스터 내 워크플로의 일부가 기본 도커 소켓
(/var/run/docker.sock)에 의존하고 있는 경우, 다른
런타임으로 전환하는 것은 해당 워크플로의 사용에 문제를 일으킵니다. 이 패턴은 종종
도커 내의 도커라고 합니다. 이런 특정 유스케이스에 대해서
kaniko,
img와
buildah
같은 것들을 포함해 많은 옵션들이 있습니다.
그렇지만, 이 변경이 개발자에게는 어떤 의미인가요? 여전히 Dockerfile을 작성나요? 여전히 도커로 빌드하나요?
이 변경 사항은 사람들(folks)이 보통 도커와 상호 작용하는 데 사용하는 것과는 다른 환경을 제시합니다. 개발에 사용하는 도커의 설치는 쿠버네티스 클러스터 내의 도커 런타임과 관련이 없습니다. 혼란스럽죠, 우리도 알고 있습니다. 개발자에게 도커는 이 변경 사항이 발표되기 전과 마찬가지로 여전히 유용합니다. 도커가 생성하는 이미지는 실제로는 도커에만 특정된 이미지가 아니라 OCI(Open Container Initiative) 이미지입니다. 모든 OCI 호환 이미지는 해당 이미지를 빌드하는 데 사용하는 도구에 관계없이 쿠버네티스에서 동일하게 보입니다. containerd와 CRI-O는 모두 해당 이미지를 가져와 실행하는 방법을 알고 있습니다. 이것이 컨테이너가 어떤 모습이어야 하는지에 대한 표준이 있는 이유입니다.
변경은 다가오고 있습니다. 이 변경이 일부 문제를 일으킬 수도 있지만, 치명적이지는 않으며, 일반적으로는 괜찮은 일입니다. 사용자가 쿠버네티스와 상호 작용하는 방식에 따라 이 변경은 아무런 의미가 없거나 약간의 작업만을 의미할 수 있습니다. 장기적으로는 일이 더 쉬워질 것입니다. 이것이 여전히 혼란스럽더라도 괜찮습니다. 이에 대해서 많은 일이 진행되고 있습니다. 쿠버네티스에는 변화되는 부분이 많이 있고, 이에 대해 100% 전문가는 없습니다. 경험 수준이나 복잡성에 관계없이 어떤 질문이든 하시기 바랍니다! 우리의 목표는 모든 사람이 다가오는 변경 사항에 대해 최대한 많은 교육을 받을 수 있도록 하는 것입니다. 이 글이 여러분이 가지는 대부분의 질문에 대한 답이 되었고, 불안을 약간은 진정시켰기를 바랍니다! ❤️
더 많은 답변을 찾고 계신가요? 함께 제공되는 도커심 제거 FAQ(2022년 2월에 갱신됨)를 확인하세요.
쿠버네티스에서 어려움 없이 gRPC 로드밸런싱하기
저자: William Morgan (Buoyant)
번역: 송원석 (쏘카), 김상홍 (국민대), 손석호 (ETRI)
다수의 새로운 gRPC 사용자는 쿠버네티스의 기본 로드 밸런싱이 종종 작동하지 않는 것에 놀란다. 예를 들어, 만약 단순한 gRPC Node.js 마이크로서비스 앱을 만들고 쿠버네티스에 배포하면 어떤 일이 생기는지 살펴보자.
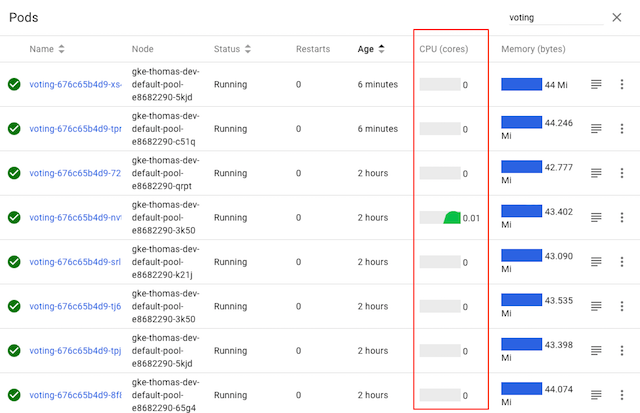
여기 표시된 voting 서비스는 여러 개의 파드로 구성되어 있지만, 쿠버네티스의 CPU 그래프는 명확하게
파드 중 하나만 실제 작업을 수행하고 있는 것(하나의 파드만 트래픽을 수신하고 있으므로)을
보여준다. 왜 그런 것일까?
이 블로그 게시물에서는, 이런 일이 발생하는 이유를 설명하고, CNCF의 서비스 메시(mesh)인 Linkerd 및 서비스 사이드카(sidecar)를 활용한 gRPC 로드밸런싱을 쿠버네티스 앱에 추가하여, 이 문제를 쉽게 해결할 수 있는 방법을 설명한다.
왜 gRPC에 특별한 로드밸런싱이 필요한가?
먼저, 왜 gRPC를 위해 특별한 작업이 필요한지 살펴보자.
gRPC는 애플리케이션 개발자에게 점점 더 일반적인 선택지가 되고 있다. JSON-over-HTTP와 같은 대체 프로토콜에 비해, gRPC는 극적으로 낮은 (역)직렬화 비용과, 자동 타입 체크, 공식화된 APIs, 적은 TCP 관리 오버헤드 등에 상당한 이점이 있다.
그러나, gRPC는 쿠버네티스에서 제공하는 것과 마찬가지로 표준(일반)적으로 사용되는 연결 수준 로드밸런싱(connection-level load balancing)을 어렵게 만드는 측면도 있다. gRPC는 HTTP/2로 구축되었고, HTTP/2는 하나의 오래 지속되는 TCP 연결을 갖도록 설계되있기 때문에, 모든 요청은 다중화(multiplexed)(특정 시점에 다수의 요청이 하나의 연결에서만 동작하는 것을 의미)된다. 일반적으로, 그것은 연결 관리 오버헤드를 줄이는 장점이 있다. 그러나, 그것은 또한 (상상할 수 있듯이) 연결 수준의 밸런싱(balancing)에는 유용하지 않다는 것을 의미한다. 일단 연결이 설정되면, 더 이상 밸런싱을 수행할 수 없기 때문이다. 모든 요청이 아래와 같이 단일 파드에 고정될 것이다.
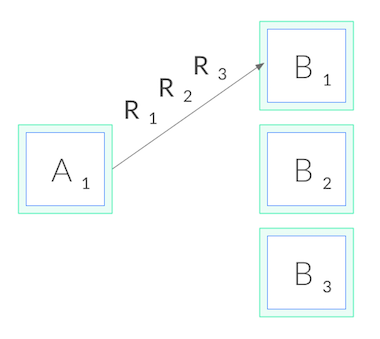
왜 HTTP/1.1에는 이러한 일이 발생하지 않는가?
HTTP/1.1 또한 수명이 긴 연결의 개념이 있지만, HTTP/1.1에는 TCP 연결을 순환시키게 만드는 여러 특징들이 있기 때문에, 이러한 문제가 발생하지 않는다. 그래서, 연결 수준 밸런싱은 "충분히 양호"하며, 대부분의 HTTP/1.1 앱에 대해서는 더 이상 아무것도 할 필요가 없다.
그 이유를 이해하기 위해, HTTP/1.1을 자세히 살펴보자. HTTP/2와 달리 HTTP/1.1은 요청을 다중화할 수 없다. TCP 연결 시점에 하나의 HTTP 요청만 활성화될 수 있다. 예를 들어 클라이언트가 'GET /foo'를 요청하고, 서버가 응답할 때까지 대기한다. 요청-응답 주기가 발생하면, 해당 연결에서 다른 요청을 실행할 수 없다.
일반적으로, 우리는 병렬로 많은 요청이 발생하기 원한다. 그러므로, HTTP/1.1 동시 요청을 위해, 여러 HTTP/1.1 연결을 만들어야 하고, 그 모두에 걸쳐 우리의 요청을 발행해야 한다. 또한, 수명이 긴 HTTP/1.1 연결은 일반적으로 일정 시간 후 만료되고 클라이언트(또는 서버)에 의해 끊어진다. 이 두 가지 요소를 결합하면 일반적으로 HTTP/1.1 요청이 여러 TCP 연결에서 순환하며, 연결 수준 밸런싱이 작동한다.
그래서 우리는 어떻게 gRPC의 부하를 분산할 수 있을까??
이제 gRPC로 돌아가보자. 연결 수준에서 밸런싱을 맞출 수 없기 때문에, gRPC 로드 밸런싱을 수행하려면, 연결 밸런싱에서 요청 밸런싱으로 전환해야 한다. 즉, 각각에 대한 HTTP/2 연결을 열어야 하고, 아래와 같이, 이러한 연결들로 요청의 밸런싱을 맞춘다.
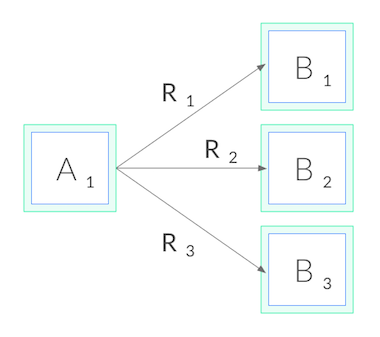
네트워크 측면에서, L3/L4에서 결정을 내리기 보다는 L5/L7에서 결정을 내려야 한다. 즉, TCP 연결을 통해 전송된 프로토콜을 이해해야 한다.
우리는 이것을 어떻게 달성해야할까? 몇 가지 옵션이 있다. 먼저, 우리의 애플리케이션 코드는 대상에 대한 자체 로드 밸런싱 풀을 수동으로 유지 관리할 수 있고, gRPC 클라이언트에 로드 밸런싱 풀을 사용하도록 구성할 수 있다. 이 접근 방식은 우리에게 높은 제어력을 제공하지만, 시간이 지남에 따라 파드가 리스케줄링(reschedule)되면서 풀이 변경되는 쿠버네티스와 같은 환경에서는 매우 복잡할 수 있다. 이 경우, 우리의 애플리케이션은 파드와 쿠버네티스 API를 관찰하고 자체적으로 최신 상태를 유지해야 한다.
대안으로, 쿠버네티스에서 앱을 헤드리스(headless) 서비스로 배포할 수 있다. 이 경우, 쿠버네티스는 서비스를 위한 DNS 항목에 다중 A 레코드를 생성할 것이다. 만약 충분히 진보한 gRPC 클라이언트를 사용한다면, 해당 DNS 항목에서 로드 밸런싱 풀을 자동으로 유지 관리할 수 있다. 그러나 이 접근 방식은 우리를 특정 gRPC 클라이언트로를 사용하도록 제한할 뿐만 아니라, 헤드리스 서비스만 사용하는 경우도 거의 없으므로 제약이 크다.
마지막으로, 세 번째 접근 방식을 취할 수 있다. 경량 프록시를 사용하는 것이다.
Linkerd를 사용하여 쿠버네티스에서 gRPC 로드 밸런싱
Linkerd는 CNCF에서 관리하는 쿠버네티스용 서비스 메시이다. 우리의 목적과 가장 관련이 깊은 Linkerd는, 클러스터 수준의 권한 없이도 단일 서비스에 적용할 수 있는 서비스 사이드카로써도 작동한다. Linkerd를 서비스에 추가하는 것은, 각 파드에 작고, 초고속인 프록시를 추가하는 것을 의미하며, 이러한 프록시가 쿠버네티스 API를 와치(watch)하고 gRPC 로드 밸런싱을 자동으로 수행하는 것을 의미이다. 우리가 수행한 배포는 다음과 같다.
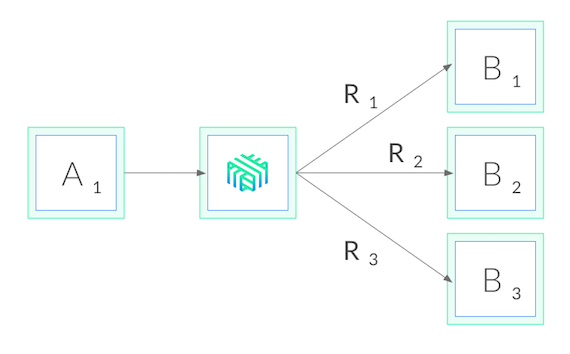
Linkerd를 사용하면 몇 가지 장점이 있다. 첫째, 어떠한 언어로 작성된 서비스든지, 어떤 gRPC 클라이언트든지 그리고 어떠한 배포 모델과도 (헤드리스 여부와 상관없이) 함께 작동한다. Linkerd의 프록시는 완전히 투명하기 때문에, HTTP/2와 HTTP/1.x를 자동으로 감지하고 L7 로드 밸런싱을 수행하며, 다른 모든 트래픽을 순수한 TCP로 통과(pass through)시킨다. 이것은 모든 것이 그냥 작동한다는 것을 의미한다.
둘째, Linkerd의 로드 밸런싱은 매우 정교하다. Linkerd는 쿠버네티스 API에 대한 와치(watch)를 유지하고 파드가 리스케술링 될 때 로드 밸런싱 풀을 자동으로 갱신할 뿐만 아니라, Linkerd는 응답 대기 시간이 가장 빠른 파드에 요청을 자동으로 보내기 위해 지수 가중 이동 평균(exponentially-weighted moving average) 을 사용한다. 하나의 파드가 잠시라도 느려지면, Linkerd가 트래픽을 변경할 것이다. 이를 통해 종단 간 지연 시간을 줄일 수 있다.
마지막으로, Linkerd의 Rust 기반 프록시는 매우 작고 빠르다. 그것은 1ms 미만의 p99 지연 시간(<1ms of p99 latency)을 지원할 뿐만 아니라, 파드당 10mb 미만의 RSS(<10mb of RSS)만 필요로 하므로 시스템 성능에도 거의 영향을 미치지 않는다.
60초 안에 gRPC 부하 분산
Linkerd는 시도하기가 매우 쉽다. 단지 —랩탑에 CLI를 설치하고— Linkerd 시작 지침의 단계만 따르면 된다. 클러스터에 컨트롤 플레인과 "메시" 서비스(프록시를 각 파드에 주입)를 설치한다. 서비스에 Linkerd가 즉시 실행될 것이므로 적절한 gRPC 밸런싱을 즉시 확인할 수 있다.
Linkerd 설치 후에, 예시 voting 서비스를
다시 살펴보자.
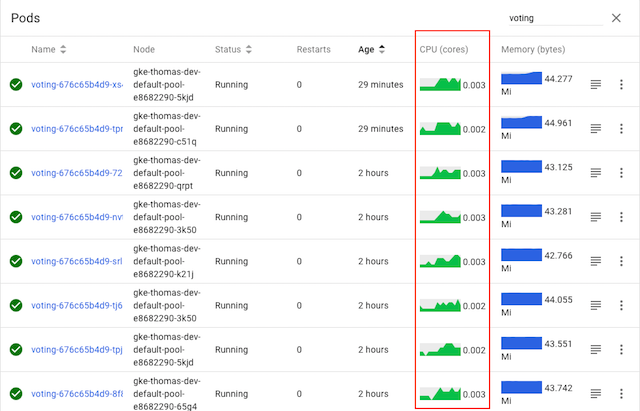
그림과 같이, 모든 파드에 대한 CPU 그래프가 활성화되어 모든 파드가 —코드를 변경하지 않았지만— 트래픽을 받고 있다. 짜잔, 마법처럼 gRPC 로드 밸런싱이 됐다!
Linkerd는 또한 내장된 트래픽 수준 대시보드를 제공하므로, 더 이상 CPU 차트에서 무슨 일이 일어나고 있는지 추측하는 것이 필요하지 않다. 다음은 각 파드의 성공률, 요청 볼륨 및 지연 시간 백분위수를 보여주는 Linkerd 그래프이다.
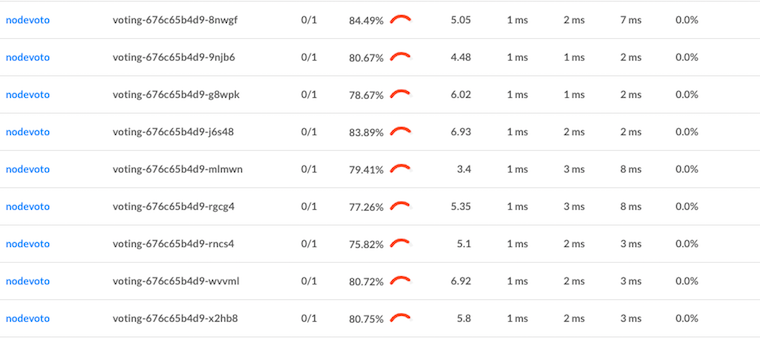
각 파드가 약 5 RPS를 얻고 있음을 알 수 있다. 또한, 로드 밸런싱 문제는 해결되었지만 해당 서비스의 성공률에 대해서는 아직 할 일이 남았다는 것도 살펴볼 수 있다. (데모 앱은 독자에 대한 연습을 위해 의도적으로 실패 상태로 만들었다. Linkerd 대시보드를 사용하여 문제를 해결할 수 있는지 살펴보자!)
마지막으로
쿠버네티스 서비스에 gRPC 로드 밸런싱을 추가하는 방법에 흥미가 있다면, 어떤 언어로 작성되었든 상관없이, 어떤 gRPC 클라이언트를 사용중이든지, 또는 어떻게 배포되었든지, Linkerd를 사용하여 단 몇 개의 명령으로 gRPC 로드 밸런싱을 추가할 수 있다.
보안, 안정성 및 디버깅을 포함하여 Linkerd에는 더 많은 특징 및 진단 기능이 있지만 이는 향후 블로그 게시물의 주제로 남겨두려 한다.
더 알고 싶은가? 빠르게 성장하고 있는 우리 커뮤니티는 여러분의 참여를 환영한다! Linkerd는 CNCF 프로젝트로 GitHub에 호스팅 되어 있고, Slack, Twitter, 그리고 이메일 리스트를 통해 커뮤니티를 만날 수 있다. 접속하여 커뮤니티에 참여하는 즐거움을 느껴보길 바란다!